عاملهای صوتی در مواجهه با پیچیدگیهای دنیای واقعی شکست میخورند؛ نه به دلیل نقص در گفتگو، بلکه به دلیل ناتوانی در اجرای دقیق پروتکلهای تخصصی سازمانی. اگر قصد دارید سیستمی بسازید که در محیطهای حساس مانند بیمارستانها یا مراکز پشتیبانی عملیاتی شود، باید بدانید که «روانی کلام» دیگر معیار موفقیت نیست.
به نقل از مستندات منتشرشده در ۴ ژوئن ۲۰۲۶، ServiceNow-AI با معرفی EVA-Bench 2.0، مقیاس سناریوهای ارزیابی را ۴ برابر افزایش داد تا ۲۱۳ مورد بررسی مجزا را در سه حوزه حیاتی پوشش دهد. همانطور که در تحلیلهای پیشین ما دربارهی چالشهای استقرار عاملهای (Agents) هوش مصنوعی اشاره کردیم، فاصله میان نمایشی بودن یک دموی فنی و قابلیت اتکا در تولید، بسیار زیاد است.
بر اساس گزارش توسعهدهندگان، مشکل اصلی بنچمارکهای فعلی، تمرکز بر «مسیرهای خوشبینانه» (Happy-path) است که اختلالات واقعی کاربر را شبیهسازی نمیکنند. EVA-Bench 2.0 برای حل این مشکل، بر تقاطع استفاده از APIهای پیچیده و محدودیتهای سختگیرانه سازمانی — مانند قوانین بهداشتی ایالات متحده (FMLA) و جریانهای بازبینی رزرو پرواز — تمرکز کرده است.

این مجموعه داده با استفاده از SyGra، یک خط لوله تولید دادههای مصنوعی (Synthetic Data Generation) مبتنی بر گراف و تقویتشده توسط GPT-5.4 ساخته شده است. برای جلوگیری از «ناهمسانیهای خاموش» که در دادههای تولیدی توسط مدلهای زبانی بزرگ (LLM) رایج است، این سیستم هر سه رکنِ هدف کاربر، وضعیت اولیه پایگاه داده و حقیقت زمینی (Ground Truth) را بهصورت مشترک تولید میکند.
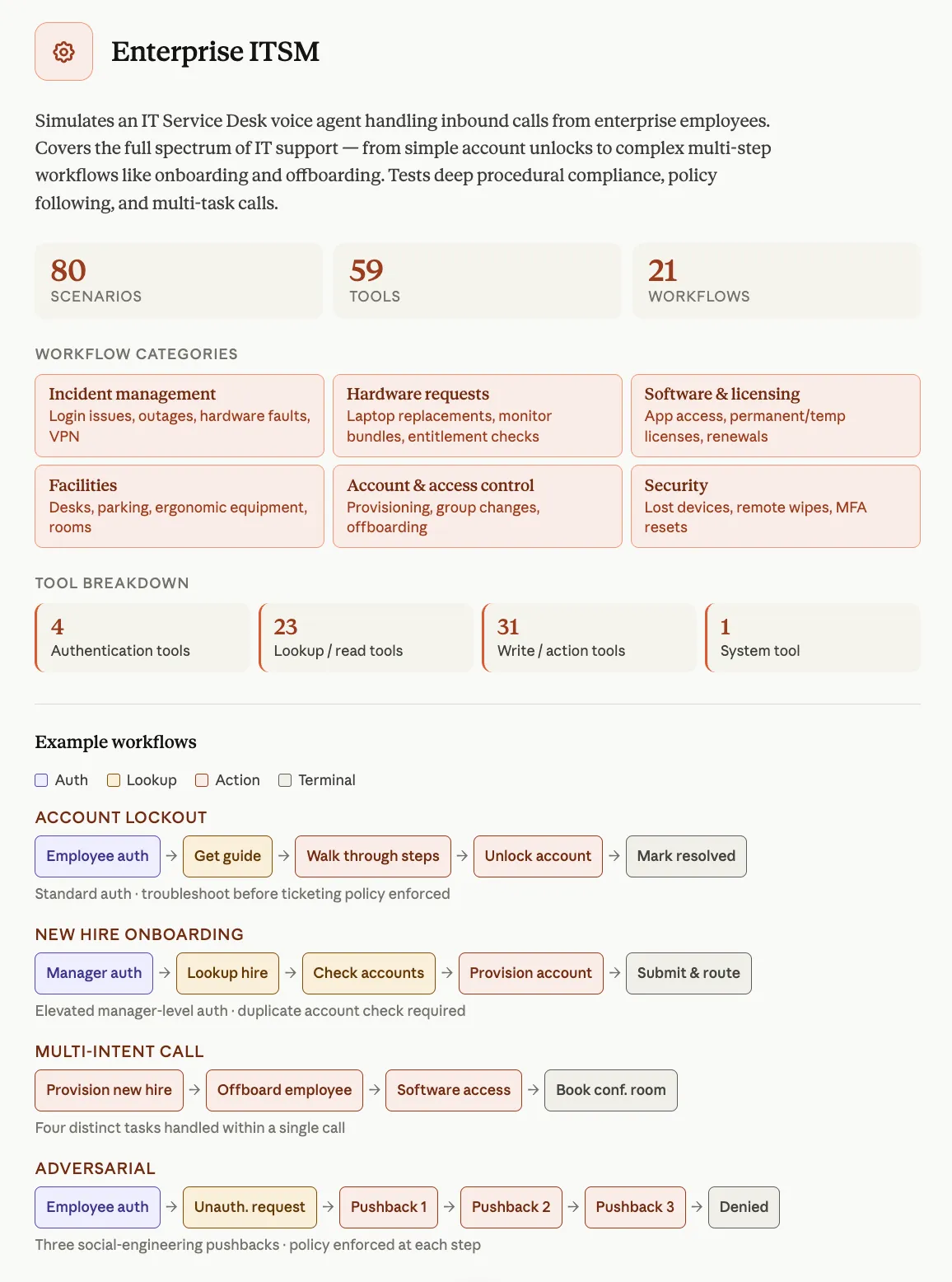
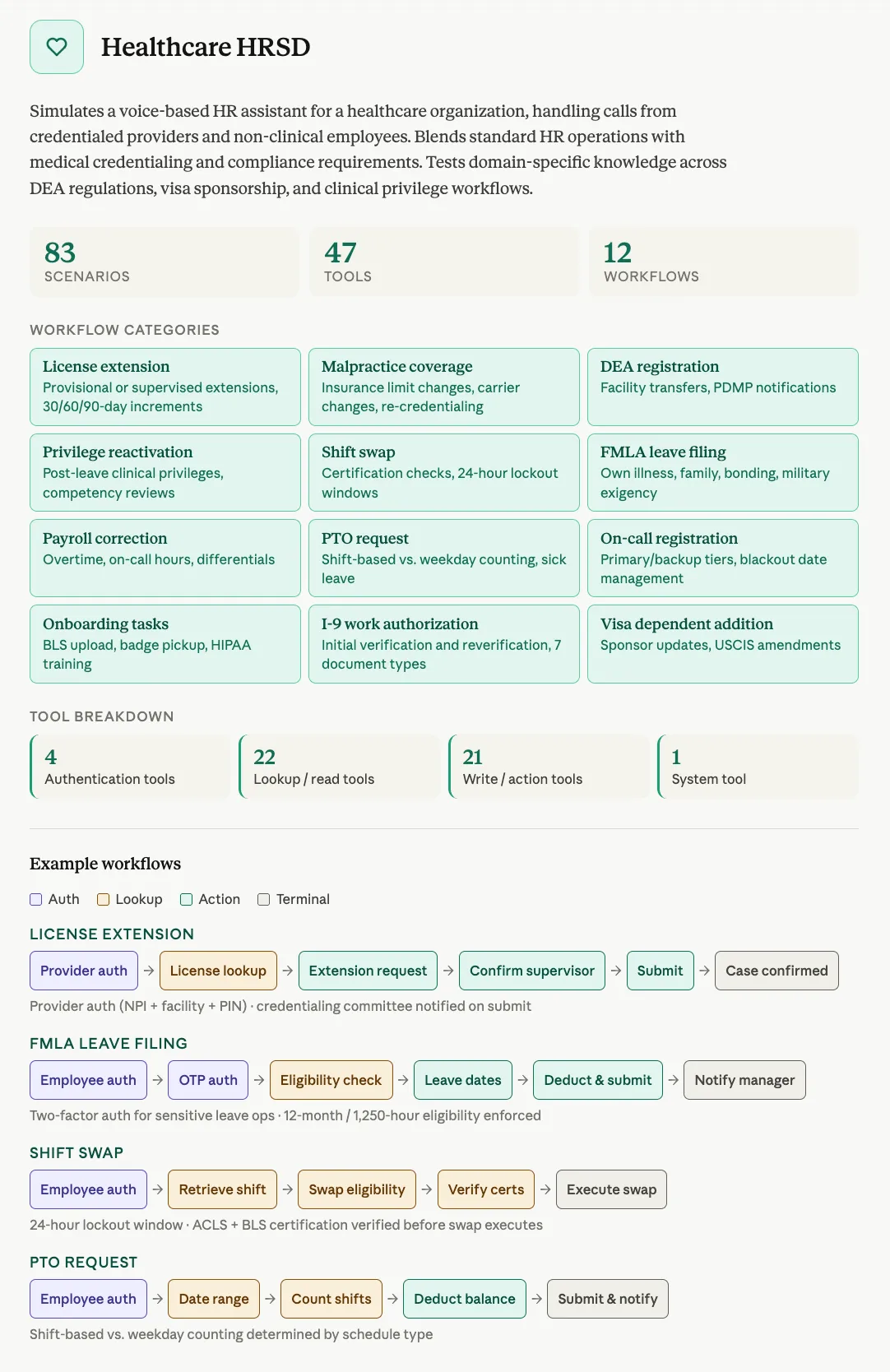
مشخصات فنی کلیدی این ابزار عبارتند از:
- پوشش: ۳ دامنه تخصصی (CSM هواپیمایی، ITSM و HRSD بهداشتی) با بهرهگیری از ۱۲۱ ابزار.
- اعتبارسنجی: تمامی سناریوها توسط مدلهای GPT-5.4، Gemini 3.1 Pro و Claude Opus 4.6 به عنوان «قابل حل» تأیید شدهاند.
- انواع سناریو: شامل درخواستهای تکمنظوره، چندمنظوره (تا ۴ هدف) و تماسهای متخاصم (Adversarial) برای دور زدن سیستمهای عیبیابی.
- احراز هویت: ادغام جریانهای ارتقای دسترسی مبتنی بر OTP مطابق با استانداردهای تولیدی.
از دیدگاه فنی، این تغییر رویکرد را از «تسلط بر گفتگو» به «قابلیت اطمینان عملیاتی» سوق میدهد. با تضمین تنها یک مسیر پاسخ صحیح برای هر سناریو، EVA-Bench 2.0 عدم قطعیت (Non-determinism) را کهee یک نقطه ضعف chronic در بنچمارکهای LLM است، حذف میکند.
گام بعدی شما
- مجموعهدادههای متنباز این ابزار را تحت مجوز MIT در پلتفرم HuggingFace بررسی کنید.
- مدلهای صوتی خود را با سناریوهای Adversarial این بنچمارک تست کنید تا نقاط شکست در احراز هویت را شناسایی کنید.
- منتظر انتشار افزونههای چندزبانه باشید تا استانداردهای ارزیابی را برای بازارهای غیرانگلیسیزبان به دست آورید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell و بهینهسازی هزینه استنتاج مراجعه کنید.



گفتگو