
تفاوت میان یک بات صوتی کُند و یک همصحبت انسانی، تنها در چند میلیثانیه تأخیر نهفته است. اگر هنوز فکر میکنید تأخیر در پاسخهای صوتی هوش مصنوعی زاینده (Generative AI) اجتنابناپذیر است، زیرساخت جدید OpenAI ثابت میکند که اشتباه میکنید.
به نقل از گزارش فنی openai.com، این شرکت در ۴ مه ۲۰۲۶ زیرساخت رسانهای خود را بهطور کامل بازطراحی کرد تا تعاملات صوتی با سرعت گفتار انسان همگام شوند. هدف اصلی، حذف وقفههای آزاردهنده و کاهش لرزش شبکه (Jitter) برای ۹۰۰ میلیون کاربر فعال هفتگی بود.
طبق اعلام این شرکت، چالش اصلی در تضاد میان استاندارد WebRTC (ارتباط بلادرنگ وب) و محیط Kubernetes (کوبنتیز) بود. مدل سنتی WebRTC برای هر نشست به یک پورت مجزا نیاز دارد که مقیاسپذیری در کلاسترها را غیرممکن میکند و حفرههای امنیتی بزرگی ایجاد میکند. برای حل این بحران، OpenAI مدل قدیمی SFU را کنار گذاشت.
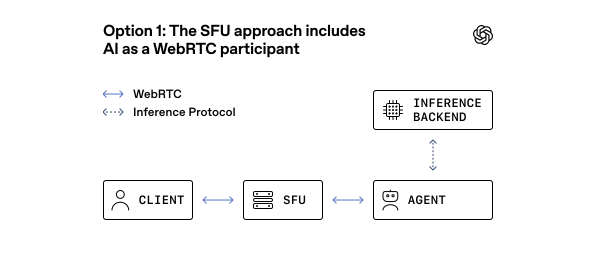
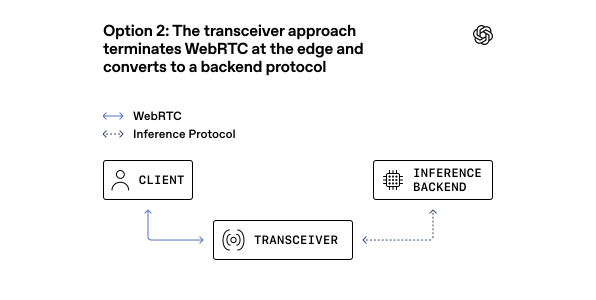
در عوض، آنها یک مدل «فرستنده-گیرنده» (Transceiver) را پیاده کردند که در آن سرویس لبه (Edge Service)، اتصال کاربر را میپذیرد و رسانه را به پروتکلهای داخلی برای استنتاج (Inference) تبدیل میکند. این معماری به دو لایهی مجزا تقسیم شده است:
- رله (Relay): یک لایهی ارسالی UDP سبک بر پایهی زبان Go که با استفاده از
ufragدر پروتکل ICE، مقصد بسته را شناسایی و مسیریابی میکند.
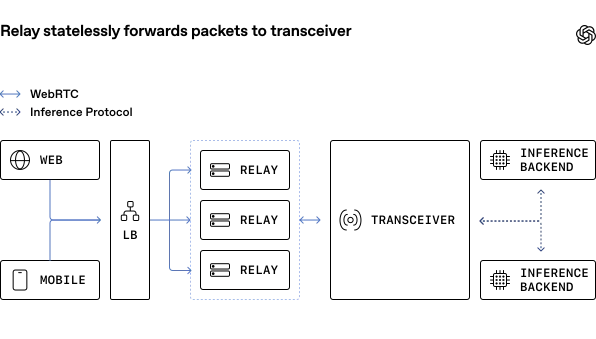
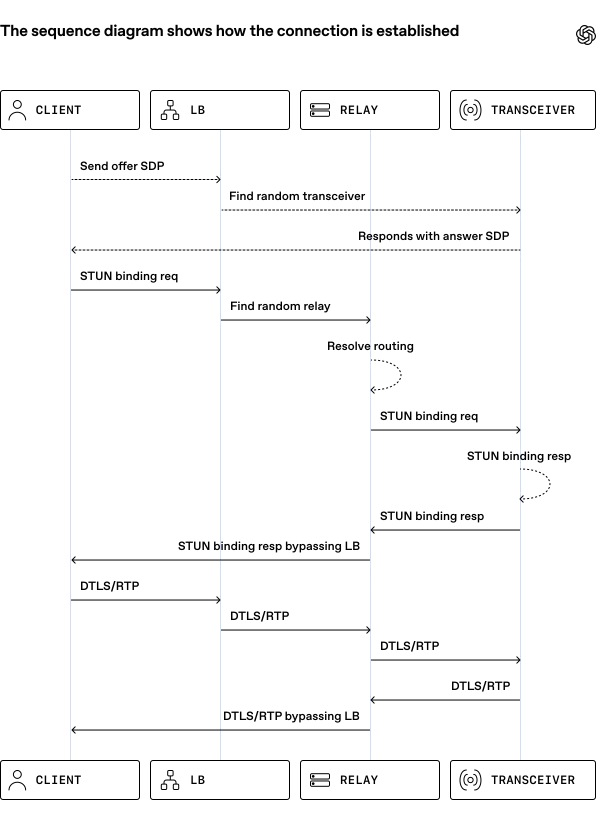
- فرستنده-گیرنده (Transceiver): نقطهی پایانی وضعیتدار (Stateful) که مسئولیت بررسیهای اتصال ICE، دستتکانیهای DTLS و کلیدهای رمزنگاری SRTP را بر عهده دارد.
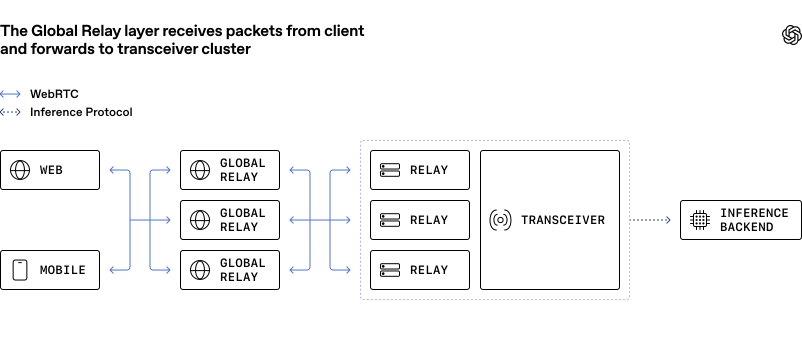
این طراحی به OpenAI اجازه میدهد با استفاده از ناوگان «رلههای جهانی»، نقاط ورود را به کاربر نزدیکتر کند و تأخیر گام اول را به حداقل برساند. آنها برای بهینهسازی حداکثری، از قابلیتهای لینوکس مانند SO_REUSEPORT و پین کردن رشتهها (Thread Pinning) استفاده کردند تا بدون نیاز به چارچوبهای پیچیدهی Kernel-bypass، بازدهی CPU را بالا ببرند.
همانطور که در تحلیل قبلی ما دربارهی رقابت ۵.۵ میلیارد دلاری OpenAI و Anthropic برای تسخیر بازارهای سازمانی اشاره کردیم، این تغییر معماری نشاندهندهی گذار به سمت بهینهسازیهای عمیق زیرساختی است. در حالی که رقبا بر اندازه مدل تمرکز دارند، OpenAI بهطور تهاجمی در حال بهینهسازی «مایل آخر» است تا عوامل هوش مصنوعی کاملاً نامرئی شوند.


با تبدیل شدن هوش مصنوعی صوتی از یک ابزار تفننی به یک رابط کاربری اصلی، گلوگاه بعدی احتمالاً از مسیریابی نرمافزاری به محدودیتهای فیزیکی سختافزارهای رایانش لبه (Edge Computing) منتقل خواهد شد. اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- اگر توسعهدهنده هستید، معماری Split-Relay را برای کاهش Latency در اپلیکیشنهای بلادرنگ مطالعه کنید.
- تغییر رفتار OpenAI را به عنوان سیگنالی برای اهمیت «تجربه کاربر» (UX) در مقابل «اندازه مدل» در استراتژی محصول خود بگنجانید.
- روند ادغام پروتکلهای UDP در محیطهای کلاستری را دنبال کنید.



گفتگو