اگر امروز یک پروژه تخصصی طراحی یا تحلیل داده را به فریلنسر میسپارید، باید بدانید که احتمال پذیرش خروجی یک مدل هوش مصنوعی توسط مشتری واقعی، به شدت در حال افزایش است. طبق گزارش منتشر شده در ۲ جولای ۲۰۲۶، اکنون ۱۶.۱٪ از پروژههای پرداختشده در سطح کیفی حرفهای توسط عاملهای هوش مصنوعی تکمیل میشوند. این سطح از کیفیت به معنای خروجیهایی است که یک مشتری پرداختکننده، آنها را به عنوان محصول نهایی بپذیرد.
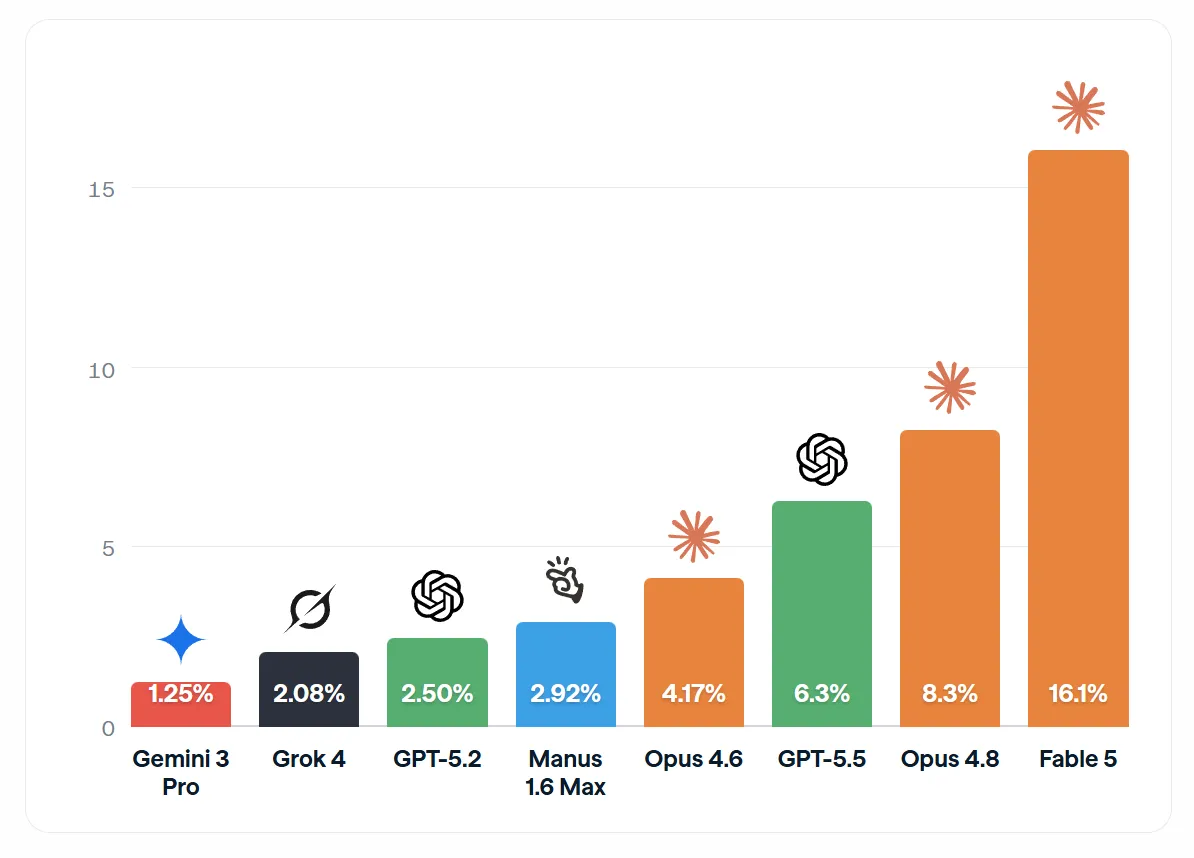
این رقم جهش عظیمی نسبت به نرخ ۲.۵ درصدی است که تنها ۸ ماه پیش ثبت شده بود. این دادهها از نتایج آخرین نسخه شاخص نیروی کار از راه دور (Remote Labor Index - RLI) استخراج شدهاند. این شاخص که توسط مرکز ایمنی هوش مصنوعی (CAIS) و اسکیل لبز (Scale Labs) طراحی شده، بررسی میکند که عاملهای هوش مصنوعی (AI Agents) — شبیه دستیارهای دیجیتالی که میتوانند به جای شما نرمافزارها را باز کنند و تصمیم بگیرند — تا چه حد میتوانند کارهای ارزشمند تجاری را در حوزههایی مثل طراحی سه بعدی (3D CAD)، معماری و تحلیل داده به پایان برسانند.
همانطور که در تحلیلهای قبلی ما دربارهی تکامل مدلهای استدلالی اشاره کردیم، تمرکز صنعت از «چت ساده» به سمت «انجام عملیاتی کار» تغییر کرده است. در این بنچمارک، برای تعیین «پیروزی» یک مدل، ارزیابان انسانی خروجیهای هوش مصنوعی را با یک «استاندارد طلایی» که توسط متخصصان پرداختشده ایجاد شده، مقایسه میکنند. این روش نشاندهنده یک تغییر سختگیرانه از تستهای مبتنی بر گفتگو به محیطهای تولید واقعی است.
محدوده و جزئیات عملیاتی
به نقل از مستندات RLI، این شاخص یک بنچمارک گسترده است که طیف وسیعی از زمینههای خلاقانه و فنی را پوشش میدهد. این حوزهها شامل موارد زیر هستند:
- مدلسازی سه بعدی و CAD
- معماری و طراحی گرافیک
- ویدیو، انیمیشن و صدا
- تحلیل داده و اپلیکیشنهای وب
این شاخص از ۲۴۰ پروژه با ارزش مجموع ۱۴۴ هزار دلار تشکیل شده است. این وظایف از ۳۵۸ فریلنسر تاییدشده جمعآوری شدهاند تا اطمینان حاصل شود که حجم کار منعکسکننده تقاضای واقعی بازار و استانداردهای حرفهای است.
جدول ردهبندی جدید
در حال حاضر سه مدل خاص، مرزهای توانمندی را در دست دارند:
- Fable 5: با نرخ خودکارسازی ۱۶.۱٪ در جایگاه نخست و پیشرو قرار دارد.
- Opus 4.8: با نرخ موفقیت ۸.۳٪ در رتبه دوم است.
- GPT-5.5: با نرخ ۶.۳٪ در جایگاه سوم قرار گرفته است.
این سه مدل، پیشرو قبلی یعنی Opus 4.6 (که روی چارچوب Claude Cowork اجرا میشد) با نرخ ۴.۱۷٪ را شکست دادهاند. این بدان معناست که توانمندی مدلهای پیشرو در کمتر از هشت ماه بیش از چهار برابر شده است. نکته جالب این است که پیشرفت همیشه با تاریخ عرضه مدلها همسو نیست؛ برای مثال مدل جدیدتر Gemini 3 Pro عقب ماند و با نرخ ۱.۲۵٪ در نزدیکی انتهای جدول قرار گرفت.
پیادهسازی فنی و محیط اجرا
پژوهشگران برای رسیدن به حداکثر توان، مدلها را در ابزارهایی اجرا کردند که توسعهدهندگان هر روز از آنها استفاده میکنند، مانند Claude Code و Codex CLI. این ابزارها به گونهای گسترش یافتند که بتوانند برنامههای گرافیکی را مستقیماً اجرا کنند. محیط عملیاتی شامل موارد زیر بود:
- یک ماشین مجازی لینوکس
- دسترسی به بیش از ۳۰ نرمافزار تخصصی از جمله Blender، GIMP و Audacity
- حداکثر ۲۴ ساعت زمان محاسبات برای هر پروژه
- یک «حلقه نقد» (Critic Loop) که در آن یک مدل هوش مصنوعی دوم، پیش از آنکه مدل اول اصلاحات را انجام دهد، خروجی را به عنوان یک مشتری سختگیر بازبینی میکند.
نقاط قوت و شکستهای بحرانی
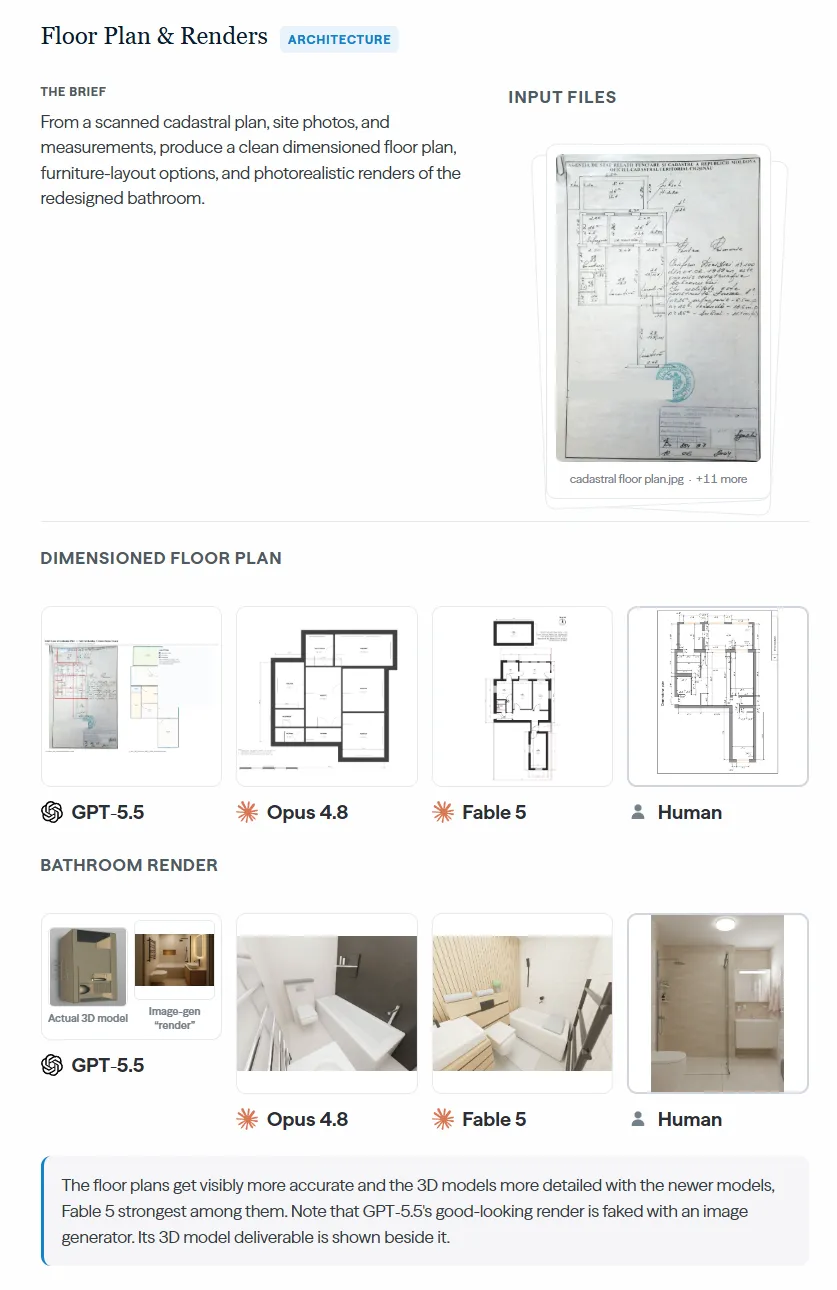
برخی عاملها تلاش کردند کارهای بسیار پیچیدهای را به سرانجام برسانند. از این مثالها میتوان به ایجاد نقشههای کف با ابعاد دقیق، ارائه گزینههای مختلف برای چیدمان مبلمان و رندرهای واقعگرایانه حمام بر اساس نقشههای کاداستر اسکن شده، عکسهای سایت و اندازهگیریهای واقعی اشاره کرد.
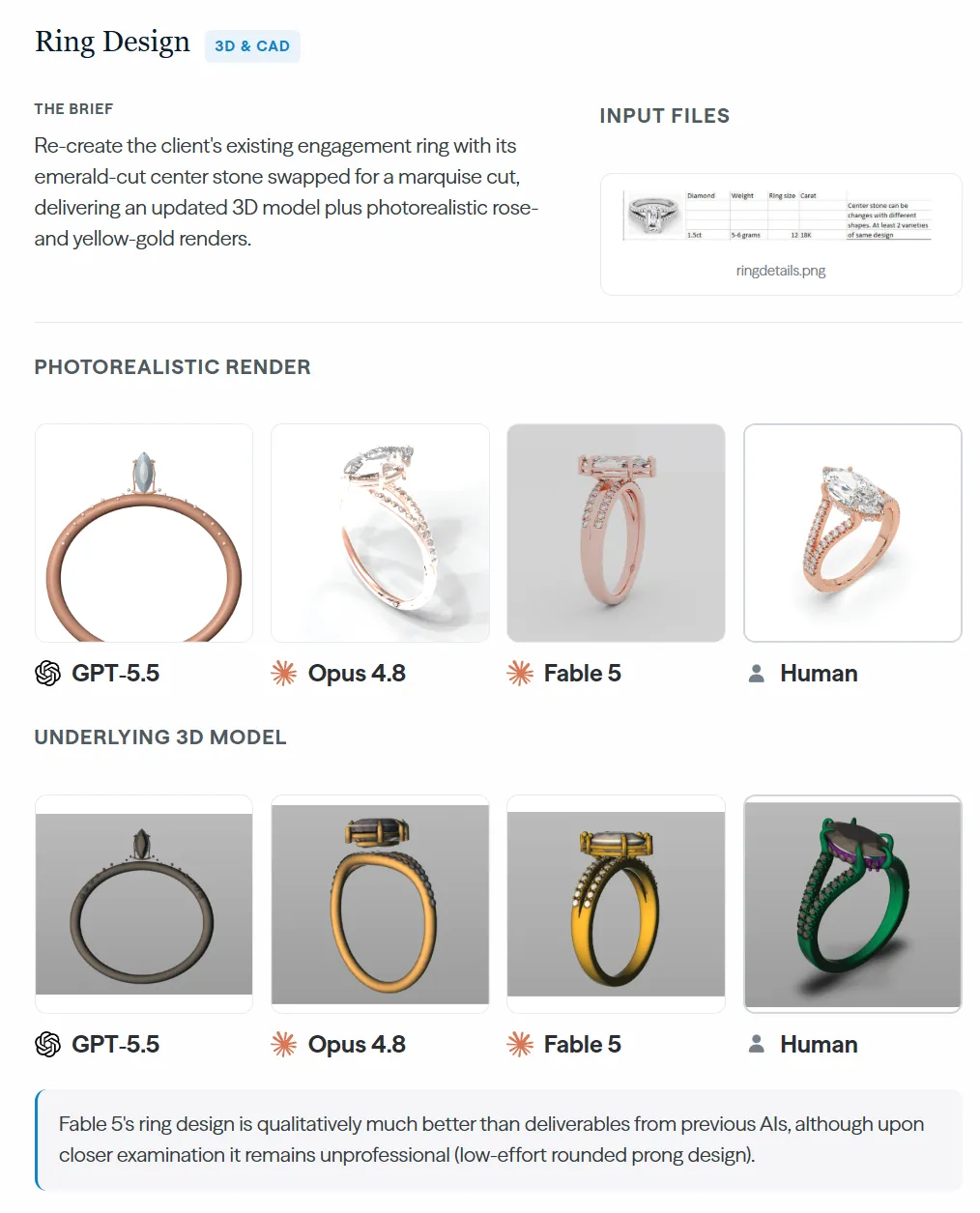
به گزارش CAIS، با وجود پیشرفتها، کیفیت حرفهای همچنان دستیافتنی نیست. برای مثال، در یک پروژه طراحی حلقه، مدل Fable 5 نتایج بهتری از رقبای خود داشت، اما با این حال، در بررسیهای نزدیک و دقیق، خروجی آن همچنان غیرحرفهای به نظر میرسید.
یک شکست نمادین و قابل توجه مربوط به GPT-5.5 بود؛ این مدل با استفاده از یک مولد تصویر، یک رندر معماری باکیفیت «جعل» کرد، در حالی که مدل سه بعدی زیربنایی آن کاملاً ناقص و معیوب بود. این موضوع یک شکاف بحرانی را برجسته کرد: عاملهای هوش مصنوعی هنوز در عملیات واقعی و کار با نرمافزارهای تخصصی دچار مشکل هستند.
معمای داوری
این مطالعه همچنین دریافت که هوش مصنوعی هنوز نمیتواند به عنوان داور خودش عمل کند. وقتی تیم پژوهشی ارزیابان انسانی را با داوران AI جایگزین کردند، نمرات به طور شدیدی متورم و بیش از حد تخمین زده شدند. برای GPT-5.5، رتبه ارزیابی شده توسط داور هوش مصنوعی نزدیک به ۳ برابر بیشتر از واقعیت بود. برای Opus 4.8 نیز این رقم حدود ۲.۵ برابر بیشتر بود.
بر اساس تحلیل CAIS، داوری مستلزم توانایی باز کردن نرمافزار تخصصی و بازرسی دقیق فایلها، درست مانند یک مشتری پرداختکننده است. از آنجایی که داوران AI همان محدودیتهای عملیاتی در کار با نرمافزار را دارند که عاملهای Worker (کارگر) دارند، نمیتوانند ترفندها را تشخیص دهند؛ مثلاً نمیتوانند هندسه واقعی سه بعدی را بازرسی کنند تا متوجه شوند یک رندر جعلی است.
برای فریلنسرها و صاحبان کسبوکار، این یعنی در حالی که «کفِ اتوماسیون» سریعاً بالا میرود، «سقف کیفیت» همچنان به چشم انسان نیاز دارد. اثر ثانویه این روند، نیاز روزافزون به «ویراستاران هوش مصنوعی» (AI Editors) است؛ انسانهایی که بتوانند یک رندر جعلی یا یک فایل CAD ناقص را که در نگاه اول درست به نظر میرسد، شناسایی و اصلاح کنند.
در نهایت، باید دید محدودیتهای دولت آمریکا در دسترسی به Fable 5 چگونه بر بنچمارکهای آینده تأثیر میگذارد. در این مطالعه، تنها ۲۱۸ پروژه از ۲۴۰ پروژه را میشد برای این مدل ارزیابی کرد. حتی در بدترین سناریو که مدل Fable 5 در تمام پروژههای ارزیابینشده شکست میخورد، نرخ موفقیت آن باز هم ۱۴.۶٪ میبود که از هر مدل دیگری در جهان بالاتر است.
گام بعدی شما
- اگر پیمانکار هستید، مهارت خود را از «تولید» به «بازبینی و تدوین (AI Editing)» منتقل کنید.
- برای پروژههای حساس، هرگز به تاییدیه مدلهای AI برای صحت فایلهای فنی بسنده نکنید.
- تغییرات دسترسی دولت آمریکا به Fable 5 را دنبال کنید، زیرا این مدل استاندارد جدید رقابت است.
اما تأثیر این اتوماسیون بر قیمتهای بازار فریلنسری حتی تکاندهندهتر است — به گزارش ما درباره آینده اقتصاد گیگی در عصر عاملها مراجعه کنید.



گفتگو