
تصور کنید پژوهشی را میخوانید که با اطمینان کامل به منابع متعددی استناد میکند، اما نیمی از آن منابع هرگز نوشته نشدهاند. این کابوس فعلی دنیای آکادمیک است؛ جایی که سرعت تولید محتوا با هوش مصنوعی، دقتِ بررسیها را میبلعد.
طبق گزارش منتشرشده در PubMed، نرخ ارجاعات جعلی در مقالات این پایگاه داده از ۱ مورد در هر ۲۸۲۸ مقاله در سال ۲۰۲۳، به ۱ مورد در هر ۲۷۷ مقاله تا اوایل سال ۲۰۲۶ رسیده است. این رشد ۱۲ برابری مستقیماً از استفاده پژوهشگران از مدلهای زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — برای تولید فهرست منابع (Bibliography) نشأت میگیرد؛ فهرستهایی که کاملاً واقعی به نظر میرسند اما در واقع ساخته و پرداختهی هوش مصنوعی زاینده (Generative AI) هستند.
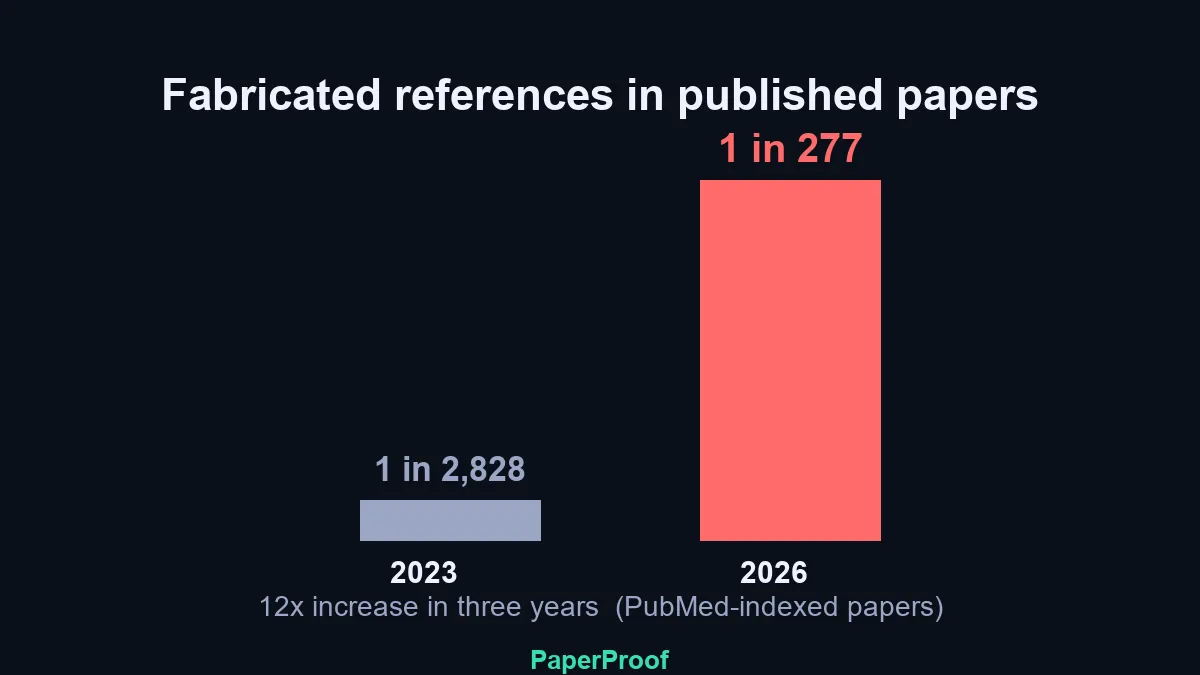
این وضعیت در حالی رخ میدهد که ناشران علمی با تضاد شدیدی میان کارایی AI و سلامت دادهها دستوپنجه نرم میکنند. همانطور که در تحلیلهای پیشین ما دربارهی توهمات مدلهای زبانی اشاره کردیم، مشکل دیگر فقط اشتباهات پراکنده نیست، بلکه یک شکست سیستماتیک در فرآیند داوری (Peer-review) است. این وضعیت شبیه نقشهای است که ظاهرش بینقص است، اما شما را به شهرهایی میبرد که اصلاً وجود ندارند.
به نقل از گزارشی در dev.to، خطاهای ارجاع اکنون به دو دسته کلی تقسیم میشوند:
- خطاهای وجودی (Existence Errors): مدل یک عنوان، نویسنده و کد DOI جعلی میسازد. این موارد بهراحتی توسط ابزارهای خودکار مثل CiteTrue، SwanRef و Citely شناسایی میشوند؛ چراکه این ابزارها متادادهها را در چند ثانیه با پایگاههای CrossRef، PubMed و OpenAlex تطبیق میدهند. برای آشنایی بیشتر با متدهای سریع بررسی این موارد، میتوانید راهنمای شناسایی ارجاعات جعلی در متون هوش مصنوعی را مطالعه کنید.
- خطاهای پشتیبانی (Support Errors): مدل به مقالهای ارجاع میدهد که واقعاً وجود دارد، اما آن را برای اثبات ادعایی به کار میبرد که نویسندگان اصلی مقاله هرگز مطرح نکردهاند.
بر اساس مستندات موجود، در حال حاضر تنها راه حل قابل اعتماد برای خطاهای پشتیبانی، تأیید دستی است. استاندارد طلایی برای پژوهشگران این است که عنوانها را در Google Scholar جستوجو کنند، کدهای DOI را در doi.org بررسی نمایند و دقیقاً همان خطی از متن منبع را پیدا کنند که ادعا را توجیه میکند.
این تغییر روند نشاندهنده یک «شکاف پاسخگویی» است؛ جایی که پژوهشگران صحتِ متاداده را با حقیقتِ محتوایی اشتباه میگیرند. با اتوماسیون بررسی اول، بررسی دوم — یعنی حسابرسی فکری — به نقطه شکست اصلی و رایجترین دلیل بازپسگیری (Retraction) مقالات تبدیل شده است. در مقابل، برخی از پژوهشگران برای افزایش شفافیت، به سمت استانداردهای جدیدی حرکت کردهاند؛ چنانکه گزارش arXiv نشان میدهد اشتراکگذاری کد و داده در مقالات AI به شدت افزایش یافته است تا امکان اعتبارسنجی دقیقتر فراهم شود.
برای جلوگیری از حذف مقاله، کاربران باید هر منبع کلیدی را باز کنند. اگر هیچ جملهی مشخصی در متن منبع، ادعای نویسنده را تأیید نمیکرد، ارجاع باید حذف شود، حتی اگر خودِ مقاله وجود خارجی داشته باشد.
گام بعدی شما
- هر ارجاعی که توسط AI پیشنهاد شده را با باز کردن لینک مستقیم منبع (نه فقط بررسی عنوان) تأیید کنید.
- از ابزارهای متاداده مانند CiteTrue برای شناسایی سریع منابع جعلی استفاده کنید.
- در متون علمی، «اعتبار منبع» را با «صحت استدلال» اشتباه نگیرید.
اما بررسی این موضوع که چگونه مدلهای استدلالی جدید ممکن است این توهمات را کاهش دهند، در گزارش بعدی ما جای میگیرد.
گفتگو