
اگر برای مدیریت مدلهای مختلف، ۵ کلید API جداگانه در دست دارید، گردش کار شما ناکارآمد است. باید بدانید که مدیریت پراکندهٔ تأمینکنندگان، دیگر یک ضرورت فنی نیست، بلکه یک مانع است.
در ۷ ژوئن ۲۰۲۶، سرویس AIBridge روشی را معرفی کرد که اجازه میدهد ۱۴ مدل مختلف را تنها از طریق یک درگاه OpenAI-compatible متصل کنید. این ابزار در واقع یک مترجم جهانی است که هر مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — را به یک زبان واحد تبدیل میکند.
همانطور که در تحلیل قبلی ما دربارهی ریسکهای نشت داده در حالت Lockdown Mode شرکت OpenAI اشاره کردیم، هر نقطه اتصال جدید به یک سرویس خارجی، یک شکاف امنیتی احتمالی است. AIBridge با متمرکز کردن این اتصالات، این ریسک را مدیریت میکند. مدیریت چندین API فعلاً مثل این است که برای هر اتاق در یک خانه، کلیدی متفاوت داشته باشید و هر بار مجبور شوید کیف خود را برای پیدا کردن کلید درست بگردید.
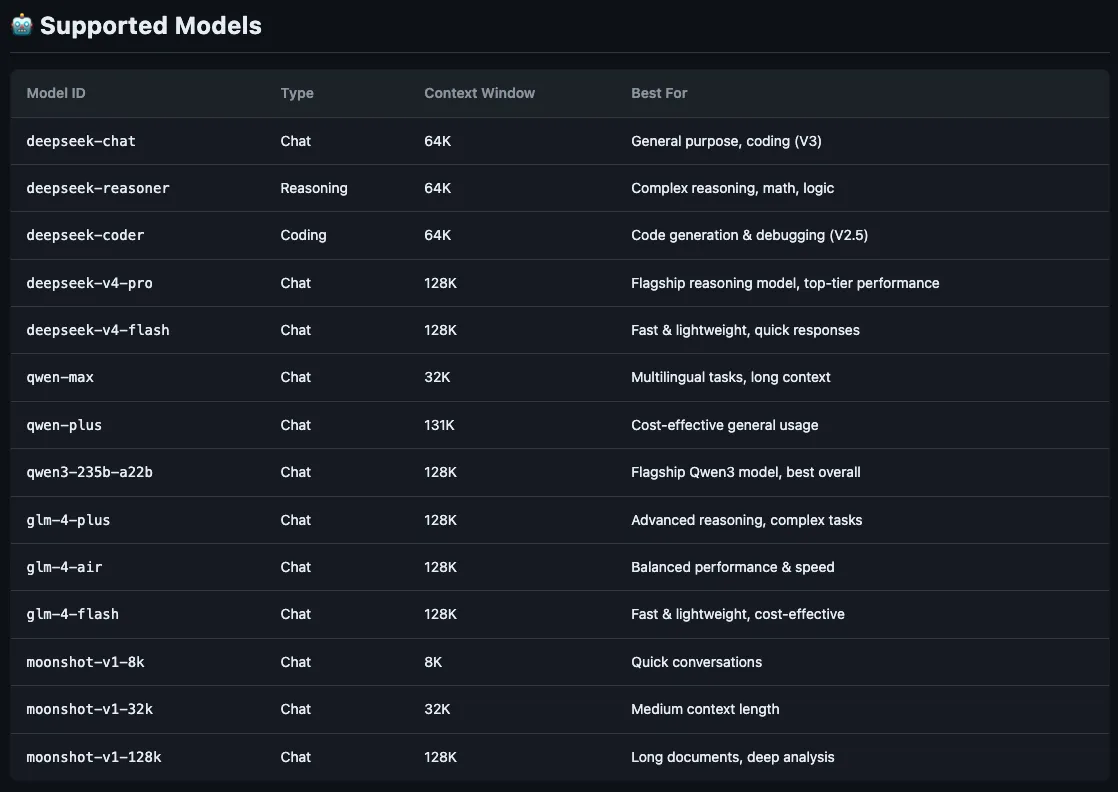
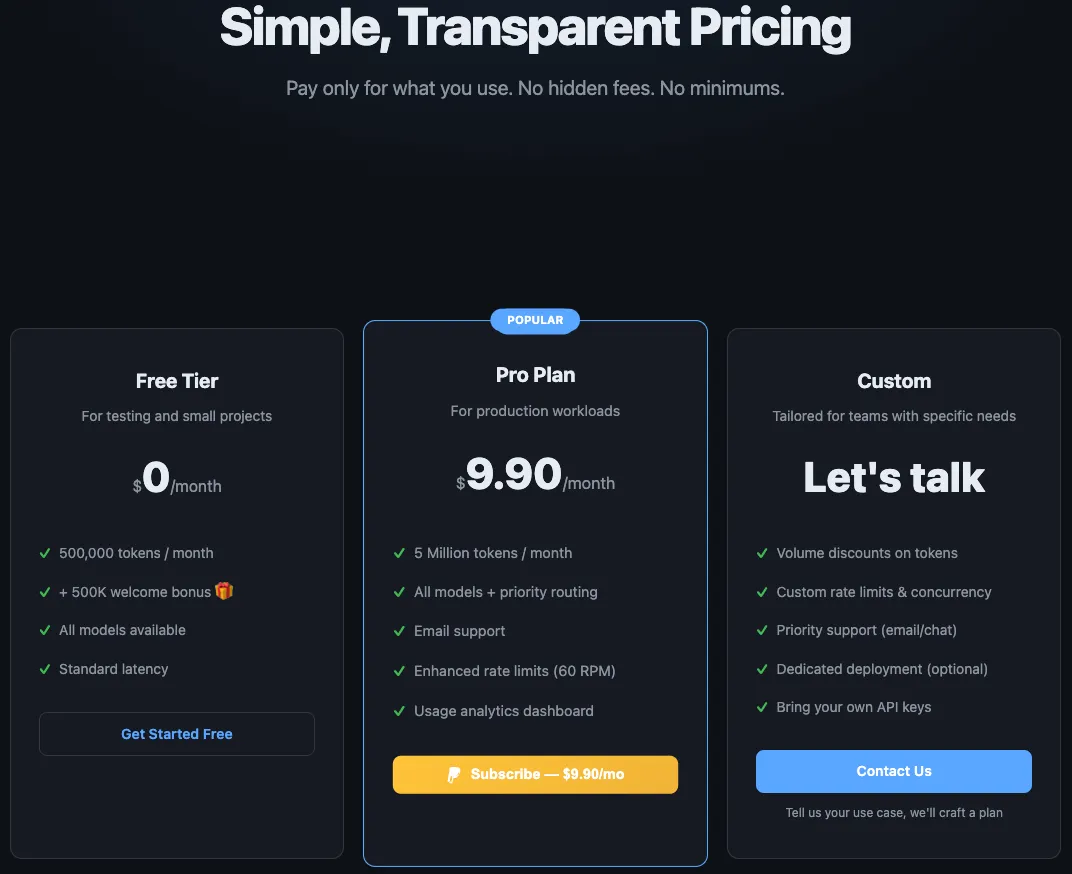
طبق مستندات AIBridge، برای شروع باید در سایت aibridge-api.com ثبتنام کنید تا ۵ میلیون توکن (Token) — تکههای کوچکی از متن که مثل برشهای یک کیک طولانی توسط مدل خورده میشوند — بهصورت رایگان دریافت کنید. طبق راهنمای dev.to، تنها کافی است base_url را در کلاینت پایتون OpenAI به آدرس https://aibridge-api.com/v1 تغییر دهید. این تغییر دسترسی به موارد زیر را ممکن میکند:
- DeepSeek: ۵ مدل از جمله
deepseek-v4-proوdeepseek-reasoner. - Qwen: ۳ مدل، شامل
qwen3-235b-a22b. - GLM: ۳ مدل، از جمله
glm-4-plus. - Moonshot: ۳ مدل با پنجره متنی از ۸ هزار تا ۱۲۸ هزار توکن.
این رویکرد سد ورود به «پرش بین مدلها» را میشکند. شما میتوانید بدون تغییر حتی یک خط کد در منطق برنامه، یک مدل استدلالی (Reasoning Model) — مدلی که قبل از جواب، یک قدم درنگ میکند و فکر میکند، شبیه شطرنجبازی که چند حرکت جلوتر را میبیند — را با یک مدل چندزبانه جایگزین کنید.
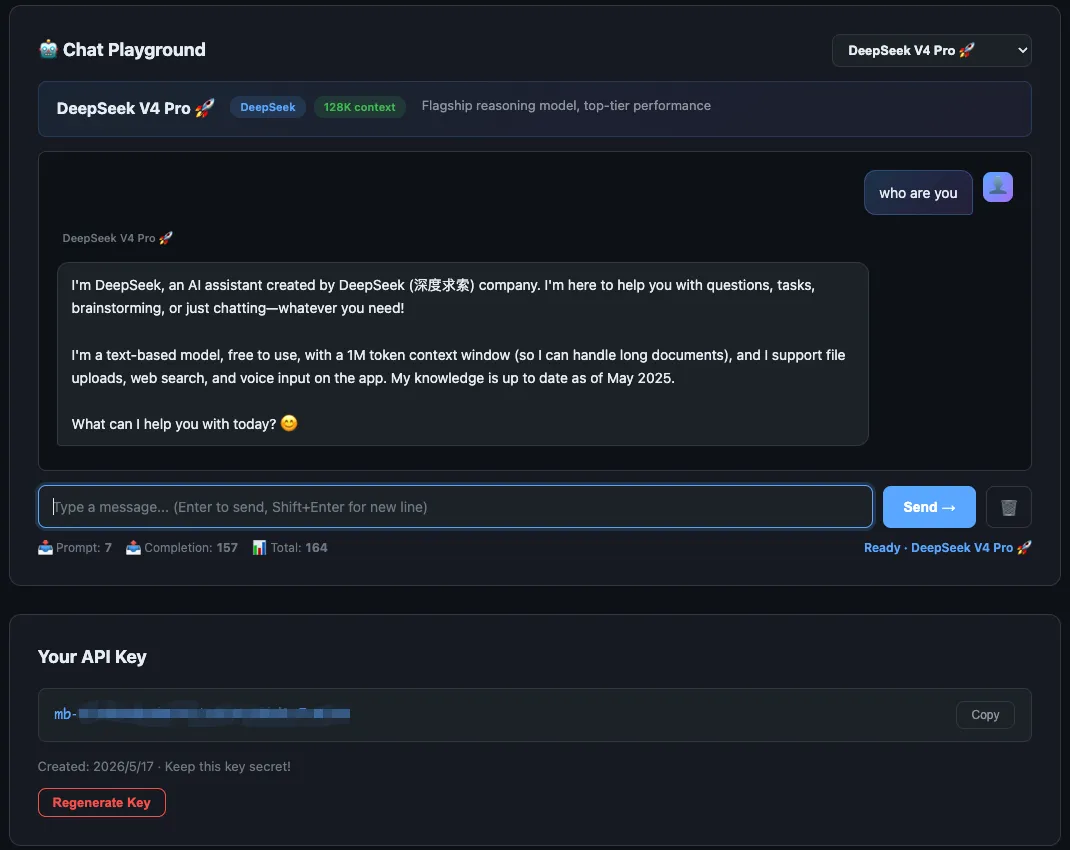
به گزارش منابع توسعهدهنده، این متد برای استودیوهای کوچک نرمافزاری تا ۹۰٪ در هزینههای اشتراک API صرفهجویی میکند. شما همچنین میتوانید لحظهی استنتاج (Inference) — یعنی همان لحظهای که مدل واقعاً جواب تولید میکند، شبیه خودِ آشپزی نه دورهی آموزش آشپز — را در محیط Playground تست کنید.
گام بعدی شما
- مدلهای مختلف را در محیط Playground سرویس تست کنید.
- تحلیلهای مصرف را بررسی کنید تا بفهمید کدام مدل برای کاربرد خاص شما بهینه است.
base_urlپروژههای فعلی خود را برای کاهش هزینهها بهروزرسانی کنید.
اما هزینههای استنتاج در مدلهای بازمتن حتی جذابتر است — به تحلیل ما دربارهی استقرار Llama 3 مراجعه کنید.



گفتگو