
اگر مدل هوش مصنوعی شما هفتهها طول میکشد تا از محیط آموزش به تولید برسد، در حال از دست دادن مزیت رقابتی خود هستید. باید بدانید که بسیاری از مدلهای قدرتمند، به دلیل «اصطکاک خط لوله»، هرگز به دست کاربر نهایی نمیرسند.
انتقال مدل از PyTorch به سرور اغلب باعث جهش حافظه واحد پردازش گرافیکی (GPU) — موتور قدرتمندی که محاسبات سنگین را سریع انجام میدهد، شبیه به یک تیم بزرگ از حسابدارانی است که همزمان کار میکنند — میشود. همانطور که در تحلیلهای قبلی ما دربارهی بهینهسازی سختافزارهای هوش مصنوعی اشاره کردیم، گلوگاه اصلی همیشه در لایهی انتقال دادههاست. این شکاف، شبیه به ساختن یک ماشین مسابقهای در آزمایشگاه است که وقتی به جاده میرسد، با چالهها و سرعت محدود مواجه میشود.
NVIDIA در ۱۲ مه ۲۰۲۶ راهنمایی جامع منتشر کرد تا جلوی شکستهای زمان اجرا و افت کیفیت پنهان در استقرار مدلها را بگیرد. طبق اعلام این شرکت، راهکار اصلی در ادغام NVIDIA TensorRT و Dynamo-Triton است. برای بهینهسازی، موارد زیر توصیه شده است:
- اعتبارسنجی چکپوینتها در CI/CD
- حذف لایههای Dropout در گرافهای استنتاج
- استفاده از پلاگینهای C++/CUDA برای عملیاتهای پشتیبانینشده
- تعریف پروفایلهای ورودی پویا در TensorRT
- استفاده از کانتینرهای NVIDIA NGC برای جلوگیری از تداخل نسخهها
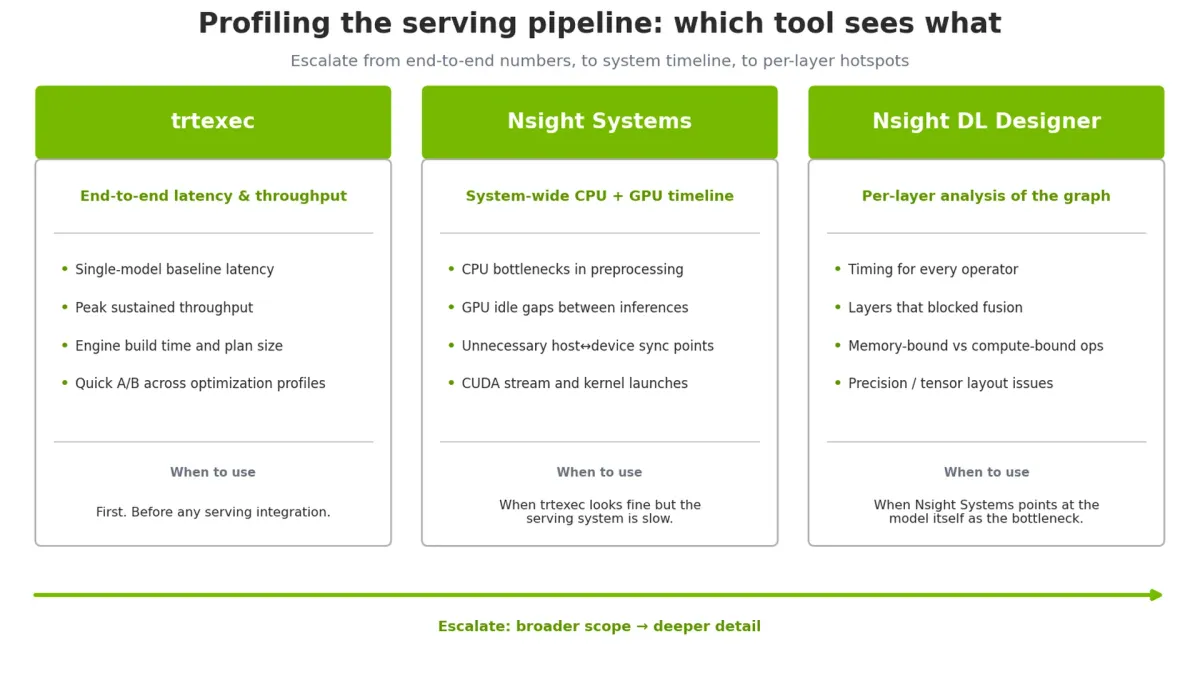
برای عیبیابی، استفاده از trtexec برای سنجش تأخیر، Nsight Systems برای تحلیل زمانبندی CPU/GPU و Nsight Deep Learning Designer برای شناسایی گلوگاههای لایهای پیشنهاد میشود.
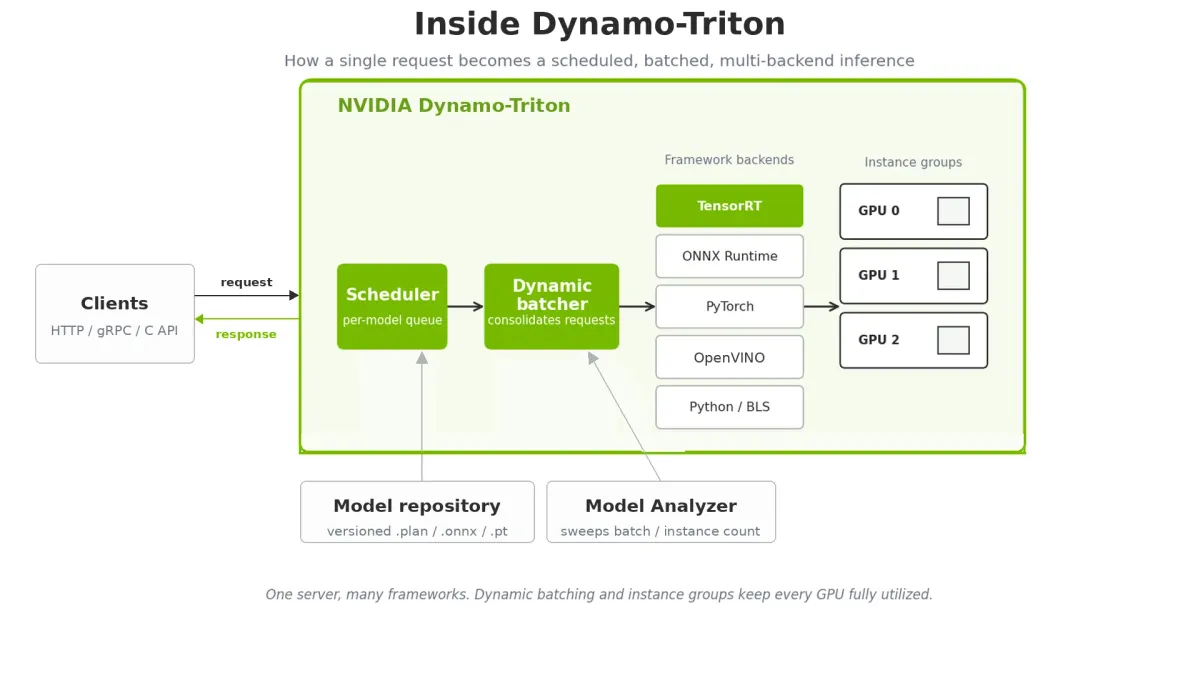
در نهایت، Dynamo-Triton بار تولید را از طریق دستهبندی پویا و نسخهبندی مدلها مدیریت میکند تا دسترسی بالا تضمین شود.
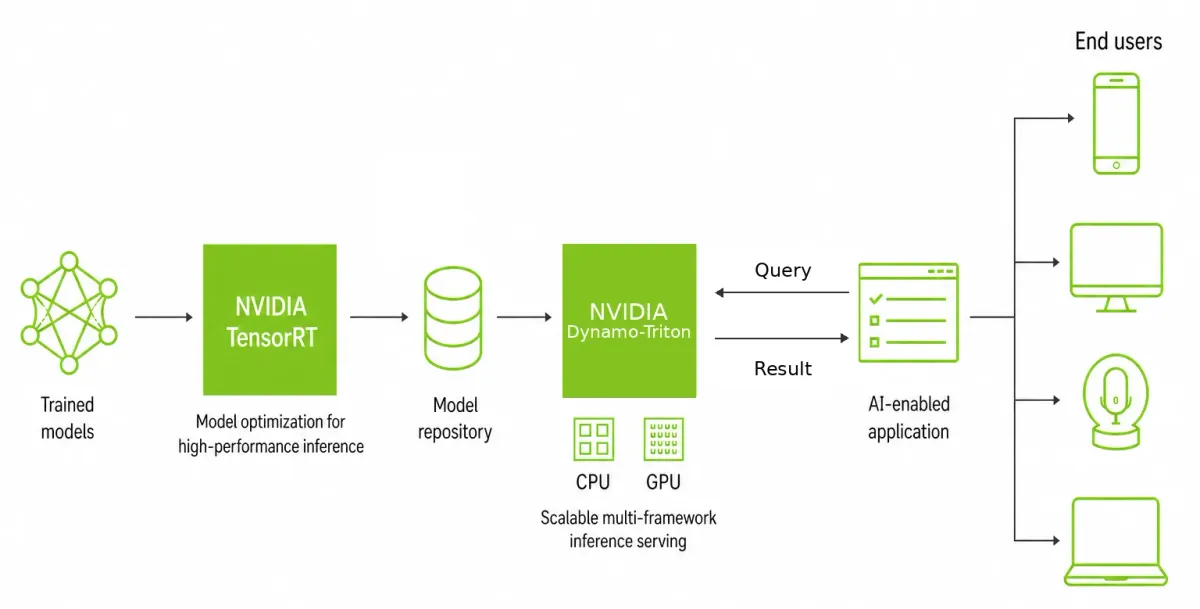
این تغییر، استقرار هوش مصنوعی را از یک «هنر دستی» به یک «خط لوله مهندسی» تبدیل میکند. برای شما، این به معنای استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، شبیه به خودِ آشپزی است، نه دورهی آموزش آشپز — ارزانتر، قبضهای ابری کمتر و پاسخهای سریعتر برای کاربران است.
گام بعدی شما
- یک کانتینر پیشساخته از کاتالوگ NGC دریافت کنید.
- مدلهای ONNX خود را با ابزار
trtexecتست کنید تا خط مبنای عملکرد را بسازید. - از Nsight Systems برای شناسایی گلوگاههای CPU/GPU استفاده کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو