
اگر تحلیلگر کسبوکار هستید یا روزنامهنگار داده، میدانید که کلنجار رفتن با جداول اکسل برای رسیدن به یک داستان بصری و صیقلخورده، معمولاً روزها کار دستی برای رسم نمودارها و بازبینی واقعیتها (fact-checking) زمان میبرد. این گردشکار با ظهور Data2Story بهکلی تغییر میکند؛ سیستمی که کل خط لوله تولید، از یک فایل CSV خام تا یک مقاله وب تعاملی، تأییدشده و نهایی را بهطور کامل خودکار میکند. 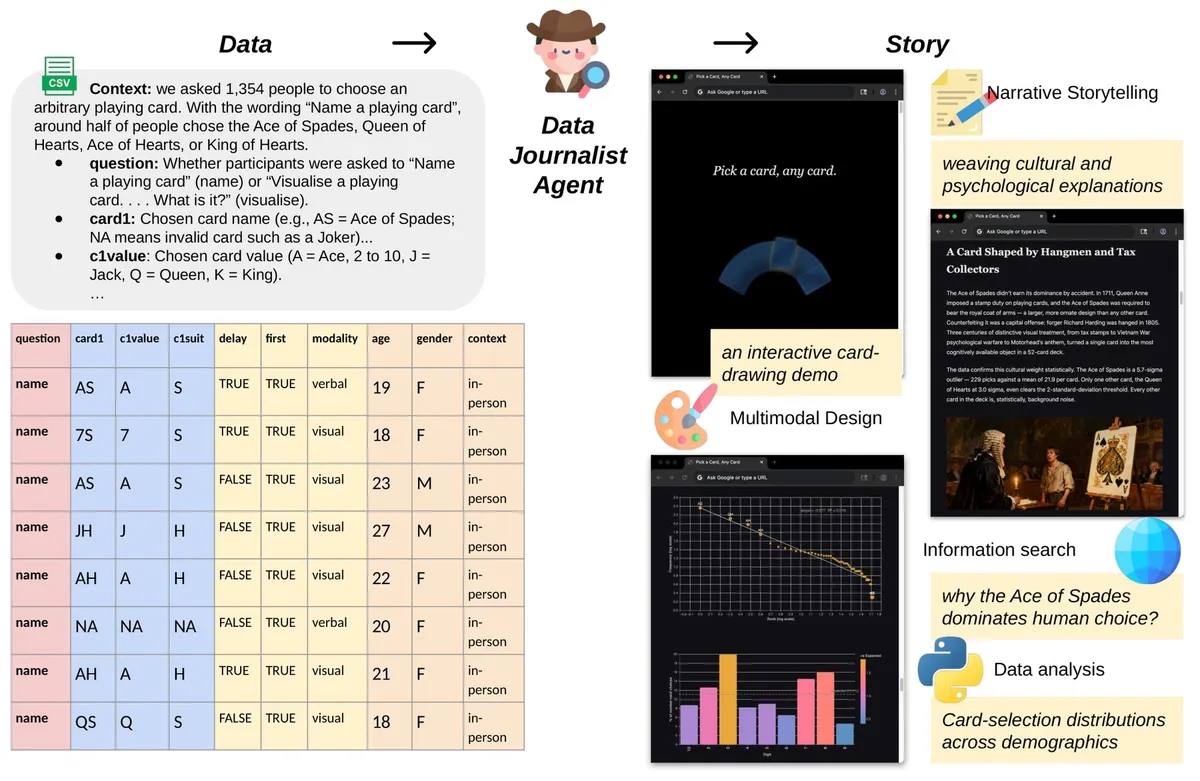
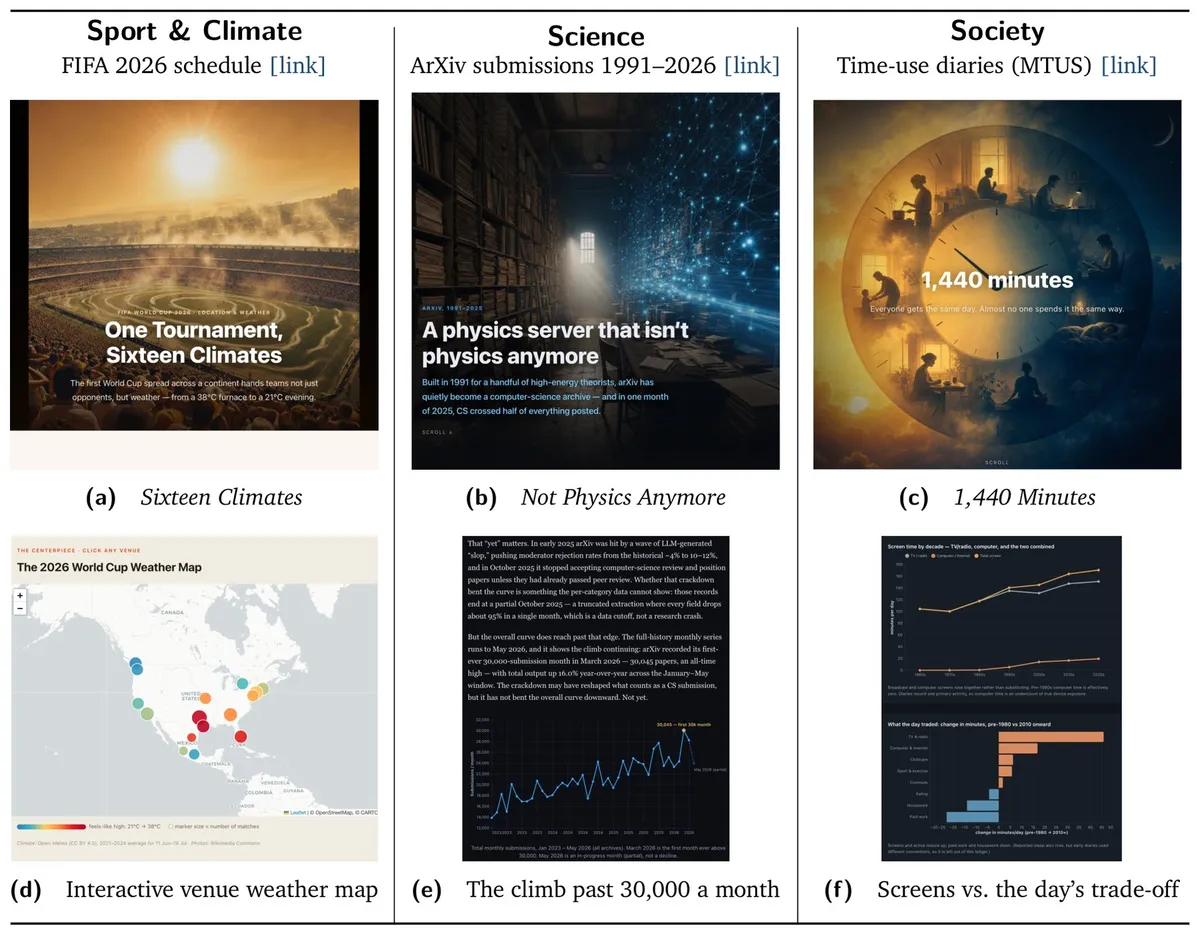
این سامانه بهگونهای طراحی شده است تا مجموعهدادههای خام را بدون هیچگونه دخالت انسانی به مقالات وب چندوجهی (Multimodal) تبدیل کند. Data2Story قادر است درباره موضوعات بسیار متنوعی داستان بنویسد؛ از تحلیل نحوه گذراندن روزمره مردم گرفته تا بررسی روندهای مقالات در ArXiv. این قابلیت تحلیل متون علمی در زمانی توسعه مییابد که اشتراکگذاری کد و داده در مقالات هوش مصنوعی در arXiv رشد چشمگیری داشته است و دسترسی به منابع خام را تسهیل کرده است. یکی از دموهای اصلی این سیستم بر روی جدول زمانبندی جام جهانی ۲۰۲۶ فیفا تمرکز دارد. سیستم با تحلیل شهرهای میزبان و برنامهزمانبندی مسابقات، مقالهای با محوریت اقلیم و یک نقشه تعاملی تولید کرد. یکی از یافتههای کلیدی در این گزارش این است که حدود ۴ از هر ۱۰ مسابقه در مکانهایی برنامهریزی شدهاند که اتحادیه بازیکنان (FIFPRO) آنها را در گروه «ریسک گرمای بسیار بالا» طبقهبندی کرده است. سیستم همچنین اشاره میکند که رطوبت، و نه دمای هوا، محرک اصلی این ریسک است؛ هرچود نویسندگان تأکید میکنند که اینها شرایط اقلیمی معمول آن مناطق هستند و پیشبینی خاصی برای دوره برگزاری تورنمنت محسوب نمیشوند.
این پیشرفت در لحظهای حیاتی برای اعتماد به هوش مصنوعی رخ میدهد. مدلهای زبانی بزرگ (LLM) فعلی بهکرات از «توهم ارجاع» (attribution hallucination) رنج میبرند؛ وضعیتی که در آن مدل پاسخ درست را ارائه میدهد اما منبعی را ذکر میکند که اصلاً وجود خارجی ندارد. طبق گزارشی از دانشگاه پکن، مدلهای پیشرو اغلب در این آزمون پایه «مبنایابی» (grounding) شکست میخورند. مطالعه دیگری نشان میدهد که عوامل جستوجوی AI اغلب اصلاً تحقیق نمیکنند و در عوض، بیشتر آنچه را که از طریق دادههای آموزشی خود میدانند، تأیید میکنند. Data2Story تلاش میکند این مشکل را با تغییری بنیادین حل کند: به جای اینکه با AI به عنوان یک «نویسنده» برخورد کند، آن را به عنوان یک «تحریریه هماهنگ» میبیند.
مکانیسم تحریریه مجازی
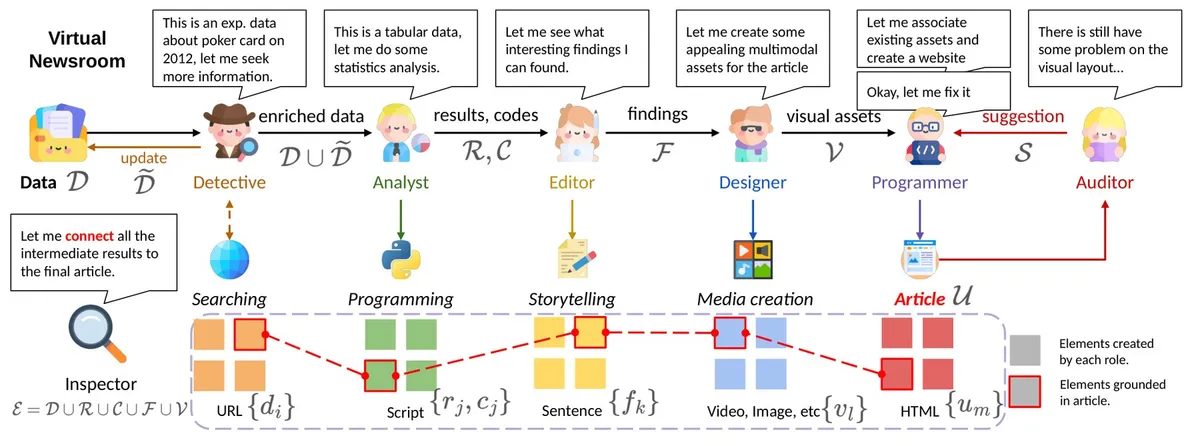
این سیستم بر پایه زنجیرهای از ۷ عامل (Agent) تخصصی کار میکند که در قالب یک «تحریریه مجازی» عمل میکنند. این جریان کاری تحریریه، مسیری ساختارمند از مرحله تحقیق تا صفحهآرایی نهایی را تضمین میکند:
- کارآگاه (Detective): برای یافتن زمینه (Context) در وب جستوجو میکند؛ زیرا جدولهای خام بهندرت کل داستان را روایت میکنند. برای دادههای جام جهانی، کارآگاه توانست شهرهای میزبان را به دادههای اقلیمی Open-Meteo و رتبهبندی ریسک گرمای FIFPRO متصل کند.
- تحلیلگر (Analyst): بهجای حدس زدن اعداد، کد مینویسد و آن را اجرا میکند تا ارقام دقیق بهصورت محاسباتی استخراج شوند.
- ویراستار (Editor): تصمیم میگیرد که کدام یافتههای خاص باید روایت کلی داستان را پیش ببرند.
- طراح (Designer): رسانه مناسب برای نمایش دادهها را انتخاب میکند؛ مثلاً استفاده از نقشه برای دادههای جغرافیایی یا کلیپ صوتی برای موضوعات موسیقی.
- برنامهنویس (Programmer): صفحه HTML واقعی و نهایی را پیادهسازی و کدنویسی میکند.
- حسابرس (Auditor): چیدمان نهایی را برای یافتن هرگونه خطای بصری یا ساختاری بررسی میکند.
- بازرس (Inspector): هر المان موجود در مقاله را به منبع اصلیاش بازمیگرداند و گره میزند.
اجرای فنی توسط «بازرس» نهایی میشود که یک لایه ردیابی (Traceability layer) ایجاد میکند. این پنل بازرس، شواهد ساختارمندی را برای هر جمله و هر دارایی بصری نمایش میدهد. هر نمودار حاشیهنویسی شده، المان تعاملی و هر جمله، یک «کارت شناسایی» دارد که یا URL خارجی پشتیبان ادعا را نشان میدهد و یا دقیقاً خط کد و فایل دادهای که پشت آن عدد است را نمایش میدهد. این ویژگی به خوانندگان اجازه میدهد با یک اسکریپت قابل اجرا تعامل داشته باشند که ارقام را مستقیماً از دادههای خام دوباره محاسبه میکند. 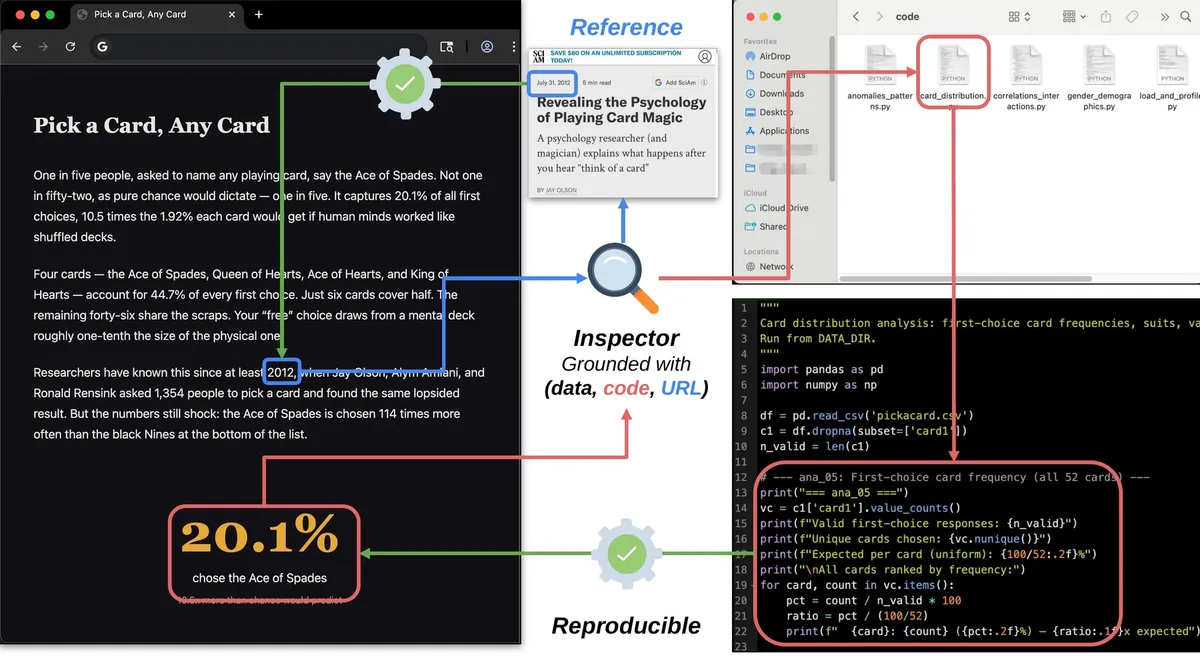
بنچمارک در برابر انسانها
پژوهشگران برای آزمایش Data2Story، ۱۸ مجموعهداده عمومی را با نمونههای مشابه که توسط انسان نوشته شده بودند، جفت کردند. این منابع انسانی از سه منبع متمایز بودند: گزارشهای موجز و مختصر The Economist، روایتهای بلند با طراحی مجلل از The Pudding و مجموعهدادههای جامعهمحور از TidyTuesday. در نهایت، ۵۳ خواننده دعوت شدند تا هر دو نسخه را در ۵ دسته رتبهبندی کنند: طراحی بصری، ریتم روایت، شفافیت دادهها، تأییدپذیری ادعاها و میزان بینش بهدست آمده.
نتایج بهدست آمده تکاندهنده بود: ۷۴٪ از خوانندگان مقالات تولیدشده توسط عاملها را ترجیح دادند، در حالی که ۲۵٪ نسخه انسانی را انتخاب کردند و تنها ۲٪ نتیجه را مساوی دانستند.
- پیشتازی در شفافیت: Data2Story در هر ۵ دسته برنده شد. بیشترین فاصله در بخش شفافیت بود، جایی که امتیاز این سیستم ۱.۴۹ واحد در مقیاس ۷ درجهای بالاتر از انسان بود.
- شکاف تأییدپذیری: ۹۳٪ از تمام اظهارات قابل مشاهده در مقالات تولیدشده توسط عاملها، قابل تأیید بودند. در مقابل، در نسخههای انسانی این رقم تنها ۲۵٪ بود؛ دلیل اصلی این است که روزنامهنگاران بهندرت کدهای تحلیل خود را منتشر میکنند. پژوهشگران ادعا میکنند این شکاف هم نشاندهنده نقطه قوت سیستم است و هم نشاندهنده حفرهای در عملکردهای فعلی روزنامهنگاری.
- پوشش محتوایی: هنگام اندازهگیری همپوشانی اظهارات، Data2Story حدود نیمی از دیدگاههای انسانی را پوشش میدهد. در مقابل، روزنامهنگاران تنها یکسوم (۳۵٪) از اظهارات عامل AI را شکار میکنند. این شکاف در گزارشهای فرمالیستی اکونومیست در کمترین حالت است؛ جایی که عامل توانست ۷۳٪ از یافتههای انسانی را بازتولید کند، زیرا آن متون از آمارهای استانداردی پیروی میکنند که عامل بهراحتی میتواند محاسبه کند.
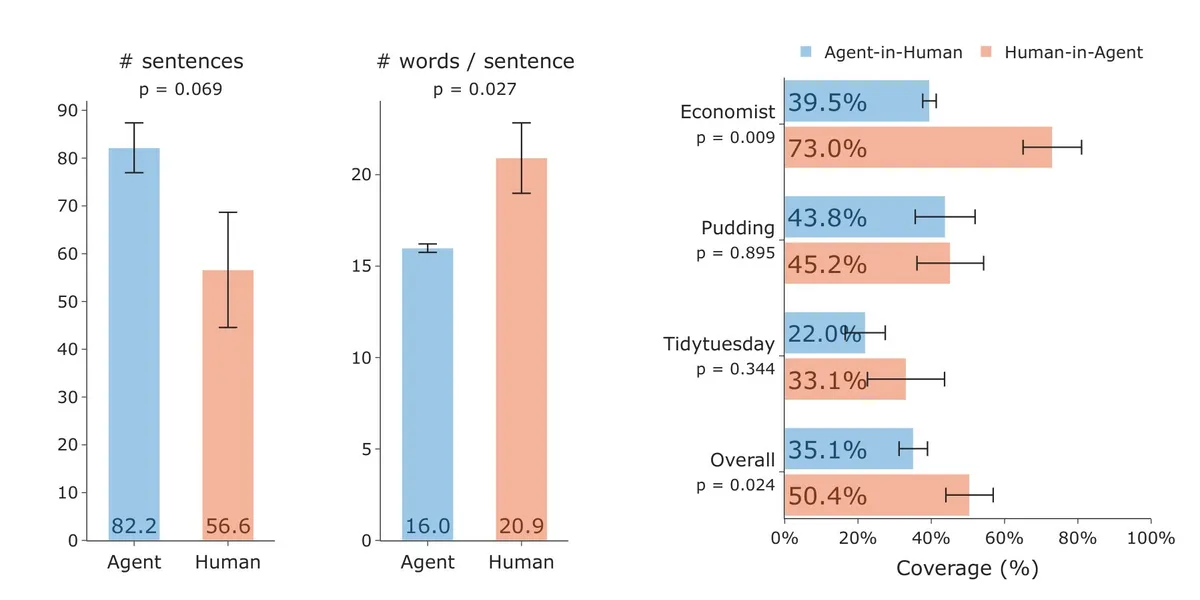
جایی که انسانها هنوز برنده هستند
با وجود بهرهوری بالا، پژوهشگران سه حوزه را شناسایی کردند که در آنها روزنامهنگاری انسانی همچنان برتر است:
۱. دیدگاه تحریریه (Editorial Perspective): خبرنگاران با استفاده از گزارشگری میدانی و تئوری، «چرایی» پشت دادهها را توضیح میدهند. در گزارشی درباره «کافههای تعمیرات» (Repair Cafes)، نویسنده انسانی توانست نرخ پایین تعمیرات را به سیاست تولیدکنندگان گوشی، خودرو و تراکتور مرتبط کند که بهطور عمدی دسترسی به ابزارهای تشخیصی و قطعات را مسدود کردهاند. در مقابل، عامل AI فقط توانست نرخ تعمیرات را بر اساس نوع محصول نمودار کند؛ اما نتوانست تئوری «ماتریس انسداد شرکاتی» را کشف کند. 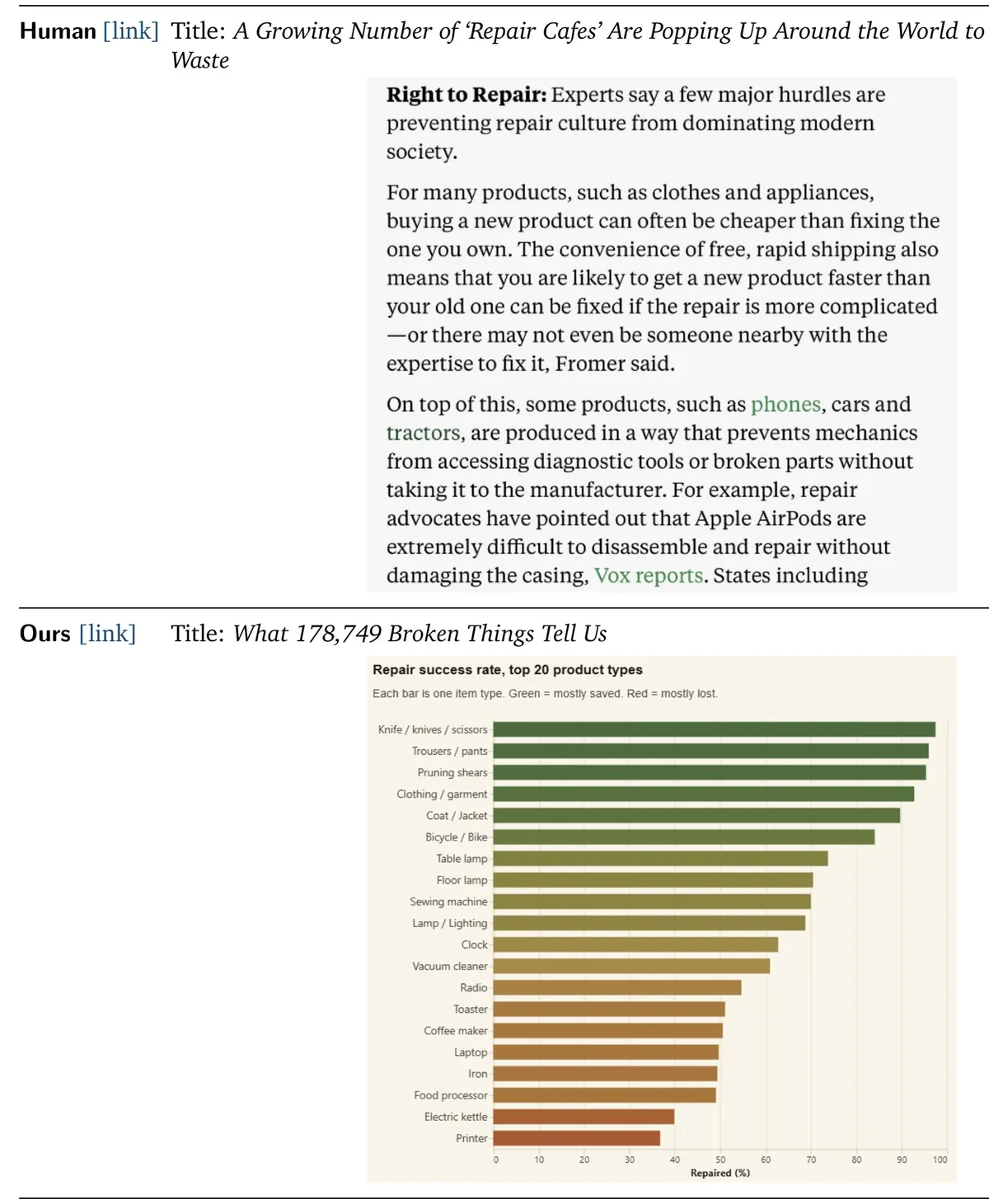
۲. طراحی خلاق رابط کاربری (Creative Interface Design): تیمهای انسانی میتوانند داده را به یک «تجربه» تبدیل کنند. در مقالهای درباره کمدی استندآپ، وبسایت The Pudding متن کامل یک نمایش علی وانگ را به رابط کاربری تبدیل کرد که در آن اندازه دایرهها متناسب با طول خندههای Publikum بود. در مقابل، Data2Story بهسادگی یک تصویر بندانگشتی (Thumbnail) استاتیک و قابل کلیک از یوتیوب قرار داد. 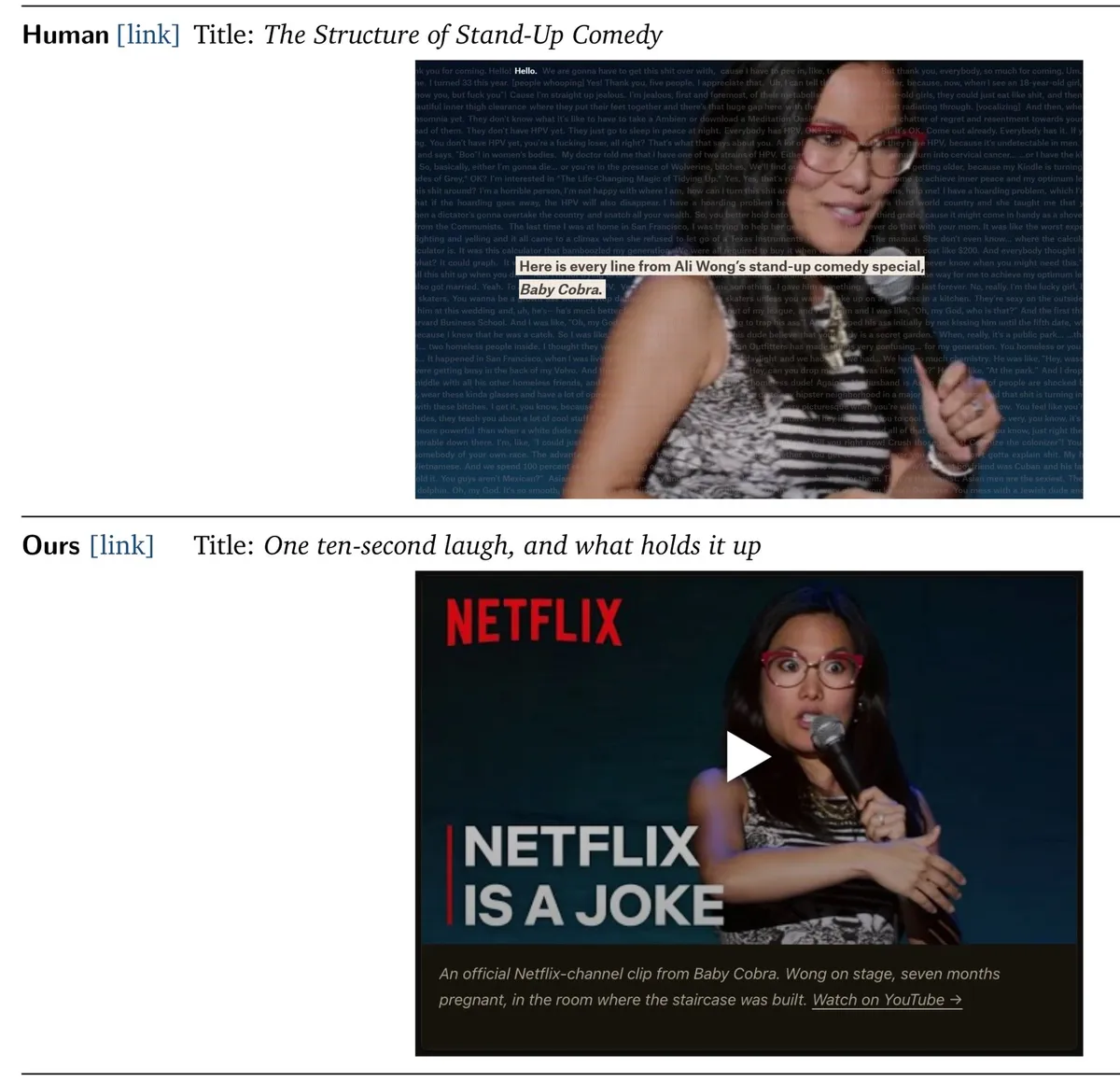
۳. تراکم گرافیکی (Graphic Density): طراحان انسانی میتوانند اطلاعات را بهطور موثرتری لایهبندی کنند. اکونومیست اغلب ارائهدهندگان دولتی و تجاری، نرخ موفقیت و حاشیهنویسیها را در یک گرافیک متراکم واحد برای موضوع «رقابت فضایی» جای میدهد. اما Data2Story همان دادهها را در چندین نمودار تعاملی سادهتر پخش کرد، که باعث شد نکته اصلی روایت در میان نمودارهای متعدد گم شود. 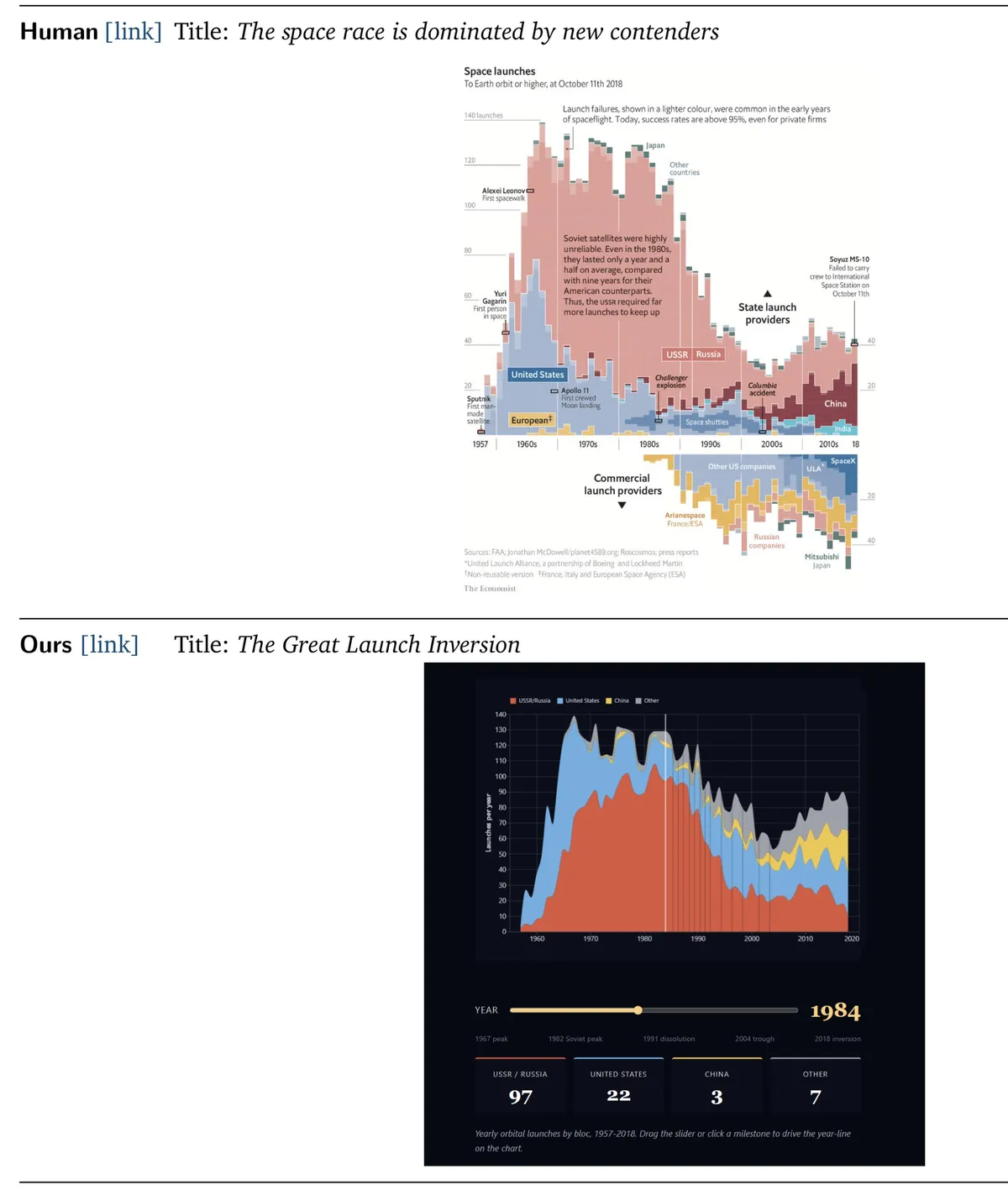
زیرساخت فنی
این سیستم توسط مدل Claude Opus 4.7 که روی Claude Code اجرا میشود، قدرت میگیرد. برای مدیریت المانهای چندوجهی، سیستم مدلهای OpenRouter را ادغام کرده است؛ از جمله gpt-5.4-image-2 برای تولید تصاویر، و مدلهای seedance-2.0 و lyria-3-pro-preview برای صوت و ویدیو.
این تغییر نشاندهنده حرکتی به سمت فلسفه «جستوجو بهمثابه کد» (Search as Code) است؛ فلسفهای مشابه آخرین بهروزرسانیهای Perplexity، که در آن مدل بهجای تکیه بر یک API جعبهسیاه، ابزارهای جستوجو و محاسباتی خودش را مینویسد. این امر تضمین میکند که اگر خوانندهای به یک رقم شک کرد، میتواند شخصاً کد زیرین را اجرا کند تا خروجی را تأیید نماید. در دنیای مدلهای زبانی، دقت در محاسبات و خروجیها حیاتی است، همانطور که در تحلیلهای مربوط به اثرات زیستمحیطی AI، چارچوبهای دقیق برای اصلاح تخمینهای نادرست طراحی شدهاند تا از توهمات عددی جلوگیری شود.
برای تحریریهها، این ابزار به عنوان یک «همکار» معرفی شده است، نه جایگزین. انسانها دیدگاه و گزارشگری را فراهم میکنند و عاملها محاسبات و مستندسازی منابع قابل تأیید توسط ماشین را بر عهده میگیرند. این سیستم بهویژه برای مجموعهدادههای تخصصی (Niche) که بهدلیل کمبود نیروی انسانی هرگز به داستان تبدیل نمیشوند، بسیار مفید است. در حال حاضر سیستم بهصورت «خلبان خودکار کامل» (full autopilot) اجرا میشود، اما پژوهشگران قصد دارند در نسخههای آینده بازخوردهای «انسان در حلقه» (human-in-the-loop) را پیادهسازی کنند. پروژه در آدرس data2story.github.io فعال است و کدهای آن در گیتهاب در دسترس است.



گفتگو