
تصور کنید یک گزارش سالانه ۵۰ صفحهای دارید و مجبورید آن را به تکههای کوچک تقسیم کنید تا هوش مصنوعی رشته کلام را گم نکند. شرکت بایدو (Baidu) در ۲۳ ژوئن ۲۰۲۶ با معرفی Unlimited-OCR این دشواری را به پایان رساند؛ مدلی که برای «پردازش یکمرحلهای افقهای بلند» (one-shot long-horizon parsing) طراحی شده تا اسناد حجیم را بدون از دست دادن انسجام ساختاری تحلیل کند.
بیشتر ابزارهای نویسهخوانی نوری (OCR) در مدیریت وظایف «افق بلند» — یعنی توانایی حفظ درک ثابت از چیدمان یک سند در طول صفحات متعدد — دچار مشکل میشوند. شبیه به کسی که سعی میکند یک کتاب را از روی تکههای پارهپاره بخواند و هر بار صفحه قبلی را فراموش کند. در حالی که نسخههای قبلی مانند Deepseek-OCR زیربنای این مسیر را ایجاد کردند، هدف این نسخه جدید گسترش این مرزهاست تا مدل بتواند پنجرههای زمینه عظیم را در یک جریان استنتاج واحد مدیریت کند.
زمینه پروژه
این پروژه بهطور رسمی در ۲۳ ژوئن ۲۰۲۶ منتشر شد و مقاله پژوهشی همراه آن در arXiv در دسترس قرار گرفت. برای حمایت از جامعه توسعهدهندگان، این مدل در ۲۲ ژوئن ۲۰۲۶ با ModelScope ادغام شد.
این تلاش بر پایه بنیادهای چندین پیشرو کلیدی بنا شده است. تیم توسعهدهنده صراحتاً از تأثیرات و ایدههای ارزشمند ارائه شده توسط مدلهای Deepseek-OCR، Deepseek-OCR-2 و PaddleOCR قدردانی کرده است.
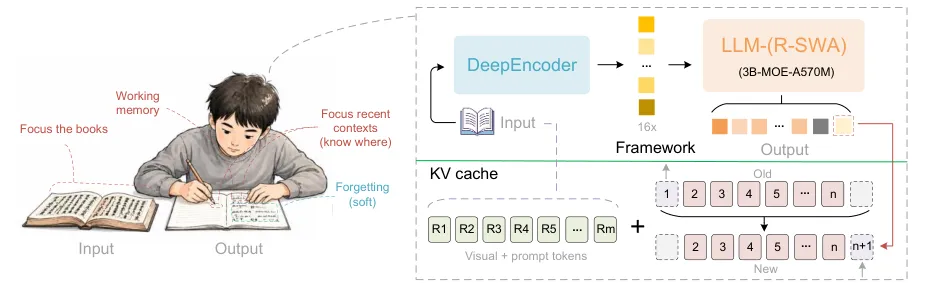
بر اساس مخزن گیتهاب پروژه، این مدل دو پیکربندی اصلی برای تصاویر تکصفحه پشتیبانی میکند: حالت «gundam» (که از اندازه تصویر ۶۴۰ پیکسل با قابلیت برش و اندازه پایه ۱۰۲۴ استفاده میکند) و حالت «base» (که از اندازه کامل ۱۰۲۴ پیکسل با غیرفعال کردن حالت برش استفاده میکند). برای اسناد چندصفحهای و فایلهای PDF، سیستم بهطور پیشفرض از پیکربندی پایه ۱۰۲۴ پیکسل استفاده میکند تا حداکثر جزئیات حفظ شود.
جزئیات فنی
مشخصات فنی برای استقرار این مدل عبارت است از:
- طول زمینه: پشتیبانی تا ۳۲,۷۶۸ توکن (Token) — تکههای کوچکی از متن که مدل آنها را پردازش میکند.
- سختافزار: تست شده روی GPUهای انویدیا با CUDA ۱۲.۹ و پایتون ۳.۱۲.۳.
- وابستگیهای اصلی: اتکا به torch ۲.۱۰.۰، torchvision ۰.۲۵.۰، transformers ۴.۵۷.۱ و Pillow ۱۲.۱.۱.
- کتابخانههای کمکی: استفاده از matplotlib ۳.۱۰.۸، einops ۰.۸.۲، addict ۲.۴.۰، easydict ۱.۱۳ و psutil ۷.۲.۲.
- پردازش PDF: استفاده از PyMuPDF ۱.۲۷.۲.۲ برای تبدیل صفحات PDF به تصویر با رزولوشن ۳۰۰ DPI.
- بکاِند استنتاج: سازگار با Hugging Face transformers و سرور SGLang برای استریم با کارایی بالا از طریق یک API سازگار با OpenAI.
برای جلوگیری از حلقههای تکراری متن که در OCRهای طولانی رایج است، بایدو یک پردازشگر لاجیت (Logit Processor) سفارشی پیادهسازی کرده است. ابزار DeepseekOCRNoRepeatNGramLogitProcessor از اندازه ngram برابر با ۳۵ و پنجرهای ۱۲۸ توکنی برای تصاویر تکصفحه، یا تا ۱,۰۲۴ توکن برای اسناد چندصفحهای استفاده میکند تا تضمین شود خروجی در توالیهای طولانی، روان و مستند باقی میماند.
برای توسعهدهندگان، این مدل هم در Hugging Face و هم در جامعه ModelScope در دسترس است. مدل را میتوان به صورت یک اسکریپت مستقل یا به عنوان یک سرور با استفاده از SGLang مستقر کرد. برای بهینهسازی حافظه و سرعت، استفاده از بکاِند توجه fa3 با اندازه صفحه ۱ و کسر حافظه استاتیک ۰.۸ توصیه میشود.
این چرخش به سمت پردازش افق بلند یعنی کاربران دیگر نیازی به ساخت خط لولههای پیچیده برای تکهبندی (Chunking) — یعنی بریدن متن به قطعات کوچک برای جا دادن در حافظه مدل — برای پردازش گزارشهای سالانه شرکتی یا قراردادهای حقوقی ندارند. با treating کردن یک PDF چندصفحهای به عنوان یک توالی پیوسته واحد، مدل میتواند جداولی که در چندین صفحه پخش شدهاند یا سرتیترهایی که کل یک بخش را پوشش میدهند، بهطور بهتری درک کند.
برای یک متخصص، این یعنی کاهش شدید «شکاف توهم» (hallucination gap)؛ حالتی که در آن هوش مصنوعی وقتی به صفحه دهم میرسد، محتوای بالای صفحه اول را فراموش میکند. در واقع OCR از یک ابزار ساده استخراج متن به یک موتور درک ساختاری تبدیل شده است.
این عرضه نشاندهنده حرکت به سمت هوش مصنوعی «سند-محور» (document-native) است؛ جایی که مدل کل فایل را به عنوان یک شیء واحد میبیند، نه مجموعهای از تصاویر جداگانه. این امر بهطور مؤثری سد فنی برای اتوماسیون دیجیتالسازی اسناد با حجم بالا را کاهش میدهد.
توسعهدهندگان اکنون میتوانند با فراخوانی baidu/Unlimited-OCR از Hugging Face و پیادهسازی پیکربندی سرور SGLang برای دستیابی به توان عملیاتی در سطح تولید، از جمله استنتاج دستهای (batch inference) از طریق infer.py با تنظیمات همزمانی قابل تغییر، مدل را آزمایش کنند.
گام بعدی شما
- اگر با اسناد حقوقی یا گزارشهای مالی حجیم سروکار دارید، مدل Unlimited-OCR را جایگزین خط لولههای تکهبندی قدیمی کنید.
- برای استقرار در محیط تولید، از بکاِند
fa3در SGLang استفاده کنید تا مصرف حافظه بهینه شود. - دقت مدل را در بازشناسی جداول چندصفحهای با مدلهای تکصفحهای مقایسه کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو