
اگر در حال ساخت رباتی هستید که باید یک لیوان در حال حرکت را بگیرد یا یک تولیدکننده ویدیو میسازید که نیازمند حرکاتی با دقت فیزیکی است، بزرگترین مانع شما دیگر «دیدن» دنیا نیست، بلکه «پیشبینی» آن است. در ۱۷ ژوئن ۲۰۲۶، مؤسسه AllenAI سیستم MolmoMotion را عرضه کرد؛ سیستمی که دستورات زبانی را به پیشبینیهای دقیقِ حرکت سهبعدی تبدیل میکند. طبق گزارش فنی رسمی، این مدل به ماشینها اجازه میدهد بهجای واکنش صرف به جایی که یک شیء «بوده است»، پیشبینی کنند که آن شیء در چند ثانیه آینده در فضای سهبعدی به کجا «خواهد رفت».
اکثر سیستمهای فعلی هوش مصنوعی نگاهبه-عقب (Retrospective) دارند؛ آنها پیکسلهایی را ردیابی میکنند که پیشتر جابهجا شدهاند. اما برای اینکه یک ربات بتواند در یک خانه واقعی عملکرد مناسبی داشته باشد، باید بتواند مسیر لغزش یک کاسه را پیش از آنکه با آن تماس پیدا کند، پیشبینی نماید. این تغییر رویکرد از «ادراک» (Perception) به «پیشبینی» (Forecasting)، هسته اصلی پروژه MolmoMotion است. برای دستیابی به این هدف، تیم پژوهشگر از قالبهای خشک و صلب برای بدن انسان یا اشیاء خاص فاصله گرفتند و در عوض، یک نمایش «ناوابسته به کلاس» (Class-agnostic) را با استفاده از نقاط سهبعدی در فضای جهان انتخاب کردند.
فلسفه نمایش نقاط سهبعدی
تیم AllenAI تصمیم گرفت حرکت را به صورت نقاط سهبعدی متصل به شیء در فضای جهان نمایش دهد، زیرا این روش از هزینههای محاسباتی سنگین رندر کردن کامل ویدیو جلوگیری میکند. تیم تحقیق به یک نمایش کلی از حرکت نیاز داشت که سه ویژگی خاص را برآورده کند:
- ناوابسته به کلاس (Class-agnostic): سیستم به قالبهای ثابت برای بدن انسان، دستها، اشیاء سخت یا هر دسته خاص دیگری وابسته نیست.
- پایدار در نما (View-stable): حرکت فیزیکی فارغ از موقعیت دوربین یا تغییرات زاویه دید، بهطور سازگار و یکسان نمایش داده میشود.
- کاربردی در مراحل بعدی (Downstream Utility): مسیرهای پیشبینیشده فشرده و صریح هستند و همین امر آنها را مستقیماً برای سیاستهای کنترلی ربات یا مدلهای تولید ویدیو قابل استفاده میکند.
با استفاده از مجموعهای پراکنده از نقاط سطحی، مدل میتواند حرکات سخت (Rigid)، مفصلی (Articulated) و حتی برخی حرکات تغییرشکلدهنده (Deformable) را توصیف کند، بدون اینکه نیاز داشته باشد نوع دقیق شیء در حال حرکت را بداند. از آنجایی که این نقاط در یک قاب مشترک جهانی قرار دارند، حتی در زمان حرکت دوربین نیز پایدار میمانند.
مکانیسم پیشبینی حرکت
مدل MolmoMotion از Molmo 2 بهعنوان ستون فقرات و زیرساخت بنیادین خود استفاده میکند. این ساختار اجازه میدهد یک دستور متنی — برای مثال «کاسه چوبی حاوی میوه روی میز را جابهجا و بچرخان» — مستقیماً به پیکسلها و نقاط سهبعدی در یک فریم ویدیو متصل شود.
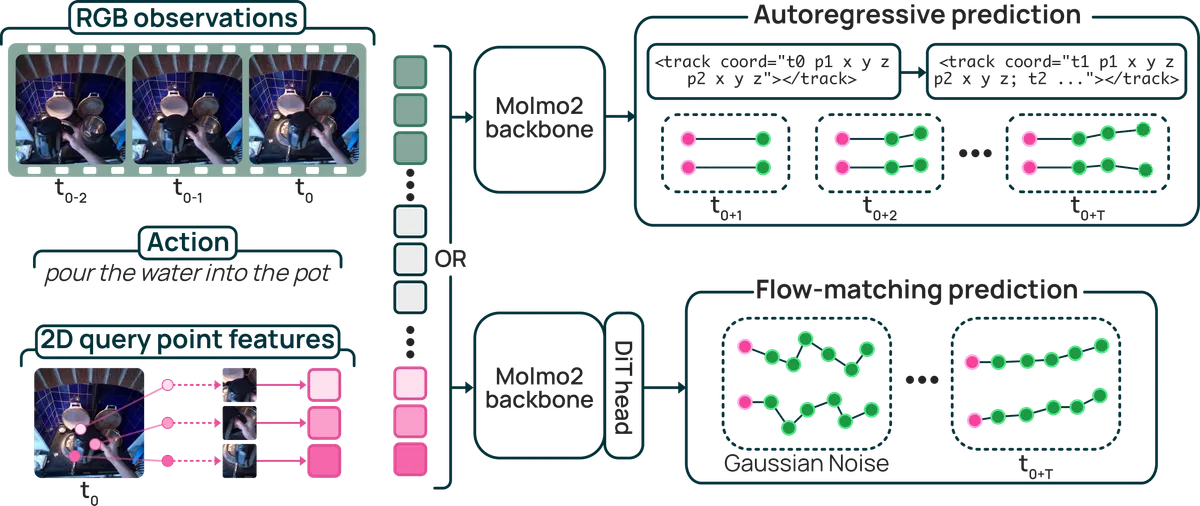
ورودی مشترک این سیستم شامل توکنهای تصویری حاصل از مشاهدات RGB، توکنهای متنی برای توصیف اکشن و توکنهای ویژگی نقاط پرسوجوی دوبعدی (2D query point feature tokens) است که از انکودر بینایی Molmo 2 نمونهبرداری شدهاند. هنگامی که یک تاریخچه کوتاه از ویدیو، یک توصیف از اکشن و نقاط پرسوجو با موقعیتهای سهبعدی اولیه به مدل داده شود، مدل ابتدا شیء هدف و حرکت مورد نظر را شناسایی کرده و سپس مسیر سهبعدی آینده هر نقطه را پیشبینی میکند.
این سیستم برای مدیریت انواع مختلف حرکت، از دو مدل معماری متمایز استفاده میکند:
- MolmoMotion-AR (خودبازگشتی): این نسخه مختصات آینده را گامبهگام پیشبینی میکند. در این مدل، مختصات سهبعدی به صورت متن ساختاریافته نمایش داده میشوند که از سبک پیشبینی مختصات رایج در مدلهای زبانی-بینایی (VLMs) پیروی میکند. چون هر مختصات جدید بر اساس مختصات قبلی شرطی میشود، این روش باعث ایجاد خروجیهای نرمتر (Smooth rollouts) شده و در مسیرهایی که آیندهشان بهوضوح تعریف شده است، بیشترین دقت را ارائه میدهد.
- MolmoMotion-FM (تطبیق جریان): این مدل مسیرها را در فضای سهبعدی پیوسته و از طریق تبدیل نویز به حرکت پیشبینی میکند. این ویژگی باعث میشود مدل برای نمایش «عدم قطعیت» در سناریوهایی که یک دستور واحد میتواند به چندین آینده فیزیکی محتمل منجر شود، مناسبتر باشد.
حل شکاف داده با MolmoMotion-1M
آموزش یک مدل پیشبین به حجم عظیمی از دادههای سهبعدی نیاز دارد که بهندرت در محیطهای طبیعی و باز یافت میشوند. مجموعههای داده موجود برای ردیابی سهبعدی (3D-track) بیش از حد کوچک بودند و دامنه محدودی داشتند. برای حل این مشکل، AllenAI یک خط لوله (Pipeline) خودکار برای استخراج مسیرهای سهبعدی از ویدیوهای نامحدود اینترنتی طراحی کرد.
این خط لوله از یک فرآیند چندمرحلهای پیروی میکند: ابتدا شیء متحرک را مکانیابی (Grounding) کرده و نقاط پرسوجو را نمونهبرداری میکند. سپس نقاط متراکم دوبعدی را روی شیء ردیابی کرده و این ردیابیها را به یک قاب متریک سهبعدی مشترک منتقل (Lift) میکند. در نهایت، از پیشفرضهای سازگاری مکانی و زمانی در سطح شیء استفاده میکند تا مسیرهای غیرقابلاعتماد را فیلتر کرده و ویدیو را دقیقاً در بازهای که حرکت معنادار رخ میدهد، برش بزند.
نتیجه این تلاش، ایجاد MolmoMotion-1M است؛ که در حال حاضر بزرگترین مجموعه از مسیرهای نقاط سهبعدی است که دارای توصیف اکشن و مکانیابی شیء هستند. این دیتاست شامل ۱.۱۶ میلیون ویدیو است که ۷۳۶ نوع حرکت مختلف و ۵.۶ هزار شیء متمایز را پوشش میدهد. از آنجایی که دادههای خام ویدئویی اغلب نویزی هستند — و شامل خطاهای عمق و ردیابی میشوند که باعث لرزش یا رانش (Drift) نقاط میگردند — تیم یک فرآیند فیلترینگ را اجرا کرد تا اطمینان حاصل شود که نقاط بهطور منسجم با شیء حرکت میکنند.
بنچمارک و عملکرد در دنیای واقعی
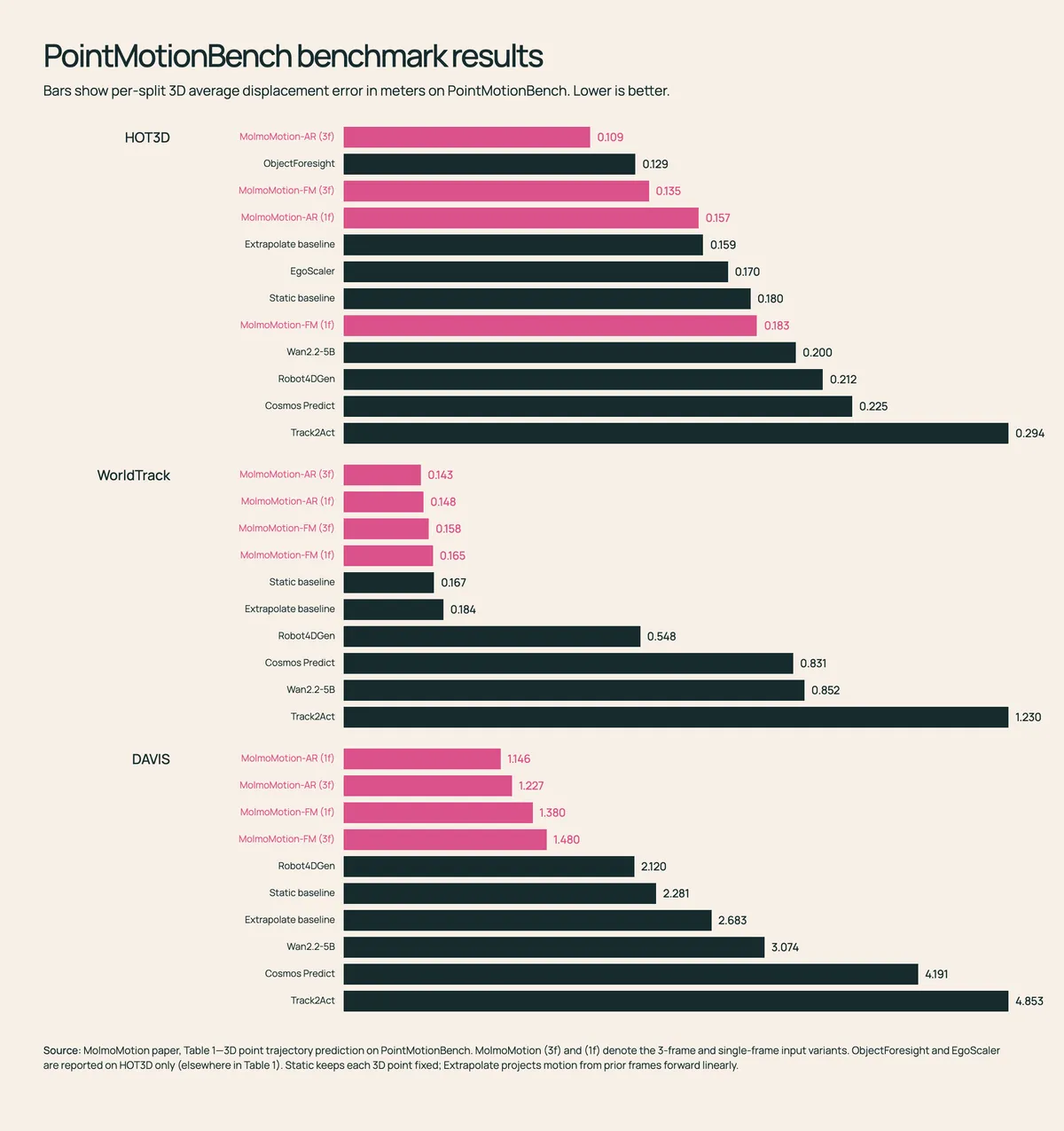
پژوهشگران برای اثبات کارایی مدل، PointMotionBench را معرفی کردند؛ یک بنچمارک تأییدشده توسط انسان شامل ۲.۷ هزار کلیپ ویدئویی. این آزمون ۱۱۱ دسته از اشیاء را در ۶۱ نوع حرکت بررسی میکند؛ از خم شدن نوک یک فلامینگو در آب گرفته تا چرخش یک ماشین در جاده.
بنچمارک PointMotionBench یک تست کمی مستقیم از پیشبینی حرکت سهبعدی ارائه میدهد و بهجای تکیه بر این موضوع که آیا یک مسیر «به نظر» محتمل میرسد یا خیر، دقت را میسنجد. این بنچمارک طیف گستردهای از صحنهها را پوشش میدهد، از جمله:
- وظایف دستکاری اشیاء در محیطهای داخلی (Indoor manipulation).
- تعاملات دست و شیء از زاویه دید اول شخص (Egocentric).
- صحنههای دینامیک فضای باز.
در تستهای رودررو در PointMotionBench، مدل MolmoMotion تمام روشهای آزمایششده دیگر، از جمله تولیدکنندههای ویدیو در فضای پیکسلی، متدهای سهبعدی پارامتریک و حتی مدلهای ساده با سرعت ثابت (Constant-velocity baselines) را شکست داد. برای مثال، این مدل بهدقت پیشبینی کرد که یک غلتک پرز چگونه روی پارچه به جلو و عقب حرکت میکند یا یک ماشین نقرهای چگونه در جاده پیش رفته و بهآرامی به راست میپیچد. در هر مورد، مسیر پیشبینیشده از دستور متنی پیروی کرد و بسیار نزدیک به حرکت واقعی (Ground truth) باقی ماند.
تأثیر بر رباتیک و تولید ویدیو
کاربرد عملی این مسیرهای سهبعدی فراتر از پیشبینی ساده است. وقتی این مدل در برنامهریزی رباتیک ادغام میشود، تأثیر آن قابل اندازهگیری است. AllenAI استدلال میکند که اگرچه بلند کردن یک لیوان با دست انسان و یک گیره رباتیک دو اکشن متفاوت هستند، اما مسیر سهبعدی خودِ لیوان مشابه باقی میماند.
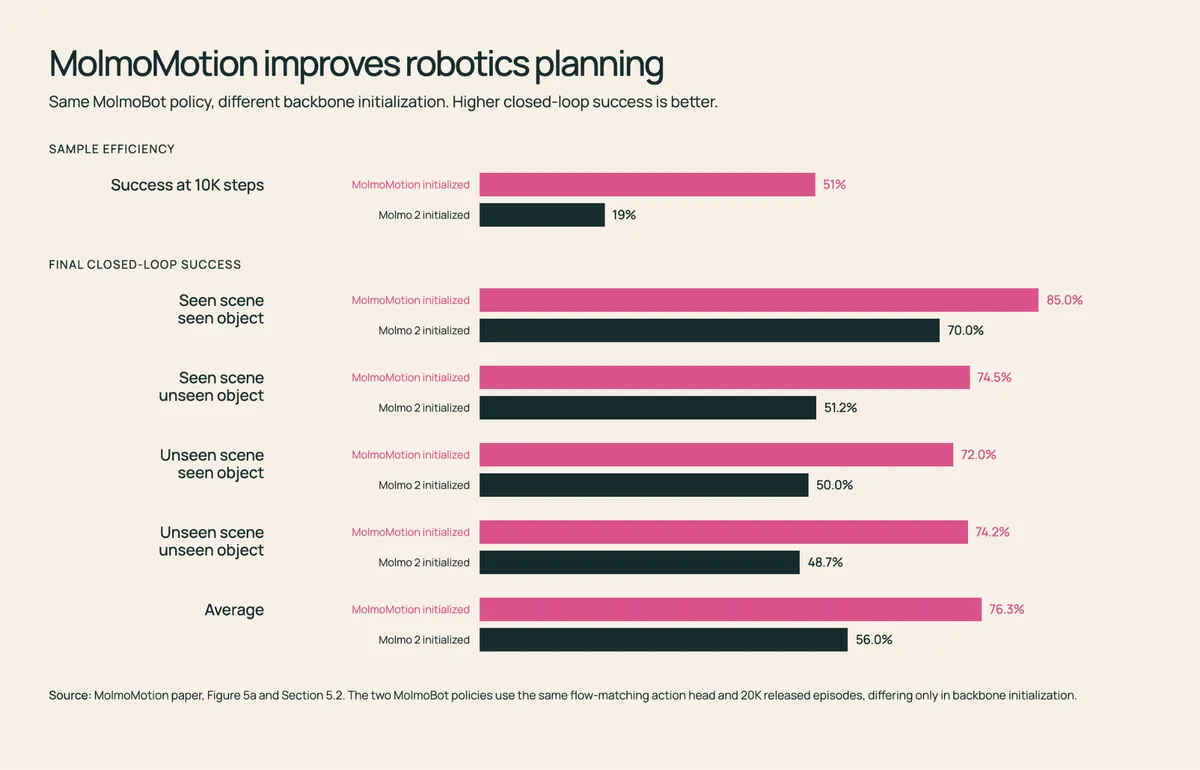
پس از تنظیم دقیق (Fine-tuning) روی DROID — یک مجموعه داده باز و بزرگ از ویدیوهای دستکاری رباتیک در دنیای واقعی — یک سیاست کنترلی (Control policy) که از MolmoMotion استفاده میکرد، در ۷۶.۳٪ از وظایف «برداشتن و گذاشتن» (Pick-and-place) موفق شد، در حالی که این میزان برای سیاستی که بر پایه Molmo 2 استاندارد بود، تنها ۵۶.۰٪ بود.
در حوزه رباتیک، MolmoMotion سرعت یادگیری را بهطور قابلتوجهی شتاب بخشید:
- سرعت آموزش: سیاست مبتنی بر MolmoMotion پس از ۱۰ هزار گام آموزشی به موفقیت ۵۱ درصدی رسید، در حالی که نسخه Molmo 2 در نهایت روی ۱۹٪ متوقف شد.
- کاهش خطا: در رباتهای واقعی، MolmoMotion تنها با ۲ هزار گام آموزشی به همان خطای L2 در تست رسید که مدل پایه برای دستیابی به آن به ۱۲ هزار گام نیاز داشت.
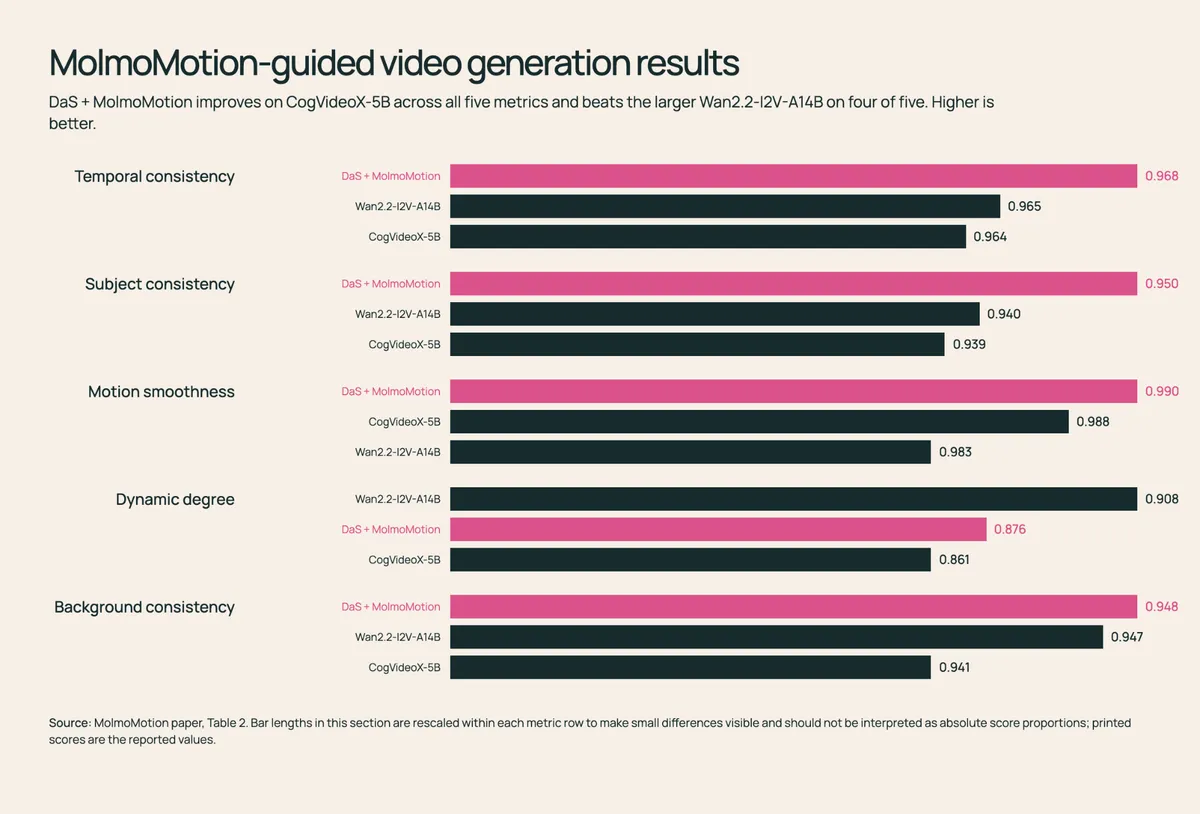
برای سازندگان محتوا، این پیشبینیها مانند یک «فرمان» برای تولید ویدیو عمل میکنند. بهجای اینکه مدلهایی مثل CogVideoX-5B یا WAN-14B حرکت را صرفاً از روی یک پرامپت حدس بزنند، کاربران میتوانند مسیرهای سهبعدی MolmoMotion را به آنها تزریق کنند. این کار باعث میشود ویدیوها حرکات دقیق و کوچک — مثل برداشتن یک بشقاب گرد قهوهای روشن از روی میز — را بهدرستی اجرا کنند؛ حرکاتی که پرامپتهای متنی معمولاً بهقدری مبهم توصیف میکنند که اجرای صحیح آنها دشوار است. معیارها نشان میدهند که MolmoMotion کیفیت حرکت را در تمام پنج معیار اندازهگیری شده نسبت به مدلهای پایه بهبود میبخشد و در چهار مورد از این پنج معیار، مدلهای بزرگترِ «تصویر-به-ویدیو» را شکست میدهد.
تحلیل: تغییر پارادایم هوش مصنوعی
برای توسعهدهندگان و مهندسان، MolmoMotion نشاندهنده حرکتی به سوی «هوش فیزیکی» است. با جداسازی حرکت از دستههای خاص اشیاء (مانند «انسان» یا «دست»)، AllenAI ابزاری ساخته است که در سراسر دنیای فیزیکی تعمیم مییابد. این بدان معناست که یک ربات دیگر نیازی به مدلهای مجزا برای هر شیئی که با آن مواجه میشود ندارد؛ بلکه فقط باید مسیر سهبعدی نقاط روی سطح آن شیء را درک کند.
این رویکرد بهطور مؤثری شکاف بین مدلهای زبانی بزرگ (LLMs) و عملگرهای فیزیکی (Actuators) را پر میکند. توانایی ترجمه یک فرمان سطحبالا به یک مسیر سهبعدی سطحپایین، حلقه مفقوده برای رسیدن به رباتیک خانگی قابلاعتمادتر و ویدیوهای سنتتیک با وفاداری بالا (High-fidelity) است.
محدودیتها و چشمانداز آینده
با وجود دستاوردهای ذکر شده، مدل در حال حاضر محدودیتهای خاصی دارد. این مدل در طول آموزش تنها از هشت نقطه پرسوجو برای هر شیء استفاده میکند. اگرچه این تعداد برای پیشبینی یک مسیر مفید کافی است، اما برای نمایش متراکم هندسه سطح (Surface geometry) کفایت نمیکند. این موضوع توانایی مدل را در مدیریت حرکات پیچیده تغییرشکلدهنده، مانند تا کردن پارچه یا دینامیک سیالات، محدود میکند.
مؤسسه AllenAI وزنهای مدل، مجموعه داده MolmoMotion-1M و بنچمارک PointMotionBench را بهصورت باز منتشر کرده است. اکنون از جامعه علمی دعوت شده تا این ابزارها را برای جابهجا کردن مرزهای پیشبینی سهبعدی شخصیسازی کنند. برای مشاهده این مسیرها در عمل، میتوانید صفحه پروژه را بررسی کنید یا وزنهای مدل را در Hugging Face تست کنید تا ببینید مدل چگونه با جفتهای خاص «شیء-اکشن» شما برخورد میکند.



گفتگو