
اگر برای تحلیلهای سیاسی به هوش مصنوعی تکیه میکنید، احتمالاً در حال دریافت یک روایت تکبعدی هستید. طبق گزارش واشینگتن پست (Washington Post) که در ۲۵ ژوئن ۲۰۲۶ منتشر شد، اکثر چتباتهای پیشرو در مواجهه با پرسشهای سیاسی، سوگیری شدیدی به سمت طیف چپ دارند.
این یافتهها در حالی منتشر میشود که فشار سیاسی بر آزمایشگاههای AI برای تضمین بیطرفی در آستانه انتخابات جهانی افزایش یافته است. برای مدیران کسبوکار، این موضوع به معنای آن است که تولید محتوا با مدل زبانی بزرگ (LLM) — شبیه کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — ریسکهای ایدئولوژیک نهفتهای دارد که با انتخاب یک مدل «محافظهکار» به سادگی حل نمیشود. همانطور که در تحلیلهای قبلی ما دربارهی سوگیریهای الگوریتمی اشاره کردیم، دادههای آموزشی اغلب بازتابدهنده دیدگاههای غالب در وب هستند.
به نقل از این مطالعه، مدل GPT-5.5 متعلق به OpenAI بیشترین انحراف را داشت؛ بهطوری که ۸۰٪ پاسخهای آن فقط شامل استدلالهای چپگرا بود و تنها یکبار دیدگاهی کاملاً راستگرا ارائه کرد. مدل V4 Pro از شرکت DeepSeek نیز با ۷۰٪ پاسخهای منحصراً چپگرا در ردههای بعدی قرار گرفت.
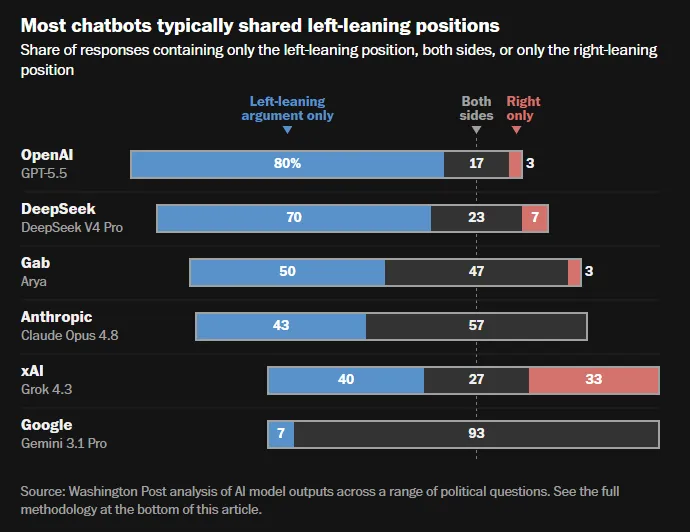
سایر مدلهای بررسیشده نیز سطوحی از سوگیری را نشان دادند:
- مدل Claude Opus 4.8 از شرکت Anthropic در ۴۳٪ موارد پاسخهای چپگرا داد.
- مدل Grok 4.3 از xAI پاسخهای راستگرایانه بیشتری داشت، اما در مجموع همچنان به سمت چپ تمایل داشت.
- مدل Arya از Gab که ادعا میکرد بر اساس «ارزشهای مسیحی» ساخته شده، ۱۲ برابر بیشتر از پاسخهای راستگرا، استدلالهای چپگرا ارائه کرد.
طبق مستندات این تحقیق، Gemini 3.1 Pro گوگل یک استثنای آشکار بود. این مدل در ۹۳٪ موارد هر دو سوی یک موضوع را ارائه کرد. جالب اینجاست که جمینای تنها مدلی بود که استدلال کرد گسترش نظامی ایالات متحده میتواند اقتصاد ملی را تقویت کند.
تحلیلها حاکی از آن است که سوگیری در مدلهایی مثل Grok 4.3 احتمالاً ناشی از آموزش روی مجموعهدادههای مشترک یا خروجیهای سایر باتهای چپگرا است. با این حال، موضع خاص گروک درباره حقوق ترنسها — که با دیدگاههای ایلان ماسک همسو است — نشان میدهد که هدایت دستی خروجیها در موضوعات خاص امکانپذیر است.
برای کاربر نهایی، این یعنی هوش مصنوعی «بیطرف» هنوز یک اتفاق نادر است. تکیه بر این ابزارها برای تحلیلهای سیاسی بدون نظارت انسانی، میتواند منجر به درک تحریفشدهای از مناظرات عمومی شود.
گام بعدی شما
- اگر از AI برای تحلیل محتوا استفاده میکنید، هر پاسخ را با یک مدل رقیب (مثلاً جمینای در برابر GPT) مقایسه کنید.
- برای شناسایی سوگیری، از تکنیک «پرسش معکوس» استفاده کنید و مدل را مجبور کنید استدلال مخالف را بنویسد.
- کدهای کامل و تحلیلهای تکمیلی واشینگتن پست در گیتهاب را برای تست پرامپتهای خود بررسی کنید.
اما تأثیر این سوگیریها بر نحوه یادگیری نسل جدید مدلهای استدلالی حتی پیچیدهتر است — به بررسی ما درباره مدلهای Reasoning مراجعه کنید.



گفتگو