
تصور کنید ابزاری دارید که نه تنها کد مینویسد، بلکه مثل یک مهندس ارشد، پیچیدهترین حفرههای امنیتی سیستمهای جهانی را میبیند و میبندد. این دقیقاً همان ادعایی است که OpenAI با معرفی خانواده مدلهای جدید خود به دنبال آن است.
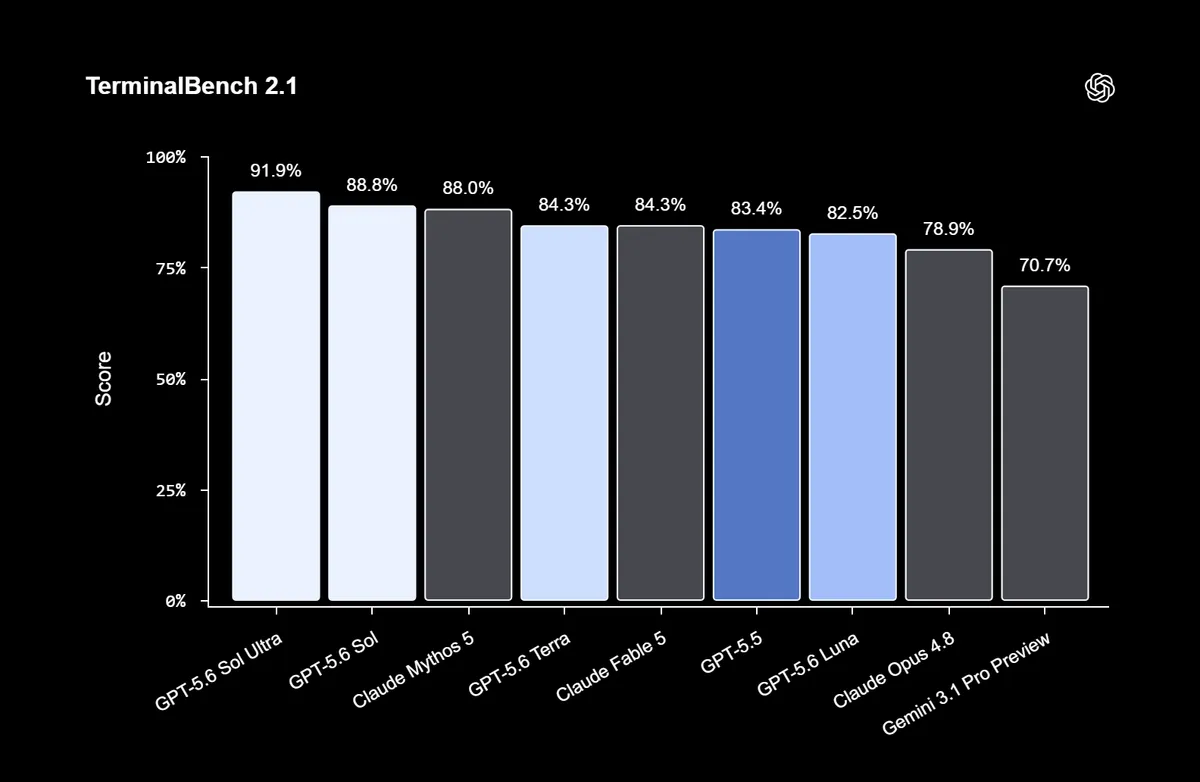
طبق گزارش the-decoder.com، مدل پرچمدار GPT-5.6 Sol Ultra در ۲۶ ژوئن ۲۰۲۶ با کسب امتیاز ۹۱.۹ درصد در محک Terminal-Bench 2.1، رقیب دیرینه خود یعنی Claude Mythos (با ۸۸ درصد) را پشت سر گذاشت. این پیشتازی در کدنویسی عاملمحور (Agentic) — یعنی سیستمی که مثل یک کارمند مستقل، هدف را میگیرد و مراحل رسیدن به آن را خودش مدیریت میکند — جایگاه OpenAI را در صدر جدول بازگرداند و همزمان تواناییهای این مدل را در وظایف سطح بالای امنیت سایبری با رقبایش برابر کرد. این دستاوردهای فنی در ادامه مقایسههای دقیقی قرار دارد که برتری مدل Sol در استدلالهای عاملمحور و کاهش چشمگیر توکنهای مصرفی در حملات سایبری نسبت به Mythos را نشان میدهد.
زمینه و فضای نظارتی
این عرضه در بازاری بیثبات صورت میگیرد که در آن دولت ایالات متحده هر روز بیشتر بر دسترسی به مدلها کنترل اعمال میکند. پیش از این، همین دولت شرکت Anthropic را مجبور کرد تا مدل Fable 5 خود را از بازار جمع کند. در نتیجه، دسترسی به GPT-5.6 Sol در حال حاضر تنها برای شرکای منتخب از طریق API و Codex و آن هم طبق دستور صریح دولت ایالات متحده امکانپذیر است.
OpenAI نارضایتی خود را از این محدودیتها پنهان نمیکند. این شرکت در بیانیهای صریح نوشت: «ما معتقد نیستیم فرآیند دسترسی دولتی باید به پیشفرض بلندمدت تبدیل شود. این کار بهترین ابزارها را از دسترس کاربران، توسعهدهندگان، سازمانها، مدافعان سایبری و شرکای جهانی که به آنها نیاز دارند، دور میکند.»
همانطور که در تحلیل قبلی ما دربارهی پروژه Jalapeño اشاره کردیم، OpenAI برای کاهش وابستگی به سختافزارهای انویدیا در حال متنوعسازی زیرساختهای خود است؛ اما حالا با یک سد نرمافزاری مواجه شده است: گلوگاههای توزیع نرمافزار که توسط نظارتهای فدرال ایجاد شدهاند.
لایههای مدل و منطق عملیاتی
برای مدیریت انتظارات و هزینهها، OpenAI یک ساختار نامگذاری سهلایه جدید معرفی کرده است تا با ساختار مورد استفاده در مدلهای Claude هماهنگ شود. در این سیستم، عدد (x.6) نشاندهنده نسل مدل است، در حالی که نامها نشاندهنده لایههای عملکردی دائمی هستند:
- Sol: پرچمدار سطح بالا برای حداکثریترین عملکرد.
- Terra: معادل GPT-5.5 اما با نصف هزینه استنتاج.
- Luna: گزینهای ارزان و اقتصادی برای تسکهای حجیم با پیچیدگی کم.
علاوه بر این، مدل Sol دارای حالت «max» برای مدل استدلالی (Reasoning Model) — شبیه شطرنجبازی که قبل از هر حرکت، چندین گام جلوتر را میبیند — و حالت «ultra» است که برای گردشهای کاری پیچیده، زیر-عاملهای موازی (Parallel Sub-agents) را مستقر میکند تا وظایف را بهصورت توزیعشده پیش ببرد.
جزئیات بنچمارکها و عملکرد
در بررسی دقیقتر بنچمارکها، تسلط Sol در کدنویسی عاملمحور مشهود است. در Terminal-Bench 2.1، نسخه استاندارد Sol امتیاز ۸۸.۸ درصد را به دست آورد، در حالی که Fable 5 با ۸۴.۳ درصد و Gemini 3.1 Pro Preview گوگل با ۷۰.۷ درصد بسیار عقبتر بودند.
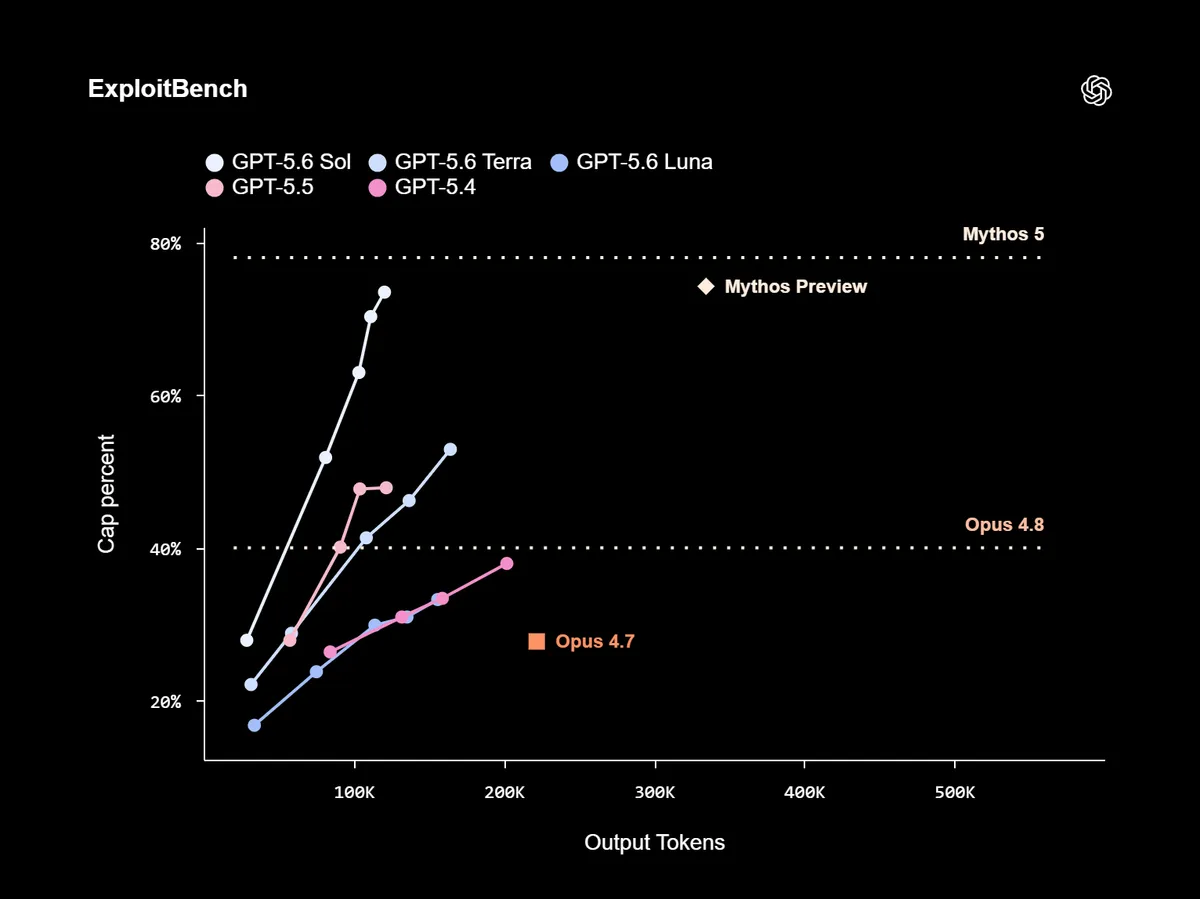
در حوزه ژنومیک، Sol در GeneBench v1 با کسب امتیاز ۳۰ درصد (در برابر ۲۲ درصد بهترین حالت در GPT-5.5) برتری یافت، در حالی که توکن (Token) — تکههای کوچکی از متن که شبیه برشهای یک کیک طولانی هستند و مدل آنها را میخواند — کمتری مصرف کرد. همچنین در ExploitBench، این مدل توانست عملکرد Claude Mythos Preview را به बराबरी بکشد و حفرههای موتور V8 جاوااسکریپت گوگل را برای اجرای کامل کد (Full Code Execution) شناسایی کند، در حالی که تنها یکسوم توکنهای خروجی رقیب خود را مصرف کرد.
امنیت و مقیاسپذیری
OpenAI مدل Sol را بیشتر به عنوان یک ابزار دفاعی معرفی میکند تا یک سلاح تهاجمی. بر اساس مستندات شرکت، اگرچه این مدل میتواند «Primitives» بهرهبرداری در مرورگرهای Chromium و Firefox را شناسایی کند، اما هنوز زیر آستانه «بحرانی سایبری» (Cyber Critical) در چارچوب آمادگی (Preparedness Framework) شرکت قرار دارد و هنوز نمیتواند بهطور خودکار حملات زنجیرهای کامل (Full-chain Exploits) ایجاد کند.
دادههای ExploitGym (بنچمارکی که توسط پژوهشگران UC Berkeley و سایر آزمایشگاهها ایجاد شده) نشان میدهد که با افزایش تلاش برای استدلال، عملکرد هر سه مدل سری GPT-5.6 بهبود مییابد. این موضوع نشان میدهد که با افزایش محاسبات (Compute)، پتانسیل رشد و مقیاسپذیری مدلهای آینده همچنان بسیار بالاست.
قیمتگذاری و زیرساخت اقتصادی
از نظر اقتصادی، OpenAI تلاش میکند روند صعودی هزینههای هوش مصنوعی را معکوس کند. قیمت هر میلیون توکن به شرح زیر است:
- Sol: ۵ دلار ورودی / ۳۰ دلار خروجی
- Terra: ۲.۵ دلار ورودی / ۱۵ دلار خروجی
- Luna: ۱ دلار ورودی / ۶ دلار خروجی
بهدلیل اینکه Sol برای رسیدن به نتایج یکسان با رقبای خود، توکنهای کمتری مصرف میکند، هزینه نهایی هر تسک برای برنامهنویسان احتمالاً کاهش مییابد. برای بهینهسازی بیشتر، OpenAI سیستم حافظه موقت (Prompt Caching) را بازسازی کرده است. این سیستم اکنون شامل نقاط شکست صریح (Explicit Cache Breakpoints) و حداقل عمر ۳۰ دقیقهای است. هزینه نوشتن در حافظه ۱.۲۵ برابر قیمت ورودی عادی است، در حالی که خواندن از حافظه دارای تخفیف ۹۰ درصدی است.
این استراتژی مستقیماً تهدید رقابتی مدلهای ارزانتر چینی را هدف قرار میدهد. با ترکیب تعداد توکن کمتر و مدل قیمتگذاری لایهای، OpenAI از مقیاسبندیِ صرفاً مبتنی بر عملکرد، به سمت مقیاسبندیِ مبتنی بر بهرهوری هزینه حرکت میکند.
از جولای ۲۰۲۶، Sol با سختافزارهای Cerebras ادغام میشود تا سرعت استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند و شبیه خودِ آشپزی است نه آموزش آن — را به ۷۵۰ توکن در ثانیه برساند. این حرکت احتمالاً واکنش Anthropic را در مورد بهرهوری استنتاج و روابط دولتیاش برمیانگیزد.
گام بعدی شما
- اگر توسعهدهنده هستید، ساختار قیمتگذاری مدل Luna را برای تسکهای تکراری بررسی کنید تا هزینهها را بهینه کنید.
- در صورت دسترسی به API، حالت ultra را برای اتوماسیونهای چندمرحلهای تست کنید.
- تغییرات سیستم Caching را در معماری اپلیکیشن خود اعمال کنید تا تأخیر در پاسخدهی کم شود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است؛ اثر ادغام با Cerebras بر رقابت سرعت استنتاج را در گزارش بعدی بررسی خواهیم کرد.



گفتگو