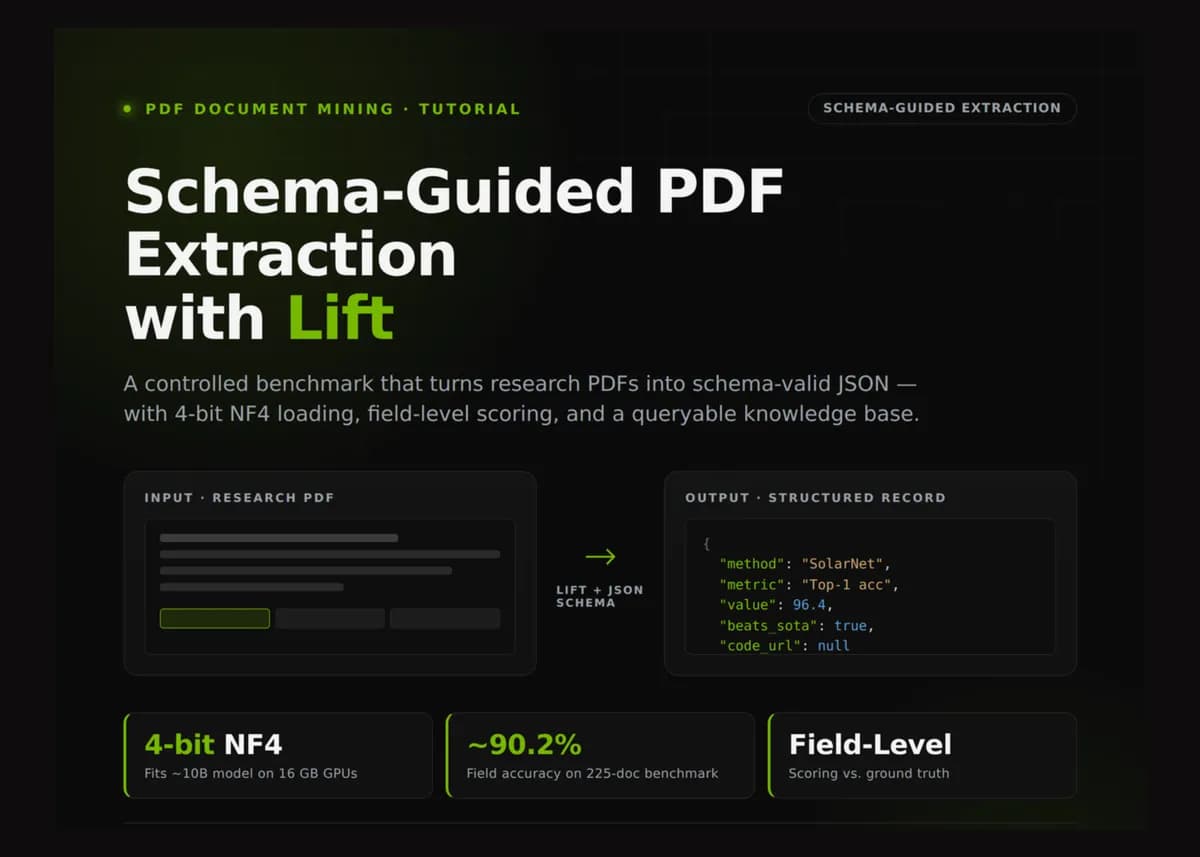
تصور کنید تمام مقالات تخصصی یک حوزه را دارید، اما برای استخراج نتایج عددی باید تکتک آنها را بخوانید یا به ابزارهای نامطمئن تکیه کنید. جریان کاری معمول برای استخراج دادههای فنی از مقالات پژوهشی معمولاً نیازمند تلاشهای دستی خستهکننده یا اتکا به تجزیهکنندههای متنی (Text Parsers) غیرقابل اعتماد است. مدل Lift این فرآیند را تغییر میدهد و استخراج داده از PDF را بهجای یک خلاصهسازی کلی، به یک عملیات بازیابی کنترلشده و هدایتشده توسط طرحواره (Schema-guided retrieval) تبدیل میکند تا اسناد پراکنده فوراً به پایگاهدادههای ساختاریافته تبدیل شوند.
بسیاری از خطلولههای فعلی تبدیل PDF به متن، چیدمان بصری را حذف میکنند و باعث میشوند اطلاعات حیاتی که در جداول یا گزارشهای چندصفحهای پنهان شدهاند گم شوند. طبق گزارش یک آموزش در Marktechpost که در سال ۲۰۲۴ منتشر شد، این شکاف اغلب منجر به توهم (Hallucination) میشود؛ وضعیتی که در آن هوش مصنوعی نتیجه یک مدل پایه (Baseline) را با عملکرد مدل پیشنهادی اشتباه میگیرد. Lift این مشکل را با تحلیل دقیق چیدمان سند و پایبندی سختگیرانه به یک طرحواره JSON حل میکند. این رویکرد در حالی اهمیت مییابد که پژوهشهای اخیر نشان دادهاند اجبار مدلهای متوسط به تولید خروجیهای JSON میتواند منجر به کاهش چشمگیر دقت استدلالی آنها شود.
همانطور که در تحلیلهای پیشین ما دربارهی امنیت و دقت مدلهای استخراج داده اشاره کردیم، مدیریت حافظه در مقیاس محلی همواره یک چالش بوده است.
بهینهسازی برای سختافزار
برای دسترسپذیر کردن این جریان کاری، پیادهسازی فعلی از کوانتش (Quantization) — که مانند فشردهسازی یک عکس برای اشغال فضای کمتر است — ۴-بیتی NF4 از طریق کتابخانههای bitsandbytes و accelerate استفاده میکند. این تکنیک اجازه میدهد یک مدل با حدود ۱۰ میلیارد پارامتر بهراحتی روی پردازندههای گرافیکی (GPU) محدود ۱۶ گیگابایتی، مانند NVIDIA T4 یا L4 که در گوگل کولب موجود هستند، اجرا شود. این موضوع حیاتی است، زیرا وزنهای مدل بدون این فشردهسازی، برای فرآیند دانلود و بارگذاری اولیه به حدود ۲۰ گیگابایت حافظه نیاز دارند. در این زمینه، تکنیکهای مشابهی مانند فشردهسازی وصلهای برای رفع گلوگاههای حافظه نیز در سایر مدلهای زبانی و صوتی به کار گرفته شدهاند.
این سیستم بهطور خاص فرآیند بارگذاری مدل در کتابخانه Transformers را اصلاح (Patch) میکند. با تزریق یک BitsAndBytesConfig — که مقادیر load_in_4bit=True ، bnb_4bit_quant_type="nf4" و bnb_4bit_use_double_quant=True را مشخص میکند — به کلاسهایی مانند AutoModelForImageTextToText ، AutoModelForMultimodalLM ، AutoModelForVision2Seq ، AutoModelForCausalLM و AutoModel ، سیستم تضمین میکند که موتور پشتیبانی بدون کرش کردن بهدلیل لبریز شدن حافظه ویدیویی (VRAM) بهطور پایدار اجرا شود.
برای حفظ پایداری، این خطلوله شامل یک منطق تثبیت نسخه برای کتابخانه Pillow (بهطور مشخص نسخه ۱۱.۳.۰) است. این کار از یک مشکل سازگاری شناختهشده در کولب جلوگیری میکند که در آن نسخههای جدیدتر Pillow میتوانند واردات پاییندستی از طریق torchvision و transformers را مختل کنند. اسکریپت همچنین قابلیت محاسباتی GPU را شناسایی میکند؛ اگر نسخه ۸.۰ یا بالاتر باشد، از torch.bfloat16 استفاده میکند و در غیر این صورت برای نوع محاسباتی (compute dtype) به صورت پیشفرض از torch.float16 استفاده مینماید.
مکانیزمهای پسزمینه مدل
مدیریت پسزمینه توسط یک InferenceManager با استفاده از متدهای Hugging Face انجام میشود. سیستم در هنگام مقداردهی اولیه، نام دقیق GPU و مجموع حافظه را شناسایی میکند تا تصمیم بگیرد آیا بارگذاری ۴-بیتی اجباری باشد یا خیر. مکانیزم اصلاحی (Patching) بهگونهای طراحی شده است که هرگونه فراخوانی بعدی model.to() یا .cuda() را خنثی کند، زیرا این دستورات روی مدلهای کوانتیده با bitsandbytes غیرمجاز هستند و در غیر این صورت منجر به خطاهای زمان اجرا (Runtime Errors) میشوند.
تنظیمات دقیق زمان اجرا شامل مواردی چون N_DOCS = 3 ، FORCE_FULL_PRECISION = False و FORCE_4BIT = False است. پرچم SOW_FIRST_PAGE = True امکان بررسی بصری ورودی سند را فراهم میکند. برای آزمایشهای واقعی، سیستم مقدار REAL_PDF_URL = "https://arxiv.org/pdf/1512.03385" را تعریف کرده و بر روی REAL_PDF_PAGES = "0-3" تمرکز میکند تا سرعت استخراج بهینه شود.
سازوکار هدایتشده با طرحواره
مدل Lift صرفاً یک PDF را «نمیخواند»، بلکه از یک نقشه فنی به نام JSON Schema پیروی میکند. این طرحواره دقیقاً تعیین میکند چه فیلدهایی استخراج شوند — مانند وابستگیهای نویسندگان، ابرپارامترهای خاص و معیارهای بنچمارک — و توصیفاتی را برای رفع ابهام دادهها ارائه میدهد. این رویکرد، فرآیند را از یک خلاصهسازی باز به یک تسک بازیابی اطلاعات کنترلشده تبدیل میکند.
به عنوان مثال، طرحواره به مدل دستور میدهد که بین یک معیار اعتبارسنجی (Validation) و یک معیار آزمون (Test) تفاوت قائل شود. شیء headline_metric در این طرحواره صراحتاً مقدار مربوط به مجموعه آزمون (TEST set) برای بنچمارک اصلی را میخواهد و تأکید میکند که این مقدار نباید عدد اعتبارسنجی یا عدد مربوط به یک مدل پایه باشد.
سایر فیلدهای دقیق در این طرحواره عبارتاند از:
- نویسندگان (Authors): آرایهای از اشیا شامل نام نویسنده و مؤسسه مربوطه.
- ابرپارامترها (Hyperparameters): یک شیء تودرتو که بهینهساز، نرخ یادگیری (عدد)، اندازه دسته (عدد صحیح) و تعداد Epochها (عدد صحیح) را ثبت میکند.
- شکستن SOTA: یک مقدار بولی (Boolean) که تنها زمانی True است که مقاله صراحتاً ادعای شکستن رکورد قبلی (State of the Art) را داشته باشد.
- آدرس کد (Code URL): رشتهای برای لینک مخزن؛ در صورتی که مقاله کدی را منتشر نکرده باشد، باید مقدار
nullبرگردانده شود. - وظیفه اصلی (Primary Task): رشتهای که شرح میدهد مقاله به کدام تسک اصلی یادگیری ماشین میپردازد.
- مجموعه دادهها (Datasets): آرایهای از تمام مجموعههای داده بنچمارک که مقاله روی آنها ارزیابی شده است.
- محدودیتها (Limitations): آرایهای از رشتهها شامل محدودیتهایی که نویسندگان صراحتاً پذیرفتهاند.
ایجاد محیط تست با دقت بالا
برای ارزیابی صحت، از یک مجموعه داده مصنوعی از گزارشهای چندصفحهای تولید شده توسط ReportLab استفاده شده است. این گزارشها با «عوامل گمراهکننده» (Distractors) طراحی شدهاند تا چالشهای دنیای واقعی مقالات آکادمیک را شبیهسازی کنند. هر PDF به صورت یک سند ۳ صفحهای رندر شده است، بهطوری که چکیده در صفحه ۱ از جدول نتایج در صفحه ۳ فاصله فیزیکی دارد تا توانایی مدل در حفظ بستر متن (Context) در سراسر شکستگیهای صفحات تست شود.
این مجموعه شامل سه نمونه متنوع برای آزمایش سناریوهای مختلف استخراج است:
- SolarNet: مقالهای درباره طبقهبندی پوشش زمین در تصاویر ماهوارهای با استفاده از بنچمارکهای EuroSAT، BigEarthNet و So2Sat. این مدل به دقت ۹۶.۴٪ در تست EuroSAT رسیده (بالاتر از SOTA قبلی یعنی ۹۵.۱٪) و دارای ۴۲.۷ میلیون پارامتر است. از بهینهساز AdamW با نرخ یادگیری ۰.۰۰۰۳، اندازه دسته ۱۲۸ و ۹۰ اپوک استفاده میکند. این نمونه صراحتاً بیان میکند که نویسندگان کد منبع را منتشر نکردهاند تا توانایی مدل در مدیریت مقادیر
nullیا خودداری از پاسخ تست شود. محدودیتها شامل کاهش دقت در پوششهای ابری شدید و محدودیت رزولوشن مکانی ۱۰ متر است. - GraphMoE: مقالهای در پیشبینی خواص مولکولی با استفاده از OGB-MolHIV، QM9 و ZINC. مقادیر ROC-AUC برابر با ۰.۸۱۲ (تست) و ۰.۸۲۸ (اعتبارسنجی) روی OGB-MolHIV را گزارش کرده و دارای ۸.۳ میلیون پارامتر است. از بهینهساز Adam با نرخ یادگیری ۰.۰۰۱، اندازه دسته ۲۵۶ و ۱۲۰ اپوک استفاده میکند. شامل یک لینک گیتهاب فعال (
https://github.com/mol-ai/graphmoe) است تا توانایی مدل در انتخاب صحیح معیار تست و یافتن URL سنجیده شود. محدودیتها شامل افزایش ۱۵ درصدی تأخیر در استنتاج و محدودیتهای ارزیابی روی مولکولهای زیر ۵۰ اتم سنگین است. - AcoustiFormer: مقالهای در طبقهبندی صداهای محیطی با استفاده از ESC-50 و UrbanSound8K. این مدل به دقت تست ۸۸.۷٪ و دقت اعتبارسنجی ۹۰.۳٪ با ۲۲.۱ میلیون پارامتر دست یافته است. از AdamW با نرخ یادگیری ۰.۰۰۰۵، اندازه دسته ۶۴ و ۲۰۰ اپوک استفاده میکند. نکته حیاتی این است که این مدل SOTA قبلی (۸۹.۲٪) را نمیشکند، که برای تست توانایی مدل در تخصیص صحیح مقدار
falseبه فیلدbeats_prior_sotaاست. محدودیتها شامل شکاف عملکردی در مقایسه با مدلهای پایه CNN بزرگتر و نبود ارزیابی روی استریمهای صوتی زنده است.
ساختار و چیدمان PDF
اسناد مصنوعی با المانهای بصری خاصی ساخته شدهاند تا مدل به چالش کشیده شود:
- سیگنالهای بصری: جداول با رنگهای خاص (مثلاً
#2b3a67برای آموزش و#7a2e2eبرای نتایج) طراحی شدهاند تا چیدمانهای حرفهای را شبیهسازی کنند. خطوط شبکه (Grid lines) برای خوانایی بهتر روی خاکستری ۰.۴ تنظیم شدهاند. - توزیع محتوا: بخش «جزئیات متد و آموزش» در صفحه ۲ قرار دارد و شامل جدولی با بهینهساز، نرخ یادگیری، اندازه دسته و اپوکها است. این کار مدل را مجبور میکند برای یافتن ابرپارامترها از صفحه اول فراتر رود.
- ابهام در معیارها: جداول نتایج، معیارهای اعتبارسنجی و آزمون را دقیقاً در کنار هم قرار میدهند تا اطمینان حاصل شود مدل صرفاً بالاترین عدد را برنمیدارد، بلکه دقیقاً عدد مربوط به «تست» را انتخاب میکند. این یک «تست گمراهکننده نزدیک» (Near-miss-distractor test) است.
- فرآیند رندرینگ: منطق ساخت از
SimpleDocTemplateبا اندازه صفحه استاندارد LETTER و حاشیههای خاص (۰.۸ اینچ بالا/پایین و ۰.۹ اینچ چپ/راست) استفاده میکند تا یک ساختار PDF واقعگرایانه تضمین شود.
بنچمارک و امتیازدهی
سیستم از یک مکانیزم امتیازدهی در سطح فیلد استفاده میکند که خروجیهای JSON تودرتو را برای مقایسه مستقیم با برچسبهای مرجع (Ground Truth) تخت (Flatten) میکند. این سیستم از منطق آگاه از نوع (Type-aware) برای تضمین عدالت در امتیازدهی استفاده میکند:
- تلورانس عددی: مقادیر با تلورانس 1e-6 ارزیابی میشوند. اگر مقدار بزرگتر باشد، تفاوت در صورتی پذیرفته است که خطای نسبی کمتر از 5e-3 باشد.
- نرمالسازی رشتهها: علائم punctuation ابتدایی و انتهایی حذف شده، حروف کوچک میشوند و فاصلههای اضافی با استفاده از regex (
\s+) پاک میشوند تا تفاوتهای جزئی در فرمت باعث شکست مدل نشود. - منطق بولی: مقادیر Boolean مستقیماً مقایسه میشوند و مقادیر null با کلیدهای گمشده مطابقت داده میشوند تا پاداشهای درستی برای خودداریهای صحیح (Correct Abstentions) داده شود.
- الگوریتم تختی (Flattening): تابع
flattenبه صورت بازگشتی دیکشنریها و لیستهای تودرتو را به یک نقشه با نماد نقطه (مثلاًheadline_metric.value) تبدیل میکند تا بررسیهای دقت بهصورت جزئی (Granular) صورت گیرد.
در تستهای ارائه شده، مدل موظف بود دادههای مدلهای ذکر شده را استخراج کند. گزارشهای Datalab نشان میدهد که این سیستم به صحت فیلد (Field Accuracy) حدود ۹۰.۲٪ در یک بنچمارک متشکل از ۲۲۵ سند دست یافته است. استفاده از InferenceManager مانع از بارگذاری مجدد وزنها برای هر فایل شده و پردازش دستهای (Batch Processing) را کاربردی میکند.
ساخت پایگاه دانش پژوهشی
سوابق JSON استخراج شده در نهایت به یک DataFrame در Pandas تبدیل میشوند. این کار یک پوشه از PDFها را به یک پایگاه دانش پژوهشی تبدیل میکند که کاربران میتوانند روی آن کوئریهای پیچیده اجرا کنند. برای مثال، آموزش یک کوئری را نشان میدهد که تمام مقالاتی را که ادعای شکستن SOTA دارند مییابد و آنها را بر اساس بالاترین امتیاز مرتب میکند.
این پایگاه دانش نهایی یک ردیف برای هر مقاله را با ستونهای زیر ثبت میکند:
- نام روش پیشنهادی
- وظیفه اصلی (Primary Task)
- نام بنچمارک و معیار
- امتیاز نهایی
- تعداد پارامترها (به میلیون)
- وضعیت SOTA و در دسترس بودن کد
- تعداد نویسندگان
- امتیاز صحت فیلد
کاربرد واقعی و مقیاسدهی
برای کسانی که قصد دارند فراتر از دادههای مصنوعی بروند، این خطلوله میتواند روی مقالات واقعی arXiv، مانند مقاله موجود در https://arxiv.org/pdf/1512.03385 اعمال شود. پیشنهاد میشود برای مدیریت تنوع زیاد و وحشیانه چیدمانها در انتشارات آکادمیک، یک محدوده صفحه (page_range) مانند "0-3" مشخص کنید تا Lift به سمت مرتبطترین بخشها هدایت شود.
تغییر رویکرد از استخراج کلی به استخراج هدایتشده با طرحواره، استاندارد هوش مستندات را تغییر میدهد. هدف دیگر «درک کلی مقاله» نیست، بلکه ایجاد یک رکورد ماشینخوان، قابل راستیآزمایی و دقیق از ادعاهای علمی است. این جریان کاری ثابت میکند که با ترکیب یک مدل بصری و یک طرحواره سختگیرانه، میتوان دقت بالایی را حتی زمانی که دادههای حیاتی در جداول چندصفحهای دفن شدهاند، حفظ کرد.
شما اکنون میتوانید با جایگزینی طرحواره مصنوعی با نیازهای خاص حوزه خود (مانند پروندههای رگولاتوری یا دفترچههای فنی)، این سیستم را پیادهسازی کنید. برای دسترسی به کد کامل پیادهسازی و مخزن Lift به لینکها مراجعه کنید. همچنین میتوانید ما را در توییتر دنبال کرده و به جمع بیش از ۱۵۰ هزار عضو سابردیت ML ما بپیوندید و خبرنامه ما را مشترک شوید. اگر در تلگرام هستید، همین حالا میتوانید به کانال ما ملحق شوید. برای همکاری در جهت ارتقای مخزن گیتهاب، صفحه Hugging Face، عرضه محصول یا وبینار، با Sana Hassan در ارتباط باشید.
اما تأثیر این روش بر سرعت تحلیل ادبیات پژوهشی در مقیاس هزاران مقاله حتی پیچیدهتر است — به تحلیل ما دربارهی سیستمهای RAG پیشرفته مراجعه کنید.



گفتگو