
تصور کنید یک خطای کوچک در درایور یا یک نقص سختافزاری نامحسوس در یک خوشه عظیم GPU، باعث توقف کامل هفتهها آموزش یک مدل شود. شما باید بدانید که در مقیاس هزاران پردازنده، مدیریت سختافزارهای ناهمگون و بارهای کاری متغیر، به یک کابوس نظارتی تبدیل میشود.
انویدیا (NVIDIA) برای حل این چالش، در ۱۱ می ۲۰۲۶ سرویس Fleet Intelligence را بهطور عمومی عرضه کرد. این ابزار یک لایه مدیریتی برای پایش مستمر شتابدهندههای مرکز داده است. برای درک بهتر، تلهمتری (Telemetry) — تشبیه روزمره: مثل یک مانیتور سلامت دیجیتال که هر ضربان قلب سختافزار را گزارش میدهد — در این سرویس به جای نظارت ساده بر «روشن یا خاموش بودن» گره خورده و دیدگاهی دقیق از عملکرد به ازای هر وات و سلامت حرارتی ارائه میدهد.
همانطور که در تحلیل قبلی ما دربارهی زیرساختهای محاسباتی مدلهای زبانی اشاره کردیم، بهینهسازی بازگشت سرمایه (ROI) در رقابت فعلی زیرساختهای هوش مصنوعی، تنها با حذف نقاط کور عملیاتی ممکن است. طبق گزارش وبسایت developer.nvidia.com، این سرویس از یک عامل (Agent) متنباز با اثر حداقلی بر سیستم استفاده میکند که دادهها را به یک سرویس ابری مدیریتشده ارسال میکند.
جزئیات فنی این پلتفرم شامل موارد زیر است:
- بصریسازی موجودی: داشبوردهای جهانی برای بررسی میزان بهرهبرداری از GPU و حافظه در مناطق مختلف محاسباتی.
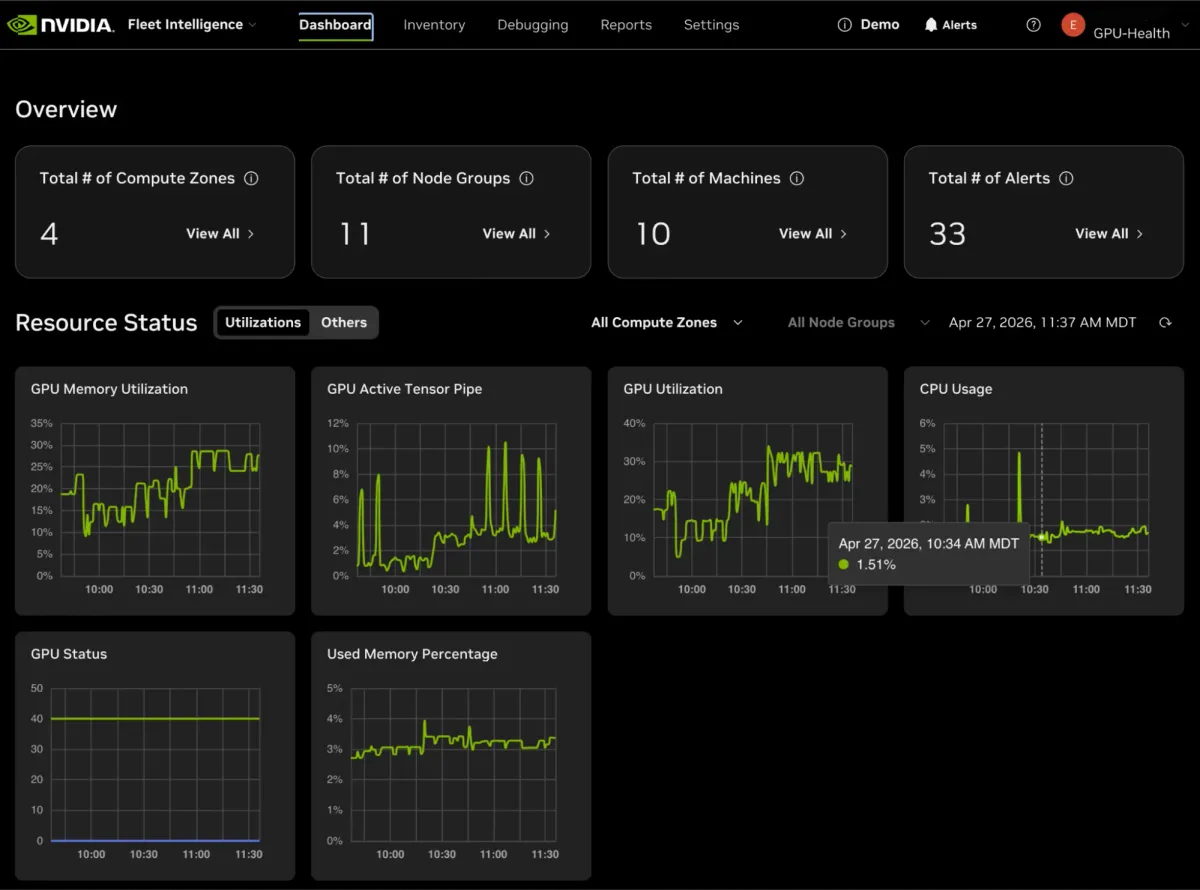
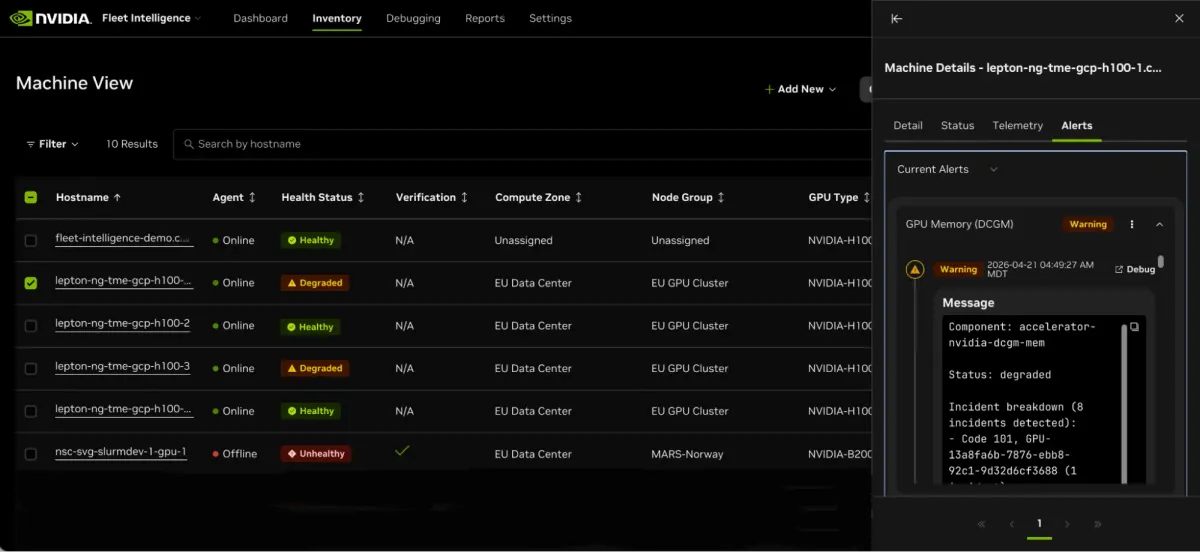
- پایش سلامت: ردیابی لحظهای توان، دما و خطاهای ECC/XID (خطاهای تصحیح کد) از طریق ابزارهای DCGM و GPUd برای شناسایی افت عملکرد پیش از وقوع خرابی.
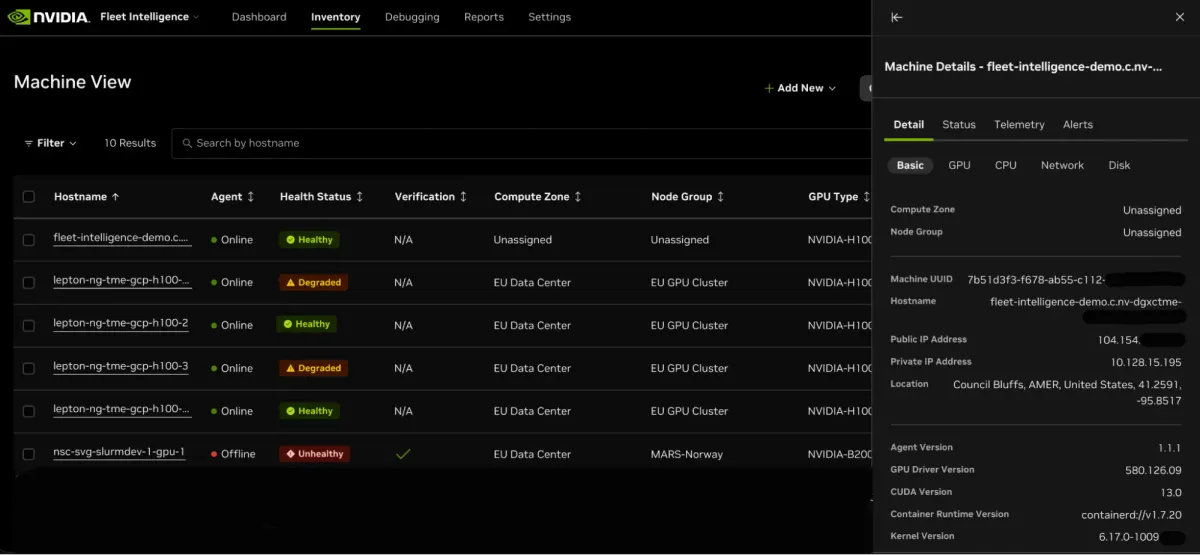
- تأیید اصالت و یکپارچگی: استفاده از Attestation SDK و سرویس NRAS برای تأیید رمزنگاریشدهی سفتافزارها (Firmware) تا اطمینان حاصل شود که سختافزار دستکاری نشده است.
- پشتیبانی: سازگاری با معماریهای Hopper، Blackwell و Vera Rubin (البته تأیید اصالت تنها در دو معماری اخیر فعال است).
به نظر ما، متنباز کردن این عامل، تلاشی از سوی انویدیا برای ایجاد اعتماد در خط لوله دادههاست، در حالی که همزمان کاربران را عمیقتر در اکوسیستم خود محبوس میکند. این چرخش به سمت «دستهبندی پیشبینانه خرابیها»، یعنی انتقال از تعمیرات واکنشی به ارکستراسیون زیرساختی مبتنی بر هوش مصنوعی.
گام بعدی شما
- مالکان GPUهای مرکز داده انویدیا و مستأجران ابری میتوانند هماکنون درخواست دسترسی رایگان به این سرویس را ارسال کنند.
- برای مدیران زیرساخت، اولویتبندی جایگزینی ماژولهای HBM در زمانهای توقف برنامهریزیشده (Downtime) جایگزین شناسایی خرابی در حین آموزش مدل خواهد شد.
- منتظر انتشار مدلهای پیشبینانه باشید که سیگنالهای تلهمتری را مستقیماً به دستورات خودکار جایگزینی سختافزار تبدیل میکنند.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو