
آیا یک رزبری پای ۵ واقعاً میتواند در استنتاج مدلهای زبانی از حالت استاندارد PyTorch سریعتر باشد؟ طبق گزارشی که در ۱۲ مه ۲۰۲۶ در وبلاگ PyTorch منتشر شد، پاسخ این سؤال در قابلیت «تفویض بکاند» (Backend Delegation) از طریق ExecuTorch نهفته است.
با انتقال هوش مصنوعی از APIهای ابری به گجتهای پوشیدنی و دوربینهای هوشمند، صنعت با یک گلوگاه حیاتی روبروست: اجرای مدلهای پیچیده روی سختافزارهایی با حافظه و توان محدود. ExecuTorch این مشکل را با گسترش اکوسیستم PyTorch حل میکند و به توسعهدهندگان اجازه میدهد مدلها را به فرمت سبک .pte تبدیل کنند. این کار باعث میشود نیاز به رانتایم پایتون کاملاً حذف شود.
همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازی مدلهای کوچک اشاره کردیم، حذف لایههای اضافی نرمافزاری کلید دستیابی به سرعت در لبه است. این چارچوب برای رسیدن به بهرهوری حداکثری از دو مسیر اصلی استفاده میکند:
- استنتاج (Inference) — تشبیه روزمره: لحظهای که مدل واقعاً جواب تولید میکند، مثل خودِ آشپزی و نه دورهی آموزش آشپز — روی CPU: در پلتفرمهای Arm، این سیستم از بکاند XNNPACK و میکروکرنلهای KleidiAI برای بهرهگیری از ویژگیهای معماری Neon استفاده میکند.
- شتابدهی NPU: برای واحدهای پردازش عصبی Ethos-U، مدلها به فرمت INT8 کوانتیزه شده و پیش از پردازش توسط کامپایلر Vela، به معماری TOSA (Tensor Operator Set Architecture) تبدیل میشوند.
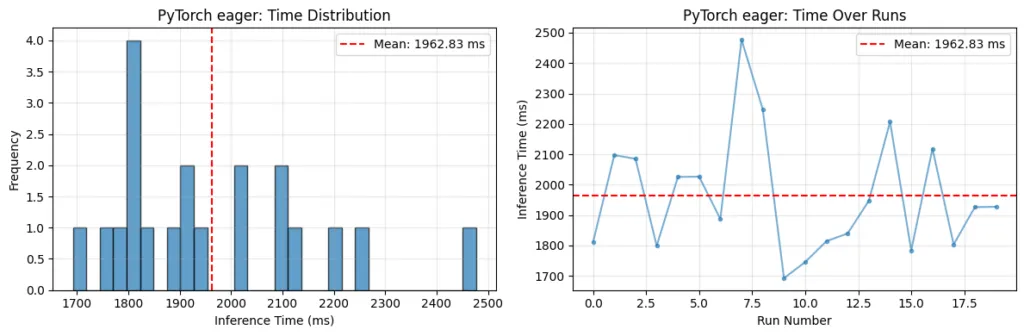
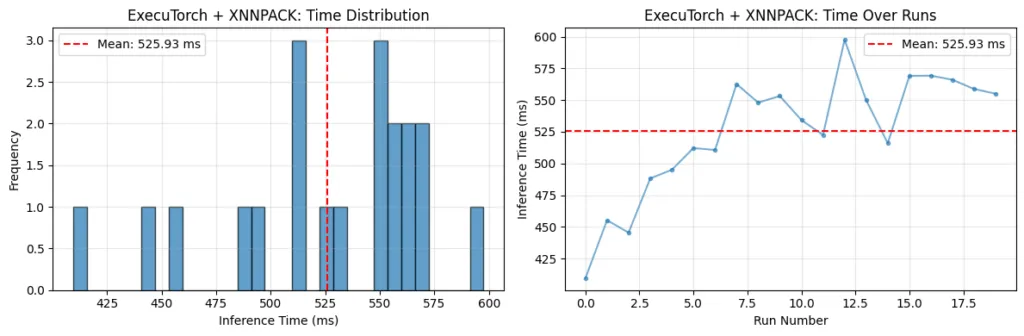
در آزمایشهای انجام شده با مدل ترنسفورمر OPT-125M روی یک رزبری پای ۵، ترکیب ExecuTorch و XNNPACK کاهش چشمگیر تأخیری (Latency) را نسبت به حالت Eager نشان داد. با این حال، به نقل از این گزارش، در صورت نبود سیستم خنککننده فعال، گرم شدن CPU باعث کاهش سرعت در بلندمدت میشود. برای سختافزارهای پیشرفتهتر مانند Ethos-U85، سیستم از «اجرای ناهمگون» برای تقسیم گراف محاسباتی بین NPU و CPU استفاده میکند.
برای بهینهسازی این استقرارها، Arm ابزار Model Explorer گوگل را با آداپتورهای سفارشی ادغام کرده است. این قابلیت به مهندسان اجازه میدهد بصری ببینند که آیا یک مدل به صورت یک زیرگراف واحد روی NPU اجرا میشود یا به دلیل وجود عملگرهای پشتیبانینشده، تکهتکه شده و بخشی از آن به CPU بازمیگردد.
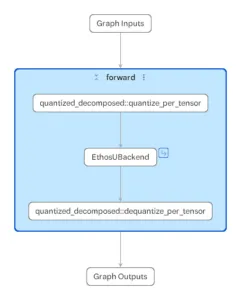
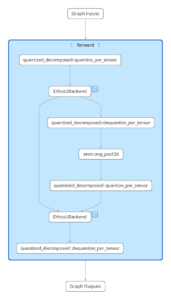
این سطح از شفافیت، هوش مصنوعی در لبه را از یک فرآیند «آزمون و خطا» به یک تکلیف مهندسی دقیق تبدیل میکند. با شناسایی دقیق لایههایی که باعث بازگشت به CPU میشوند، توسعهدهندگان میتوانند معماری مدل را بازنویسی کنند تا بهرهوری NPU به حداکثر برسد؛ موضوعی که مستقیماً بر عمر باتری و پاسخدهی آنی دستگاه اثر میگذارد.
گام بعدی شما
- بررسی مجموعهی Jupyter labs منتشر شده توسط Arm برای پیادهسازی این جریانها روی سختافزار خود.
- تحلیل لایههای مدلهای خود برای شناسایی عملگرهای ناسازگار با TOSA.
- تست اثر خنککننده فعال بر پایداری نرخ استنتاج در دستگاههای لبه.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو