
اگر مدلهای هوش مصنوعی خود را در محیط عملیاتی اجرا میکنید، احتمالاً با کابوس «راهاندازی سرد» (Cold Start) دستوپنجه نرم کردهاید؛ چه بخواهید و چه نخواهید، رابطهای پیچیده با این پدیده دارید. تصور کنید یک راهاندازی سه دقیقهای، اساساً نحوه مقیاسبندی شما را تغییر میدهد. شما مجبورید GPUهایی را «گرم» نگه دارید که میتوانستند آزاد شوند. شما برای اینکه کاربر را منتظر نگذارید، سختافزار را بیش از حد تخصیص میدهید (Over-provisioning). شما دورههای خنک شدن (Cooldown) را طولانی میکنید، زیرا پایین آوردن سریع مقیاس، در موج بعدی ترافیک باعث ایجاد دردسر میشود. در نهایت، برنامه شما شروع به انباشت پیچیدگی حول یک مشکل واحد میکند: آمادهسازی مدل برای سرویسدهی به ترافیک با سرعت کافی.
یک Cold Start در یک کلاستر GPU حرفهای میتواند بین چند ثانیه تا پنج دقیقه زمان ببرد. Cerebrium این پارادایم را با معرفی سیستمی برای ثبت وضعیت حافظه (Memory Snapshotting) تغییر داد تا بارهای کاری CUDA را که کاملاً گرم شدهاند، در عرض چند ثانیه بازگرداند. این رویکرد یادآور تلاشهای مشابه در سطح سختافزار است، مانند زمانی که سامانه Dynamo Snapshot انویدیا توانست زمان Cold Start مدلهای زبانی را تا ۲۱ برابر کاهش دهد.
در اکثر محیطهای تولیدی AI، گلوگاه اصلی تنها «کشیدن ایمیج» یا دانلود ایمیج برنامه روی ماشین نیست. ما مشکل دانلود کانتینر را پیشتر حل کردهایم. در عوض، هزینه واقعی در «مقداردهی اولیه قطعی» (Deterministic Initialization) است که پس از قرارگیری ایمیج روی ماشین رخ میدهد. این مسیر مقداردهی اولیه شامل مواردی چون وارد کردن ماژولهای سنگین پایتون و PyTorch، بارگذاری وزنهای مدل و کپی آنها روی GPU، مقداردهی اولیه CUDA و اجرای مسیر گرمکننده چارچوب (Framework's warmup path) مانند torch.compile، کپچر گرافهای CUDA و مقداردهی اولیه KV cache است.
بر اساس مستندات فنی این شرکت، چون این مراحل در هر بار اجرا نتیجه یکسانی دارند — برای مثال وارد کردن PyTorch همیشه همان ماژولها را بارگذاری میکند و ساخت مدل همیشه همان بایتها را در حافظه GPU ایجاد میکند — Cerebrium تصمیم گرفت بهجای محاسبه مجدد در هر بار افزایش مقیاس (Scale-up)، وضعیت نهایی را «منجمد» کند.
این سازوکار شبیه به «ذخیره بازی» (Save State) در کنسولهای قدیمی است؛ بهجای شروع بازی از منوی اصلی، مستقیماً به قلب اکشن میروید. در اصطلاحات فنی، گرفتن یک نقطه بازرسی (Checkpoint) به معنای متوقف کردن اجرای تمام پردازشهای برنامه، رشتهها (Threads) و بهطور حیاتی، کارهای GPU است. سپس سیستم وضعیت موجود در حافظه (In-memory state) هر دو بخش CPU و GPU را به صورت فایلهای سریالشده در میآورد و آنها را در یک ذخیرهساز سریع و بادوام قرار میدهد.
فرآیند بازگردانی (Restore)، این مسیر را بهصورت معکوس طی میکند. سیستم فایلهای Checkpoint را میکشد، حافظه CPU و GPU را دوباره پر میکند (Rehydrate)، بخشهایی از وضعیت را که نمیتوانند از جابجایی جان سالم به در ببرند را تعمیر میکند و اجرای بار کاری را از حالت توقف خارج میکند. پردازش بازگردانده شده، همان زمان اجرای (Runtime) گرمشدهای است که پیشتر منجمد شده بود: PyTorch از قبل وارد شده، وزنهای مدل روی GPU مستقر هستند و کرنلها کامپایل شدهاند.
وسواس زیرساختی
تلاش Cerebrium برای حل مشکل Cold Start در چندین لایه از زیرساخت آنها گسترش یافته است. پیش از رسیدن به اسنپشاتهای حافظه، این تیم گلوگاههای دیگر را از طریق روشهای زیر بهینه کرد:
- طراحی ایمیژهای VM سفارشی که برای مقیاسپذیری سریعتر گرهها (Node scale-ups) بهینه شدهاند.
- ساخت یک رانتایم ایمیج سفارشی که بهطور خاص برای رسیدن به بوت زیر-ثانیهای کانتینرها ساخته شده است.
- ایجاد یک ارکستراتور با قابلیت دسترسی بالا (HA) و تأخیر کم برای مسیریابی بارهای کاری در مناطق و ابرهای مختلف.
- پیادهسازی اسنپشاتهای حافظه CPU و GPU برای بازگرداندن کانتینرهای کاملاً گرم در چند ثانیه.
این رویکرد جامع، نیازهای متنوع مشتریانی که بارهای کاری سنگین GPU را اجرا میکنند هدف قرار میدهد. این بارهای کاری شامل موارد زیر است:
- مدلهای زبانی بزرگ (LLMs)
- آواتارهای بلادرنگ (Real-time avatars)
- مدلهای تبدیل گفتار به متن (Transcription models)
- مدلهای انتشار (Diffusion models)
برای برخی از این بارهای کاری، استفاده از Memory Snapshotting زمان راهاندازی سرد را بیش از ۸۰٪ کاهش داده است. این تلاش برای بهینهسازی تأخیر، در راستای روندهای کلی صنعت است، همانطور که بهتازگی موتور Photon توانست تأخیر استنتاج مدلهای بینایی-زبانی را ۳۵٪ کاهش دهد.
معماری در لایهی رانتایم
این سیستم از یک رانتایم بسیار سفارشیشده بر پایه gVisor برای مدیریت این فرآیند استفاده میکند. برای پشتیبانی از Checkpointing، رانتایم بهگونهای گسترش یافت که بتواند بین رانتایم کانتینر و سندباکسِ در حال اجرای بار کاری قرار گیرد و بدین ترتیب کنترل کامل چرخه حیات کانتینر را در دست بگیرد.
بهطور معمول، یک کانتینر توالی ثابتی را دنبال میکند: Sandbox Create $ \rightarrow $ Sandbox Start $ \rightarrow $ Container Create $ \rightarrow $ Container Start. برای اینکه اسنپشاتینگ شفاف (Transparent) باشد، Cerebrium این توالی را تغییر داد. سیستم شروع واقعی سندباکس را به تعویق میاندازد تا در حالی که منتظر مرحله ایجاد کانتینر است، پاسخهای وضعیت را برای containerd ارسال کند و آن را راضی نگه دارد. این تنها نقطهای است که اطلاعات ایمیج در دسترس است تا تعیین شود آیا یک Checkpoint سازگار وجود دارد یا خیر.
دو جزء اصلی این جریان را هدایت میکنند:
- سرویس Checkpoint: یک سرویس در سطح گره (Node-level) که جنبههای عملیاتی را مدیریت میکند: دانلود Checkpointها، آپلود موارد جدید، کش کردن آنها بهصورت محلی روی میزبان، حذف Checkpointهای فاسد یا قدیمی و گزارش وضعیت بازگردانی.
- shim تغییریافته gVisor containerd: تصمیمگیرندهای است که ایجاد کانتینر را رهگیری (Intercept) کرده و تصمیم میگیرد که آیا فرآیند باید از طریق یک بوت عادی پیش برود یا با یک عملیات بازگردانی (Restore) جایگزین شود.

هنگامی که یک کانتینر شروع به کار میکند، shim باید به سؤالات مشخصی پاسخ دهد: کدام بار کاری در حال شروع است؟ آیا یک Checkpoint سازگار برای این ایمیج، نوع GPU، نوع ماشین و نسخه رانتایم وجود دارد؟ Checkpoint در کجا ذخیره شده است؟ آیا از قبل بهصورت محلی روی میزبان کش شده است؟ آیا باید بازگردانی کنیم یا به یک بوت پاک (Clean Boot) بازگردیم؟
غلبه بر پیچیدگیهای CUDA
بازگرداندن وضعیت GPU بهندرت یک فرآیند ساده و تمیز است، زیرا بارهای کاری واقعی دارای وابستگیهای خارجی هستند که از جابجایی جان سالم به در نمیبرند. یک اسنپشات میتواند رانتایم گرمشده را حفظ کند، اما نمیتواند کورکورانه هر وابستگی خارجی را حفظ نماید. اگر پردازشی بیدار شود و مسیری در سیستم فایل، سوکتی، آدرس IP یا هندل دستگاهی را پیدا کند که قبل از جابجایی معتبر بود اما اکنون نیست، با شکست مواجه خواهد شد.
Cerebrium برای اینکه این فرآیند را برای چارچوبهایی مانند vLLM قابل اعتماد کند، چندین مورد لبهای (Edge Case) بحرانی را شناسایی و حل کرد:
- وضعیت شبکه: اتصالات TCP باز به محیط رانتایم اصلی متصل هستند. این موضوع چارچوبهایی را که از IPهای خارجی برای Heartbeatها، هماهنگی Workerها یا ارتباطات Control-plane استفاده میکنند، میشکند. Cerebrium ارتباطات داخلی چارچوب را با استفاده از
VLLM_HOST_IP=127.0.0.1به loopback پین کرد. - چندپردازگی (Multiprocessing): چارچوبهای سرویسدهی پایتون که از
forkبرای Workerها استفاده میکنند، ممکن است توصیفگرهای فایل درایور NVIDIA را از والد نشتی دهند. این امر رانتایم را در مورد اینکه چه کسی مالک وضعیت GPU است گیج میکند و باعث میشود تصور کند GPU هنوز توسط پردازشهایی در حال استفاده است که نباید مانع Checkpointing شوند. راه حل، استفاده از متد spawn از طریقVLLM_WORKER_MULTIPROC_METHOD=spawnبود. - فایلهای رانتایم محلی: چارچوبها اغلب سوکتهای یونیکس، فایلهای موقت، فایلهای قفل و وضعیتهای هماهنگی را روی دیسکهای محلی ایجاد میکنند. اگر اینها بازگردانی نشوند، Workerها ممکن است بهطور بیصدا در ارتباطات داخلی شکست بخورند. Cerebrium وضعیت RPC حیاتی برای بازگردانی را به یک مسیر حفظشده منتقل کرد:
VLLM_RPC_BASE_PATH=/run/cuda-ckpt. - شرایط رقابتی (Race Conditions): تیم یک شرط رقابتی در پشته شبکه TCP کشف کرد که باعث میشد شبکه در زمان دریافت بستههای زیاد طی Checkpointing از کار بیفتد. آنها همچنین یک Race Condition را حل کردند که در صورت طولانی شدن Checkpoint بیش از چند ثانیه، باعث کرش gVisor در هنگام اجرا در containerd میشد.
- تزریق دستگاه (Device Injection): برای پایداری، پیادهسازی تزریق Container Device Interface (CDI) برای GPUهای NVidia مورد نیاز بود.

گلوگاه ذخیرهسازی
به دلیل حجم عظیم Checkpointها — برای مثال یک بار کاری تست ۹ گیگابایتی رایج است، در حالی که بازگردانی Deepseek V4 FP8 با vLLM میتواند ۶۴۰ گیگابایت باشد — لایه ذخیرهسازی مهمترین تصمیم طراحی است. بازگردانی تنها زمانی ممکن است که جابجایی دادهها سریعتر از یک Cold Start باشد.
در بنچمارکهای انجام شده روی نمونههای g5.12xlarge با یک کانتینر ۹ گیگابایتی، یک Cold Start کامل vLLM تقریباً ۵۰ ثانیه زمان برد. بازگردانی از یک اسنپشات این زمان را به مقادیر زیر کاهش داد:
- ۲.۲۵ ثانیه هنگام کشیدن دادهها از S3 (گزینه پیشفرض برای قابلیت جابجایی بین ابرها و مناطق).
- ۹ ثانیه هنگام استفاده از کش NVMe محلی.
برای بهینهسازی بیشتر عملکرد، Cerebrium بر روی آنچه «نباید» اسنپشات شود تمرکز کرد:
- مدیریت KV Cache: حافظه KV Cache مربوط به درخواستهای خاص است و میتواند بسیار بزرگ باشد. حفظ آن باعث کند شدن آپلود و بازگردانی اسنپشاتها میشود. با قرار دادن vLLM در وضعیت «Sleep Mode» پیش از اسنپشات، این وضعیت گذرا رها میشود. این کار بهطور چشمگیری اندازه اسنپشات را کاهش داده و عملکرد بازگردانی را بهبود میبخشد.
- کلیدگذاری سازگاری (Compatibility Keying): اسنپشاتهای حافظه GPU مانند ایمیجهای کانتینر قابل جابجایی (Portable) نیستند. آنها به نوع خاص GPU، معماری CPU، نوع ماشین، نسخه درایور/رانتایم و نسخه gVisor وابسته هستند. یک Checkpoint ایجاد شده روی یک سختافزار خاص نمیتواند روی سختافزار دیگری بازگردانده شود. بنابراین، Checkpointها بر اساس سازگاری کلیدگذاری شدهاند.
- زمانبندی و آمادگی: Checkpointها به یک نمای سازگار از حافظه نیاز دارند. اگر کارهای CUDA در حین اسنپشات در حال اجرا باشند، نتیجه ممکن است ناسازگار باشد. این امر مستلزم یک مرحله آمادگی (Readiness) صریح است: بارگذاری مدل، اجرای گام گرمکننده، انتظار برای اتمام کامپایل یا کپچر گراف CUDA و سپس فعال کردن Checkpoint.
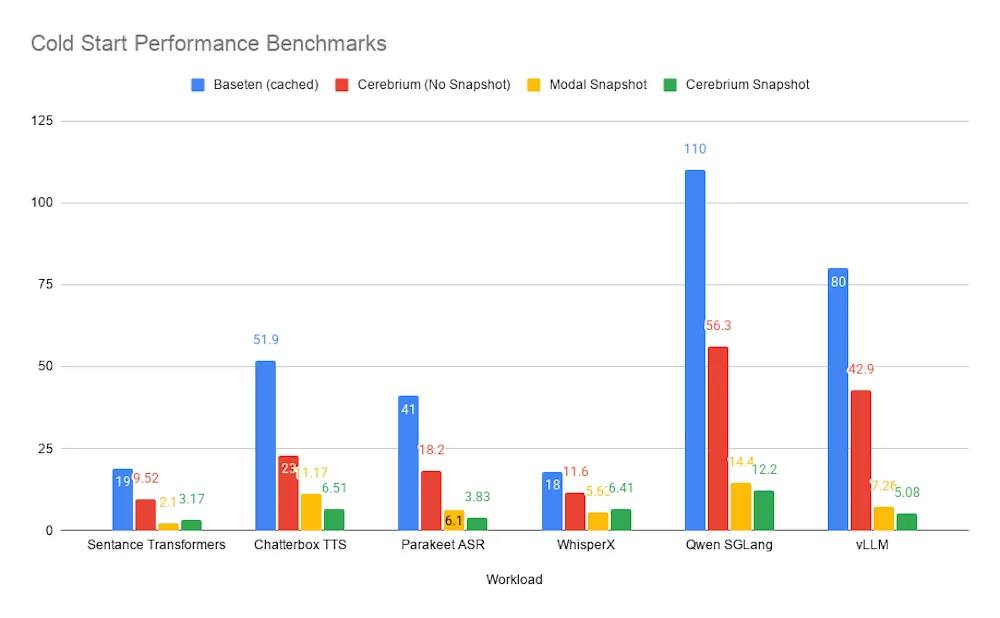
نتایج بنچمارک
Cerebrium سیستم خود را در مقابل Baseten و Modal در ۶ بار کاری متنوع طی یک دوره ۲۴ ساعته تست کرد و برای هر کدام ۱۰۰ درخواست Cold-start را روی کلاسهای GPU یکسان (مانند A10 و L40s) اجرا نمود.
در مقایسه با عملکرد بدون اسنپشات خود، Cerebrium زمان Cold Start را بهطور متوسط ۷۱٪ کاهش داد و در مورد vLLM این کاهش تا ۸۸٪ بود. در مقایسه با رفتار Cold-start کششدهی Baseten — که زمان دانلود را کاهش میدهد اما مقداردهی اولیه چارچوب یا کپچر گراف CUDA را حذف نمیکند — Cerebrium بهطور متوسط ۸۵٪ سریعتر و در vLLM تا ۹۴٪ سریعتر بود.
در مقابل Modal، نتایج برتری شدیدی را در هر دو مورد سرعت و قابلیت اطمینان نشان داد:
- زمان بازگردانی p0: Cerebrium در ۴ مورد از ۶ بار کاری زمان پایینتری داشت و میانگین زمان بازگردانی p0 در کل مجموعه حدود ۲۱٪ کمتر بود.
- عملکرد در بدترین حالت: Cerebrium در تمام ۶ بار کاری، کمترین زمان حداکثری بازگردانی را داشت و میانگین حداکثر زمان بازگردانی حدود ۲۷٪ کمتر از Modal بود.
این ثبات حیاتی است زیرا یک بازگردانی کند میتواند تجربه کاربر نهایی را در طول یک پیک ترافیکی نابود کند.
این تغییر فنی، اقتصاد GPUهای بدون سرور (Serverless) را تغییر میدهد. توسعهدهندگان اکنون میتوانند در زمان کاهش ترافیک، با شدت بیشتری به مقدار صفر (Scale down to zero) بروند، در هنگام بازگشت تقاضا سریعاً بازگردانی کنند و از نگه داشتن GPUهای گرانقیمت تنها برای محافظت از کاربران در برابر «جریمه Cold Start» اجتناب کنند. این امر بهرهوری بهتر و هزینههای زیرساختی پایینتری را تضمین میکند.
حرکت به سمت ماندگاری در سطح حافظه (Memory-level persistence) نشان میدهد که آینده زیرساختهای AI کمتر درباره «بوت کردن» (Booting) و بیشتر درباره «از سر گیری» (Resuming) است. با رشد مدلها، هزینه مقداردهی اولیه افزایش مییابد و این امر بازگردانی وضعیت (State-restoration) را برای هر پلتفرمی که به دنبال الاستیسیته واقعی بدون سرور است، به یک ضرورت تبدیل میکند.
برای مشاهده اینکه این موضوع چگونه بر تأخیر مدل خاص شما اثر میاندازد، میتوانید مخزن مثالهای Cerebrium را بررسی کنید یا مستندات Checkpointing آنها را مطالعه نمایید.
گام بعدی شما
- بررسی مخزن مثالهای Cerebrium برای تست تأخیر مدلهای خاص خود.
- مطالعه مستندات Checkpointing برای درک نحوه تعریف نقاط readiness در مدلهای سنگین.
- ارزیابی استراتژی scaling-to-zero در پروژههای فعلی خود برای کاهش هزینههای GPU.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو