
آیا تاریخچه جستوجوهای خصوصی و فایلهای آپلودشده شما اکنون به سوخت مدلهای هوش مصنوعی گوگل تبدیل شده است؟ طبق گزارشی از Wired در ۲۴ ژوئن ۲۰۲۶، این شرکت در حال عرضه جهانی ویژگی جدیدی به نام «تاریخچه خدمات جستوجو» (Search Services History) است. این قابلیت، نحوه مدیریت دادههای کاربر را بهصورت پیشفرض تغییر میدهد تا دسترسی گوگل به اطلاعات شخصی گستردهتر شود.
زمینه
این اقدام در حالی صورت میگیرد که گوگل بهطور تهاجمی در حال گسترش قابلیتهای چندوجهی (Multimodal) خود است؛ یعنی مدلهایی که میتوانند همزمان متن، تصویر و صدا را درک و تحلیل کنند. این حرکت در راستای روند عمیقتر کردن یکپارچگی اکوسیستم شرکت است؛ مشابه آنطور که Google Wallet اخیراً پشتیبانی از TSA PreCheck را برای ۱۰۰ خط هوایی گسترش داد تا خدمات خود را با زیرساختهای خارجی گره بزند. این بهروزرسانی تضمین میکند که گوگل جریان ثابتی از دادههای متنوع را در اختیار داشته باشد تا بتواند در رقابت تنگاتنگ با سایر آزمایشگاههای پیشرو در زمینه هوش مصنوعی، جایگاه خود را حفظ کند.
مدلهای هوش مصنوعی برای بهبود عملکرد و تکامل، به چیزی فراتر از متنهای ساده نیاز دارند. گوگل برای اینکه سریعتر از رقبای خود نوآوری کند، به ورودیهای متنوع در فرمتهای مختلف (صوتی، تصویری و متنی) نیاز مبرم دارد. با بهرهگیری از پایگاه کاربران عظیم خود در سرویسهای مختلف، گوگل برتری ویژهای در جمعآوری دادهها به دست آورده است؛ مزیتی که سایر شرکتهای هوش مصنوعی نمیتوانند بهراحتی آن را بازسازی یا تقلید کنند، زیرا دسترسی به چنین حجم عظیمی از تعاملات انسانی واقعی را ندارند. این رویکرد مشابه استراتژیهای رقبای دیگر است، برای مثال متا نیز از گفتگوهای گروههای فیسبوک برای غنیسازی پاسخهای AI Mode خود استفاده میکند.
جزئیات
سامانه جدید گوگل بسیار فراتر از ذخیره متون ساده عمل میکند. گوگل اکنون تصاویر، فایلها و ضبطهای صوتی یا ویدئویی را از تعاملات مختلف کاربران ذخیره میکند. این دادههای جمعآوری شده شامل موارد زیر است:
- فایلهای آپلودشده از طریق گوگل لنز (Google Lens)
- ضبطهای صوتی و تعاملات در Search Live
- تمرینهای گفتاری و ورودیهای صوتی در گوگل ترنسلیت (Google Translate)
- هرگونه محتوای دیگر که از طریق خدمات مختلف جستوجوی گوگل آپلود شود
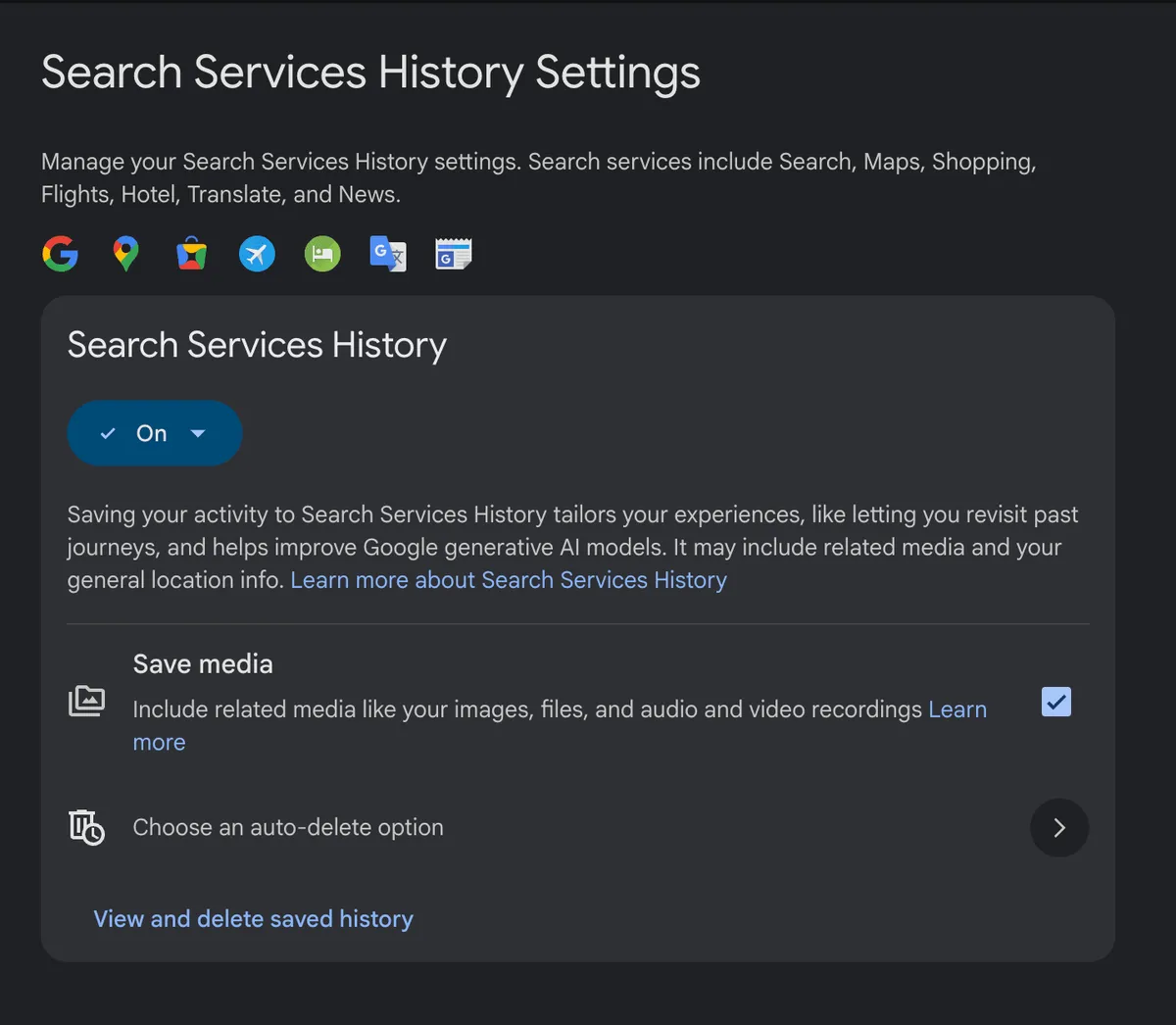
نکته حیاتی و نگرانکننده این است که این تنظیمات برای اکثر کاربران بهصورت پیشفرض فعال (Enabled) است. بررسیها نشان میدهد وقتی کاربران برای اولین بار از این صفحه بازدید میکنند، گزینه Search Services History از پیش فعال شده است. همچنین تیک مربوط به ذخیره تمام رسانههای آپلودشده برای آموزش هوش مصنوعی زاینده (Generative AI) — شبیه به یک آشپزخانه صنعتی که هر ماده اولیه را برای یادگیری دستور پخت جدید میبلعد — بهصورت پیشفرض زده شده بود. تنها استثنا در این مورد، کاربرانی هستند که پیشتر تنظیمات Web & App Activity و Search Personalization را بهطور کامل غیرفعال کرده بودند.
برای خروج از این سیستم (Opt-out)، کاربر باید مسیر پیچیدهای را طی کند؛ ابتدا باید به صفحه My Activity برود و سپس تب Search Services History را پیدا و انتخاب کند. در آنجا باید بهطور مشخص تیک گزینه «Save media» را بردارد تا از استفاده از تصاویر و رسانههایش برای آموزش مدلها جلوگیری کند. این صفحه در حال حاضر تنها جایی است که کاربر میتواند این تنظیم را تغییر داده یا فعالیتهای ثبت شده خود را پاک کند.
زمانبندی برای کسانی که به حریم خصوصی اهمیت میدهند، بسیار حیاتی است. بر اساس مستندات، وقتی رسانهها «به مخلوطکن AI» thrown میشوند، ارتباط آنها با حساب گوگل کاربر قطع میشود. یک هشدار پاپ-آپ در گوگل تأیید میکند که این دادههای آموزشی تا ۴ سال نگه داشته میشوند؛ این یعنی حتی اگر کاربر فعالیت اصلی خود را پاک کند، نسخهای که برای آموزش مدل استفاده شده است تا سالها باقی میماند. تکیه بر چنین دادههای قدیمی میتواند چالشبرانگیز باشد، همانطور که در مدل Gemini 3.5 Flash مشاهده شد که دادههای قدیمی گاهی بر واقعیتهای لحظهای غلبه میکنند.
دیویس تامپسون، سخنگوی گوگل، در گفتگو با Wired بیان کرد که این تنظیمات به کاربران کمک میکند نتایجی مرتبطتر دریافت کنند و بتوانند جستوجوهای گذشته خود را بازبینی نمایند. او تأیید کرد که کاربران میتوانند هر زمان که بخواهند این گزینهها را فعال یا غیرفعال کنند. با این حال، او هیچ توضیحی در مورد این دلیل ارائه نکرد که چرا این ویژگی بهجای سیستم «درخواست موافقت» (Opt-in)، بهصورت پیشفرض فعال شده است تا کاربران مجبور به غیرفعال کردن آن باشند.
استراتژی شرکتی
گوگل در ایمیلی که در ۲۳ ژوئن ۲۰۲۶ برای حسابهای تست ارسال کرد، این تغییر را با ادبیاتی تبلیغاتی به عنوان اعطای «کنترل بیشتر کاربر بر تاریخچه ذخیره شده» معرفی کرد. در این پیام به مزایایی مانند امکان ادامه یک مکالمه Search Live درباره یک آهنگ یا بازبینی جستوجوهای قبلی در گوگل لنز اشاره شد. نکته قابل توجه و بحثبرانگیز این است که گوگل در حالی که مزایای دسترسی به تاریخچه را شرح داد، هیچ مثال مشابهی از مزایای مستقیم برای کاربر ارائه نکرد که چرا رسانههای ذخیره شده باید برای آموزش مدلهای هوش مصنوعی شرکت استفاده شوند.
ثورین کلوسوفسکی از بنیاد مرزهای الکترونیکی (EFF) استدلال میکند که گوگل بر «اینرسی درونی» (built-in inertia) کاربران تکیه کرده است؛ به این معنا که چون مردم با طیف گسترده خدمات گوگل راحت هستند و به آنها وابسته شدهاند، حتی زمانی که شرایط حریم خصوصی تضعیف میشود، احتمال کمتری دارد که پلتفرم خود را عوض کنند. کلوسوفسکی معتقد است درخواست صریح از کاربر برای انتخاب و فعالسازی این ویژگیها از طریق یک سیستم Opt-in، حداقلترین استانداردی است که این شرکتهای غولپیکر باید رعایت کنند.
این رویکرد باعث ایجاد یک تغییر بنیادین در توازن قدرت مالکیت دادهها میشود. گوگل با مجبور کردن کاربران به یافتن دکمههای پنهان و تنظیمات پیچیده برای محافظت از دادههایشان، در واقع تمام بار مسئولیت حفظ حریم خصوصی را بر دوش مصرفکننده میاندازد و خود را از هرگونه مسئولیت پیشفرض تبرئه میکند.
بن وینترز، مدیر حریم خصوصی در فدراسیون مصرفکنندگان آمریکا، میگوید این رویکرد منجر به نوعی «خستگی کاربر» (user exhaustion) میشود. او اشاره میکند که این وضعیت مصرفکنندگان را مجبور میکند یک «لایه محاسباتی اضافی» (extra layer of math) درباره میزان راحتی و اعتمادشان به ابزارهایی که سالها استفاده کردهاند انجام دهند. این امر منجر به ایجاد حس درماندگی و ناامیدی میشود، زیرا کاربران احساس میکنند هر تکه دادهای، هر چقدر هم کوچک، از آنها استخراج و عصر شده است تا منافع تجاری شرکت تأمین شود.
از نظر عملی، این بدان معناست که آپلودهای تصادفی تصاویر یا یادداشتهای صوتی شما دیگر موقتی و گذرا نیستند. آنها به بخشی دائمی از یک مجموعه آموزشی (Training Set) برای سالها تبدیل میشوند، فارغ از اینکه شما حساب خود را پاک کنید یا خیر؛ دادهها پس از جداسازی از حساب، در حافظه مدل باقی میمانند.
برای کاربر عادی، این یک یادآور جدی است که «راحتی» و خدمات رایگان اغلب به قیمت «ماندگاری ابدی دادهها» تمام میشود. ابزارهای روزمره ما در حال تبدیل شدن به موتورهای عظیم برداشت داده برای نسل بعدی مدلهای زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن جواب میدهد — هستند.
اگر به حریم خصوصی دادههای خود اهمیت میدهید، همین امروز تنظیمات خود را بررسی کنید. پنجره فرصت برای جلوگیری از ورود رسانههای شما به خط لوله آموزش مدلها بسیار کوچک است، بهخصوص زمانی که این عرضه به حساب خاص شما برسد و دادهها پردازش شوند.
در آینده باید منتظر واکنشهای رگولاتوری اتحادیه اروپا یا آمریکا درباره «الگوهای تاریک» (Dark Patterns) در این مسیرهای خروج (opt-out flows) باشید. صنعت تکنولوژی در حال حرکت به سمت استانداردی است که در آن وضعیت پیشفرض کاربر، دیگر «صاحب داده» نیست، بلکه «اهداکننده داده» است.
گام بعدی شما
- همین حالا به صفحه My Activity گوگل بروید و وضعیت Search Services History را بررسی کنید.
- تیک گزینه «Save media» را برای جلوگیری از آموزش مدلها با تصاویر و فایلهای شخصی خود بردارید.
- در صورت نیاز، تاریخچههای قدیمی را پاک کنید، اما به یاد داشته باشید دادههای آموزشی قبلاً استخراج شده ممکن است تا ۴ سال باقی بمانند.



گفتگو