تصور کنید هر تکه کد جدیدی که به پروژه اضافه میکنید، دریچهای باز برای نفوذ مهاجمان باشد. اگر امروز از کتابخانههای متنباز استفاده میکنید، احتمالاً نمیدانید که سرعت تبدیل یک آسیبپذیری به یک حملهٔ واقعی، حالا از هفتهها به تنها چند ساعت رسیده است.
طبق گزارشهای صنعتی، امروزه بیش از ۸۰٪ از کدهای موجود در برنامههای سازمانی معمولی از اجزای متنباز تشکیل شده است. این حجم عظیم از کد، سطح حمله (Attack Surface) گستردهای برای ایجاد آسیبپذیریها فراهم میکند. با شتاب گرفتن توسعهٔ نرمافزارهای کمکگرفته از هوش مصنوعی (AI-assisted development)، پذیرش وابستگیهای جدید بدون بررسیهای امنیتی متناسب افزایش یافته و این نسبت همچنان در حال رشد است. دادههای صنعتی مقیاس این مخاطره را تأیید میکنند: بدافزارهای متنباز تنها در یک سال ۷۵٪ رشد کردند و به ۱.۲۳۳ میلیون بستهٔ مخرب شناختهشده رسیدند؛ در حالی که مجموع دانلودها از مخازن اصلی از ۹.۸ تریلیون بار عبور کرده است. این روند نگرانکننده حتی پروژههای معتبر را نیز هدف قرار داده است، چنانکه اخیراً ۷۰ پروژه گیتهاب مایکروسافت برای متوقف کردن بدافزارهای سرقت رمز عبور تعطیل شدند. در چنین مقیاسی، حتی یک نرخ خطای اندک در بررسی وابستگیها، به معنای قرار گرفتن کل محیطهای عملیاتی در معرض یک ریسک سیستمی است.
به نقل از مستندات فنی، از ۲۵ ژوئن ۲۰۲۶، پنجرهٔ زمانی برای اصلاح این نقصها بهشدت بسته شده و از چندین هفته به تنها چند ساعت رسیده است. دلیل این اتفاق، ظهور توسعهٔ اکسپلویتها با کمک مدلهای زبانی بزرگ (LLM)، خودکارسازی تحلیل تفاوت وصلهها (Patch-diffing) و ابزارهای عاملمحور (Agentic tooling) است. این تهدید را میتوان در گزارش انتروپیک درباره تبدیل وصلههای امنیتی ویندوز به اکسپلویت در ۶ ساعت به وضوح مشاهده کرد. تیمهای امنیتی سنتی در این رقابت شکست خوردهاند، چون به گزارشهای ایستا و هفتگی تکیه میکنند که در لحظهٔ باز شدن، منقضی شدهاند. اگر یک چرخهٔ استقرار (Deployment cycle) ۴۸ ساعت زمان ببرد، زیرساخت پاسخ شما پیش از آنکه حتی تیکتی باز شود، از قافله عقب مانده است.
همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، این تأخیر عملیاتی یک ریسک سیستمی ایجاد میکند؛ جایی که یک اکسپلویت تأییدشده میتواند مدتها پیش از آنکه یک توسعهدهندهٔ انسانی تیکتی را باز کند، توسط مهاجمان مستقر شود. این رقابت تسلحهاتی در حوزه هوش مصنوعی منجر به ظهور ابزارهای پیشرفتهتری شده است، بهطوریکه مدل GPT-5.5-Cyber در برخی محکهای امنیتی از رقیب خود انتروپیک پیشی گرفته است. هزینهٔ واقعی این اتفاق در معیار «میانگین زمان اصلاح» (MTTR) ظاهر میشود؛ متریکی که تیمهای مدیریتکنندهٔ ریسک وابستگی را از تیمهای انباشتکنندهٔ ریسک جدا میکند.
برای حل این مشکل، شرکت Xccelera پلتفرم LibX را توسعه داد. LibX یک سامانهٔ مدیریت وابستگی عاملمحور (Agentic) است — شبیه به دستیاری که بهجای گزارش دادن مشکلات، خودش آستینها را بالا میزند و آنها را تعمیر میکند. برخلاف اسکنرهای معمولی، LibX تنها گزارش نمیدهد، بلکه یک چرخهٔ بسته را اجرا میکند که از خواندن فایل lockfile شروع شده و بدون نیاز به ارجاعات دستی، با یک درخواست ادغام (Pull Request) پذیرفتهشده به پایان میرسد.
