
تصور کنید سختافزار بلااستفادهی دوستتان، هزینههای نجومی توکنهای شما را پوشش دهد. اگر هنوز برای هر درخواست به APIهای ابری متکی هستید، احتمالاً در حال پرداخت هزینهای هستید که دیگر لازم نیست.
به نقل از گزارشی که در ۲۷ آوریل ۲۰۲۶ در dev.to منتشر شد، AgentFM یک شبکه محاسباتی همتا-به-همتا (Peer-to-Peer) است که PCهای گیمینگ و سختافزارهای محلی را به یک ابر محاسباتی تبدیل میکند. این سیستم با تقلید از فرمت انتقال دادههای OpenAI SDK، ابزارهای توسعه را فریب میدهد تا تصور کنند در حال ارتباط با یک مرکز داده متمرکز هستند، در حالی که پردازش در واقع روی یک GPU در گوشهای از دنیا انجام میشود.
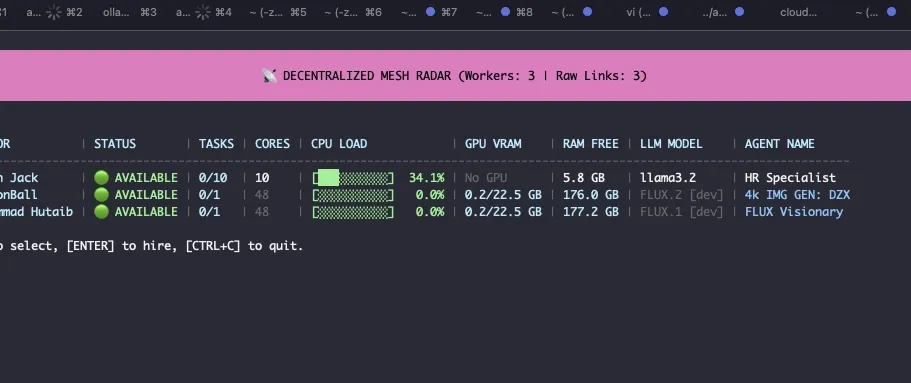
بر اساس مستندات این پروژه، کاربران میتوانند مدلهای محلی مانند Llama 3.2 را درون کانتینرهای Podman مستقر کرده و از طریق یک شبکه مش (Mesh) به آنها دسترسی یابند. این معماری نیاز به حسابهای ابری، کلیدهای API یا نگرانی بابت خروج دادهها (Data Egress) را کاملاً حذف میکند.
ساختار فنی این سیستم بر سه رکن اصلی استوار است:
- کارگران (Workers): گرههایی که قدرت محاسباتی خود را اهدا میکنند و هر ۲ ثانیه وضعیت در دسترس بودن سختافزار و میزان بار را اعلام میکنند.
- رئیسها (Bosses): درگاههای محلی که زبان HTTP شرکت OpenAI را به پروتکلهای libp2p ترجمه میکنند.
- کانتینرها (Containers): محیطهای ایزولهای که عاملهای (Agents) هوش مصنوعی را اجرا کرده و پاسخها را از طریق رویدادهای ارسالی سرور (SSE) استریم میکنند.
همانطور که در تحلیل قبلی ما دربارهی تمرکزگرایی قدرت محاسباتی در دستان OpenAI اشاره کردیم، وابستگی به چند ارائهدهنده بزرگ، ریسکهای امنیتی و مالی زیادی دارد. AgentFM با استفاده از لایهای بسیار سبک — که تنها از حدود ۳۰۰ خط کد Go تشکیل شده — این انحصار را میشکند. توسعهدهندگان تنها با تغییر دو رشتهی متنی base_url و api_key میتوانند کل پشتهی نرمافزاری خود را از ابر به شبکه توزیعشده منتقل کنند.
اما آیا این مدل P2P میتواند پایداری و سرعت لازم برای گردشهای کاری عاملمحور (Agentic) پیچیده را تضمین کند؟ پاسخ این پرسش در بررسی ما دربارهی تأخیر در شبکههای توزیعشده نهفته است.
گام بعدی شما
- اگر سختافزار قدرتمندی دارید، مدل Llama 3.2 را با Podman تست کنید تا با مفهوم استنتاج توزیعشده آشنا شوید.
- کدهای Go این پروژه را بررسی کنید تا ببینید چگونه یک لایهی ترجمه سبک میتواند سازگاری با SDKهای بزرگ را ایجاد کند.
- استراتژیهای کاهش هزینه API خود را با جایگزینی برخی درخواستهای ساده با گرههای محلی بازبینی کنید.



{kind=link}
گفتگو