
اگر تصور میکنید پایتورچ (PyTorch) تنها برای آموزش مدلهای زبانی است، باید نگاهی به زیرساخت جدید لینکدین (LinkedIn) بیندازید. این شرکت ثابت کرد که شتابدهندههای سختافزاری میتوانند مسائل کلاسیک بهینهسازی را در مقیاسی حل کنند که پیشتر غیرممکن پنداشته میشد.
همانطور که در بررسیهای پیشین ما دربارهی بهینهسازی مراکز داده اشاره کردیم، مدیریت متغیرها در مقیاس تریلیونی همواره یک گلوگاه سختافزاری بوده است. اپلیکیشنهای مدرن وب برای تصمیمگیریهای آنی در مورد تطبیق شغلی یا فرکانس ارسال ایمیل، به چیزی فراتر از پیشبینی نیاز دارند: آنها به تصمیمات بهینهسازی شده در لحظه نیاز دارند. طبق گزارش منتشرشده در ۱ ژوئن ۲۰۲۶، روشهای سنتی برنامهریزی خطی (Linear Programming) مانند روش سیمپلکس یا نقاط داخلی در این مقیاس شکست میخورند، زیرا تجزیه ماتریسها (Matrix Factorization) در آنها بیش از حد هزینهبر است.
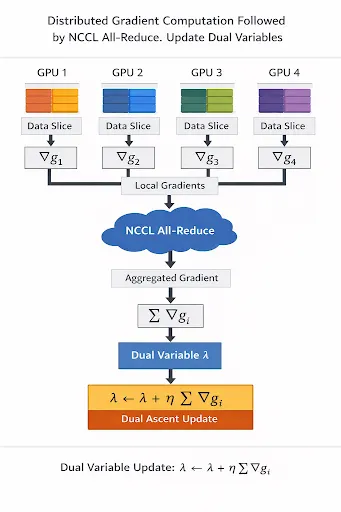
به نقل از مطالعه موردی PyTorch، لینکدین برای عبور از این بنبست، ابزاری به نام DuaLip-PyTorch توسعه داد که جایگزین پشته قدیمی Scala/Spark شد. این سیستم به جای تجزیههای گرانقیمت، از روشهای مرتبه اول نخست-دوگان (First-order Primal-Dual methods) استفاده میکند که بر پایه اطلاعات گرادینت و ضرب ماتریس-بردار عمل میکنند.
جزئیات فنی این پیادهسازی عبارتند از:
- استفاده از عملیات تنسورهای پراکنده (Sparse Tensors) برای مدیریت میلیاردها تا تریلیونها متغیر.
- استفاده از کرنلهای تصویرسازی دستهای (Batched Projection Kernels) و همگامسازی توزیعشده از طریق الگوهای all-reduce و broadcast.
- بهرهگیری از شتابدهندههای همگرایی شامل گونههای AGD و FISTA.

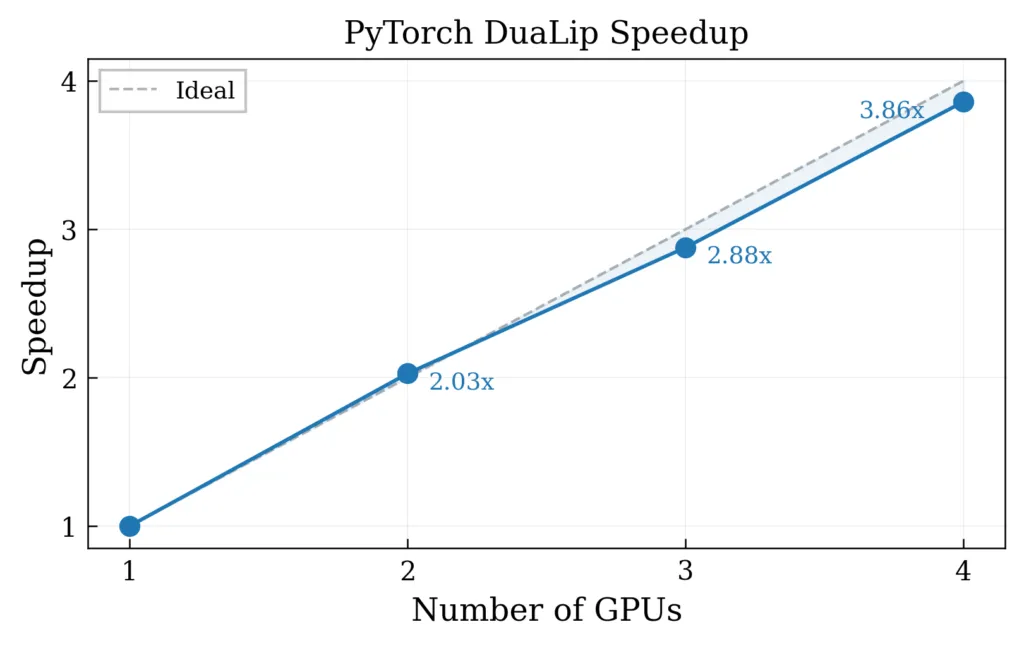
این تغییر معماری منجر به افزایش ۷۵ برابری سرعت اجرای هر تکرار (Iteration) در مقایسه با پیادهسازیهای مبتنی بر CPU شد.
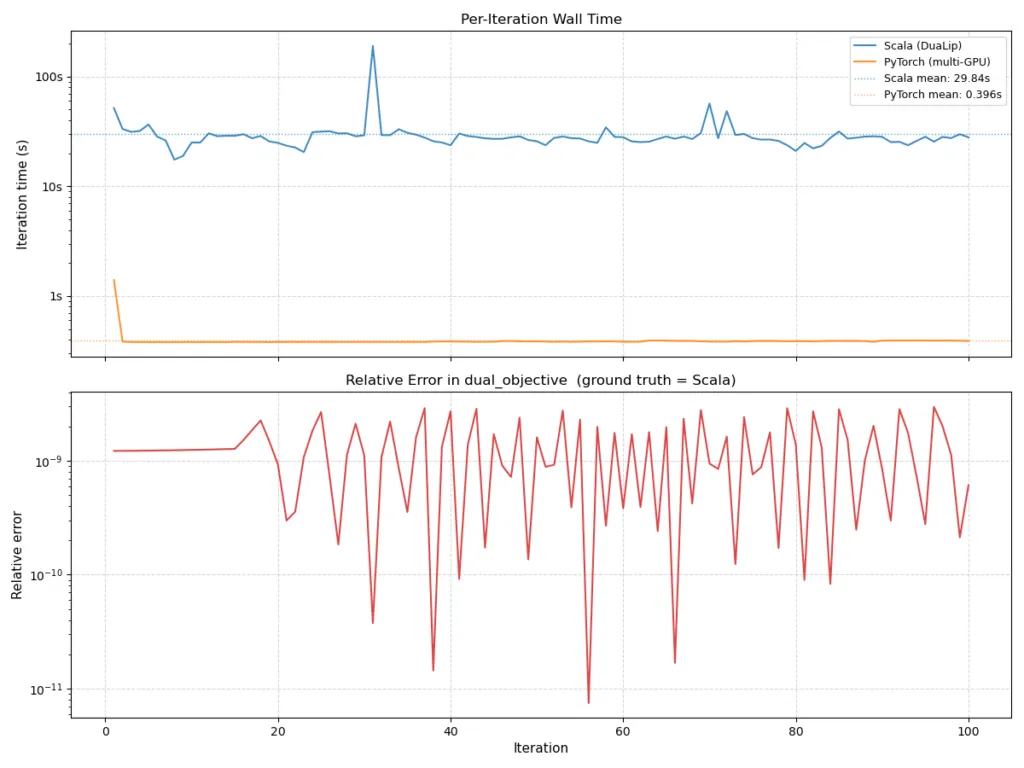
از دیدگاه مهندسی، این گذار فرضیه قدیمی مبنی بر «صرفاً یادگیری عمیق بودن» PyTorch را میشکند. لینکدین با مدلسازی ساختاری یک حلکننده بهینهسازی بهصورت یک شبکه عصبی — با استفاده از انتزاعهای تنسوری و کرنلهای GPU — شکاف بین یادگیری ماشین و بهینهسازی کلاسیک را پر کرده است. این امر هزینه استقرار محدودیتهای پیچیده جدید در محیط عملیاتی را بهشدت کاهش میدهد.
گام بعدی شما
- بررسی جزئیات فنی کامل در گزارش DuaLip-GPU در وبسایت arXiv.
- تحلیل پیادهسازی متنباز این سیستم در مخازن GitHub.
- ارزیابی جایگزینی روشهای تجزیه ماتریس با روشهای مرتبه اول در سیستمهای بهینهسازی داخلی خود.
اما این تنها بخشی از تحول در زیرساختهای پردازشی است؛ تحلیل ما دربارهی اثر این تغییر بر هزینه عملیاتی مراکز داده را دنبال کنید.



گفتگو