لایه هوشمند: OSV و GHSA
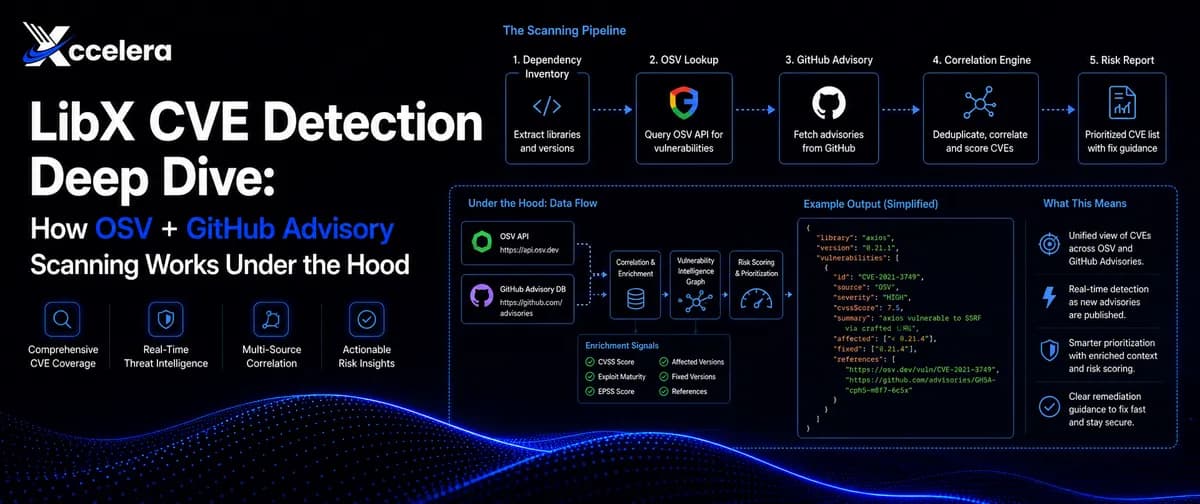
LibX برای دقت و سرعت، از یک خط لولهٔ دادهٔ پیچیده استفاده میکند. بر اساس بررسیهای فنی در dev.to، این پلتفرم از طرحوارهٔ Open Source Vulnerabilities (OSV) برای نرمالسازی دادهها از بیش از ۳۰ منبع اکوسیستم استفاده میکند. این منابع عبارتند از:
- PyPI
- RustSec
- پایگاه داده آسیبپذیری Go
- اطلاعرسانیهای امنیتی گیتهاب (GitHub Security Advisories)
این نرمالسازی حیاتی است زیرا محدودههای آسیبپذیری را مستقیماً به ورودیهای lockfile پروژه متصل میکند. طرحوارهٔ OSV بهجای تکیه به نام بسته به تنهایی، محدودههای نسخههای آسیبدیده را بهصورت ساختاریافته ذخیره میکند. این بدان معناست که اسکنر برای هر زبان برنامهنویسی به منطق سفارشی و وابسته به اکوسیستم نیاز ندارد تا تشخیص دهد آیا یک نسخه آسیبپذیر است یا خیر؛ بلکه خودِ طرحواره (Schema) این نگاشت را بهطور صریح مدیریت میکند.
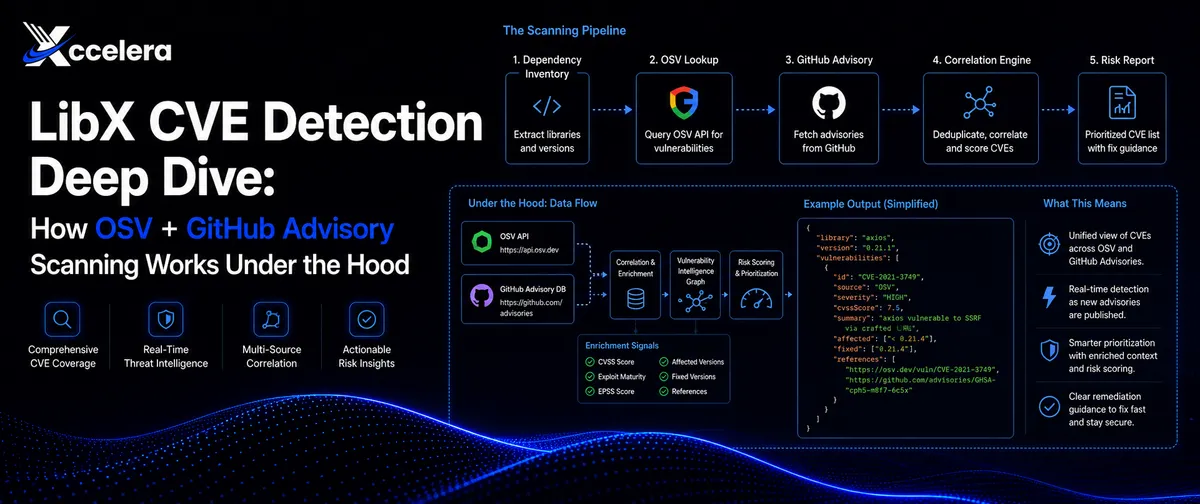
همچنین OSV سریعتر از ابزارهای متکی به پایگاه داده ملی آسیبپذیری (NVD) به پوشش توصیهها دست مییابد. خطوط لولهٔ خودکار، مخازن عمومی را برای یافتن کامیتهای مربوط به اصلاحات امنیتی، ارجاعات به شناسههای شناختهشده و انتشار توصیهها اسکن میکنند. این قابلیت اجازه میدهد تا تشخیصها پیش از صدور رسمی یک شناسه CVE رخ دهد و آسیبپذیریها در زمان واقعی شناسایی شوند.
علاوه بر این، LibX از پایگاه داده GitHub Advisory Database (GHSA) بهره میبرد که متراکمترین پوشش اکوسیستممحور را برای npm، PyPI، Maven، Go، Cargo و هشت اکوسیستم دیگر فراهم میکند. این کاتالوگ شامل بیش از ۲۵,۰۰۰ توصیهٔ بررسیشده توسط جامعهٔ توسعهدهندگان است که هر کدام با معیارهای زیر نرمال شدهاند:
- امتیاز شدت: شامل هر دو ردهبندی پایه CVSS v4 و v3
- دادههای نسخه: محدودههای آسیبدیده و اولین نسخهٔ اصلاحشده (Patched version)
- طبقهبندی: دستهبندیهای نقاط ضعف CWE
- منابع: زنجیرهٔ کامل مراجع و مستندات
برای جلوگیری از «خستگی هشدار» (Alert Fatigue)، LibX از شناسه CVE بهعنوان کلید حذف موارد تکراری (Deduplication) استفاده میکند. این کار تضمین میکند که یک آسیبپذیری که هم در GHSA و هم در NVD ظاهر شده است، باعث تولید هشدارهای متعدد و بیهوده نشود که حجم دادهها را بدون افزودن سیگنال مفید افزایش دهد. از آنجا که دادههای GHSA بهعنوان یک منبع درجهیک در لایه نرمالسازی OSV.dev ادغام شدهاند، LibX بدون نیاز به ادغامهای مجزای API، به امتیازهای شدت و اطلاعات دسترسی به وصلهها دسترسی دارد.
چرخهٔ اصلاح عاملمحور
LibX برای حذف MTTR و کاهش فاصله بین شناسایی و ارتقاء، از یک چرخهٔ خودکار سه-مرحلهای استفاده میکند:
- گام اول: پیمایش کامل وابستگیهای ترانزیتی: عامل تمام گراف وابستگیها را بررسی میکند. در حالی که وابستگیهای مستقیم لایه قابل مشاهده هستند، وابستگیهای ترانزیتی — یعنی بستههایی که توسط وابستگیهای مستقیم فراخوانده میشوند — بخش بزرگی از سطح واقعی مواجهه (Exposure surface) را تشکیل میدهند. LibX بهجای بررسی سطحی لیست بستهها، تمام گرهها را با سوابق OSV و GHSA تطبیق میدهد.
- گام دوم: اولویتبندی با EPSS و بررسی قابلیت دسترسی: این سیستم از سیستم امتیازدهی پیشبینی اکسپلویت (EPSS) استفاده میکند تا احتمال اینکه یک آسیبپذیری در دنیای واقعی طی ۳۰ روز آینده مورد اکسپلویت قرار گیرد را تخمین بزند. با ترکیب امتیاز EPSS و تحلیل قابلیت دسترسی (Reachability) — که تعیین میکند آیا آن تابع آسیبپذیر واقعاً در کدبیس فراخوانی شده یا خیر — LibX حدود ۹۸٪ نویزها را حذف کرده و روی ۲٪ ریسکهای واقعی و قابل بهرهبرداری تمرکز میکند.
- گام سوم: وصله، تست و PR خودکار: عامل پیشنویس ارتقای وابستگی را تهیه کرده و تمام مجموعه تستهای واحد (Unit test) و یکپارچگی (Integration test) را روی حالت وصلهشده اجرا میکند. سپس تأیید میکند که هیچ تغییر مخربی (Breaking changes) ایجاد نشده و در نهایت یک Pull Request حاوی زمینهٔ شدت (Severity context)، جزئیات اصلاحیه و تأییدیهٔ آمادگی برای استقرار ارسال میکند.
استقرار سازمانی
برای سازمانهایی که محدودیتهای شدید اقامت دادهها دارند یا در محیطهای Air-gapped (جداشده از شبکه) فعالیت میکنند، LibX مدل میزبانی شخصی (Self-hosting) را پشتیبانی میکند. این ویژگی به سازمانها اجازه میدهد سرعت چرخهٔ عاملمحور را داشته باشند بدون اینکه امنیت کدهای داخلی خود را به خطر بیندازند.
LibX خود را از ابزارهای متداول از طریق چرخهٔ تکرارشوندهٔ وصلهها متمایز میکند. تداخلات وابستگی، برخورد محدودیتهای نسخهای و خطاهای مربوط به رزولوشنهای اکوسیستمی توسط یک سیستم تلاش مجدد (Retry) خودکار مدیریت میشوند که پیش از ارجاع یافتهها به یک بازبین انسانی، استراتژیهای ارتقای متعددی را امتحان میکند. این رویکرد، چرخهٔ اصلاح آسیبپذیریهای بحرانی را از چندین ماه به چند روز کاهش میدهد.
این تغییر، یک چرخش بنیادین در معماری امنیت است: عبور از مدل «اسکن-گزارش-تیکت» به مدل «تشخیص-تأیید-وصله». در این مدل، نقش انسان از یک کارگر یدی به یک بازرس نهایی تغییر میکند. LibX منتظر نمیماند تا گزارش خوانده شود؛ بلکه خودش شکاف را میبندد.
برای رهبران مهندسی، این یعنی مسئولیت حقوقی و امنیتی مربوط به کدهای متنباز در سطح هیئتمدیره، بالاخره توسط نرمافزاری مدیریت میشود که به سرعتِ مهاجمان حرکت میکند. برای ارزیابی این رویکرد، تیمها باید با حساب کردن میانگین زمان اصلاح (MTTR) فعلی خود برای CVEهای بحرانی و مقایسه آن با سرعت یک حلقهٔ عاملمحور خودکار شروع کنند. تیمهای مهندسی که آماده انتقال به تشخیص مداوم و عاملمحور CVEها هستند، میتوانند LibX را در Xccelera بررسی کنند.
گام بعدی شما
- میانگین زمان اصلاح (MTTR) فعلی خود را برای CVEهای بحرانی محاسبه کنید تا شکاف عملکردی خود با سیستمهای خودکار ببینید.
- اگر از وابستگیهای پیچیده در Rust یا Go استفاده میکنید، اولویت را بر بررسی وابستگیهای ترانزیتی بگذارید، چون بیشترین ریسک در لایههای پنهان است.
- مدلهای میزبانی شخصی را برای محیطهای حساس ارزیابی کنید تا تعادل بین سرعت اصلاح و حریم خصوصی کد برقرار شود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو