اگر امروز برای طراحی یک خط لوله سازمانی با سرعت بالا به دنبال مدلهای وزنباز هستید، انتخاب اول شما تغییر کرده است. انویدیا (Nvidia) با معرفی Nemotron 3 Ultra، حالا صاحب هوشمندترین مدل باز آمریکاست.
این اتفاق در حالی میافتد که فاصله میان مدلهای باز آمریکا و چین در حال کم شدن است. در این میدان، مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن جواب میدهد — باید هم سرعت داشته باشد و هم دقت. همانطور که در تحلیل قبلی ما دربارهی رقابت مدلهای بازمتن اشاره کردیم، میدان نبرد اصلی اکنون روی زیرساختهاست. در این فضای رقابتی، وزنهای باز (Open Weights) — یعنی «دستور پخت» مدل علناً منتشر شده، نه فقط غذای آماده — به ابزاری برای تسریع نوآوری تبدیل شدهاند.
طبق گزارش Artificial Analysis، این مدل از معماری مجموعهای از متخصصان (Mixture-of-Experts یا MoE) — شبیه تیمی از متخصصان که فقط فرد مورد نیاز برای هر سؤال فراخوانده میشود — بهره میبرد. این مدل ۵۵۰ میلیارد پارامتر کلی و ۵۵ میلیارد پارامتر فعال دارد. نقاط قوت این مدل در بنچمارکها کاملاً مشخص است:
- نمره هوش: Nemotron 3 Ultra با ۴۸ امتیاز، مدلهای Gemma 4 31B (۳۹ امتیاز) و Nemotron 3 Super (۳۶ امتیاز) را شکست داد.
- سرعت استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند — در پلتفرم DeepInfra به بیش از ۳۰۰ توکن در ثانیه میرسد. این عدد بسیار بیشتر از ۵۰ تا ۱۰۰ توکن در ثانیهی مدلهای DeepSeek یا Moonshot است.
- سقف جهانی: با این حال، مدل چینی Kimi K2.6 با ۵۴ امتیاز همچنان پیشتاز است و مدل بسته Opus 4.8 با ۶۱ امتیاز در صدر قرار دارد.
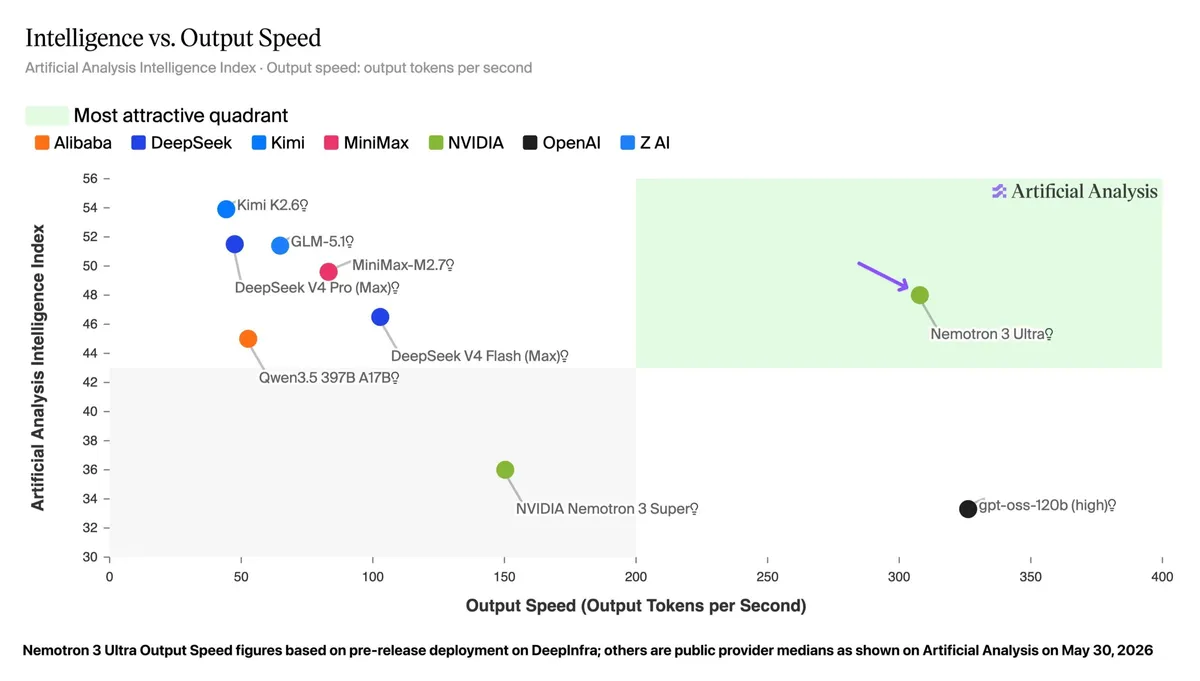
برای مدیران کسبوکار، این یعنی دیگر لازم نیست بین سرعت و هوش یکی را انتخاب کنند. انویدیا فقط تراشه نمیسازد؛ بلکه وزنهای مدل را طوری تنظیم میکند که روی سختافزار خودش با حداکثر سرعت اجرا شوند. این موضوع فشار را روی سایر آزمایشگاههای آمریکایی میاندازد تا مدلهای بزرگتر را بدون افزایش تأخیر منتشر کنند.
این مدل از ۴ ژوئن ۲۰۲۶ از طریق Hugging Face، OpenRouter و سایر پلتفرمها در دسترس خواهد بود.
گام بعدی شما
- بررسی خروجیهای مدل در Hugging Face یا OpenRouter از ۴ ژوئن ۲۰۲۶.
- تحلیل اثر سرعت ۳۰۰ توکنی بر عملکرد عاملهای خودمختار در محیط عملیاتی.
- مقایسه هزینه استنتاج این مدل با مدلهای رقیب در مقیاس تجاری.
اما داستان سختافزاری این تحول شگفتانگیزتر است؛ به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو