تصور کنید تحلیلگری مالی برای تطبیق ارقام، صورتحساب بانکی را در پنجره چت کپی میکند تا مجموع را بررسی کند. یا کارشناس پشتیبانی برای پیشنویس یک پاسخ، ایمیل کامل مشتری را کپی میکند. یا مدیری پیش از یک جلسه، بخشی از صورتحساب بانکی را برای مدل میچسباند. در هر یک از این سناریوها، پرامپت حاوی نامها، شمارههای IBAN و شناسههایی است که هوش مصنوعی برای انجام تکالیفش اصلاً به آنها نیاز ندارد.
این عادت در می ۲۰۲۳ منجر به یک آسیبپذیری بحرانی شد؛ طبق گزارش بلومبرگ، کارکنان سامسونگ (Samsung) کدهای منبع داخلی (source code) را در ChatGPT آپلود کردند که در نهایت منجر به ممنوعیت سراسری این ابزار در کل شرکت شد. اکنون این ریسک مقیاسیافته است. طبق گزارش سال ۲۰۲۶ از نتاسکوپ (Netskope)، سازمانها بهطور میانگین ماهانه ۲۲۳ تلاش از سوی کارکنان برای گنجاندن دادههای حساس در پرامپتها یا آپلودهای هوش مصنوعی مولد شناسایی میکنند. این دادهها طیف گستردهای از دادههای تنظیمشده (regulated data)، مالکیت معنوی، کدهای منبع و اعتبارنامهها (credentials) را شامل میشوند. همان گزارش نشان داد که تخلفات مربوط به سیاستهای داده در هوش مصنوعی مولد (genAI)، سال به سال بیش از دو برابر شده است.
بسیاری از کارکنان از هر حسابی که در مرورگر فعال است استفاده میکنند. در طرحهای مصرفکننده ChatGPT، Claude و Gemini، تنظیمات پیشفرض اغلب اجازه میدهد ارائهدهندگان از گفتگوها برای آموزش مدل استفاده کنند. جزئیات این موضوع بسته به ارائهدهنده متفاوت است:
- OpenAI (ChatGPT): طبق بخش پرسش و پاسخ کنترلهای داده (Data Controls FAQ)، گفتگوهای طرحهای رایگان (Free)، پلاس (Plus) و پرو (Pro) ممکن است برای آموزش مدلها استفاده شوند، مگر اینکه کاربر بهطور دستی این تنظیم را خاموش کند. دادههای مربوط به طرحهای تجاری (Business)، سازمانی (Enterprise) و آموزشی (Education) بهطور پیشفرض از آموزش مستثنی هستند.
- Anthropic (Claude): از ۲۸ سپتامبر ۲۰۲۵، حسابهای رایگان، پرو و مکس بهطور پیشفرض اجازه میدهند چتها در آموزش شرکت کنند و زمان نگهداری این دادهها تا زمانی که تنظیمات فعال باشد، به پنج سال افزایش یافته است. ترافیک مربوط به Claude for Work، بخشهای دولتی، آموزشی و API از این مورد مستثنی هستند.
- Google (Gemini): در صورتی که «فعالیتهای اپلیکیشن جمینای» (Gemini Apps Activity) روشن باشد (که حالت پیشفرض است)، زیرمجموعهای از گفتگوها ممکن است توسط بازبینهای انسانی خوانده شود و تا سه سال نگهداری گردد. گوگل در اطلاعیه حریم خصوصی خود صراحتاً هشدار میدهد که کاربران نباید اطلاعات محرمانهای را وارد کنند که نمیخواهند یک بازبین انسانی آن را ببیند.
در حالی که سطوح تجاری معمولاً دادهها را از آموزش مستثنی میکنند، اما سیاستهای شرکتی نمیتوانند ردیابی کنند که یک کارمند در ساعت ۶ عصر، هنگام فشار برای رسیدن به ضربالاجل (deadline)، از کدام حساب استفاده میکند.
هزینه هوش مصنوعی سایه (Shadow AI)
این شکاف بین سیاستهای شرکتی و رفتار واقعی کاربران، موتور محرک پدیده «هوش مصنوعی سایه» (Shadow AI) است؛ یعنی استفاده از ابزارهای AI خارج از تاییدیه بخش IT. گزارش ۲۰۲۵ شرکت IBM درباره هزینه نشت دادهها (Cost of a Data Breach Report) نشان داد که از هر پنج سازمان، یک مورد دچار نشت داده از طریق این ابزارهای تایید نشده شده است.
شرکتهایی که سطوح بالای هوش مصنوعی سایه داشتند، شاهد افزایش هزینههای نشت داده بهطور میانگین ۶۷۰,۰۰۰ دلار بودند. علاوه بر این، ۶۵٪ از این حوادث منجر به به خطر افتادن اطلاعات شناسایی شخصی (PII) مشتریان شد که بهطور قابلتوجهی بالاتر از میانگین جهانی (۵۳٪) است.
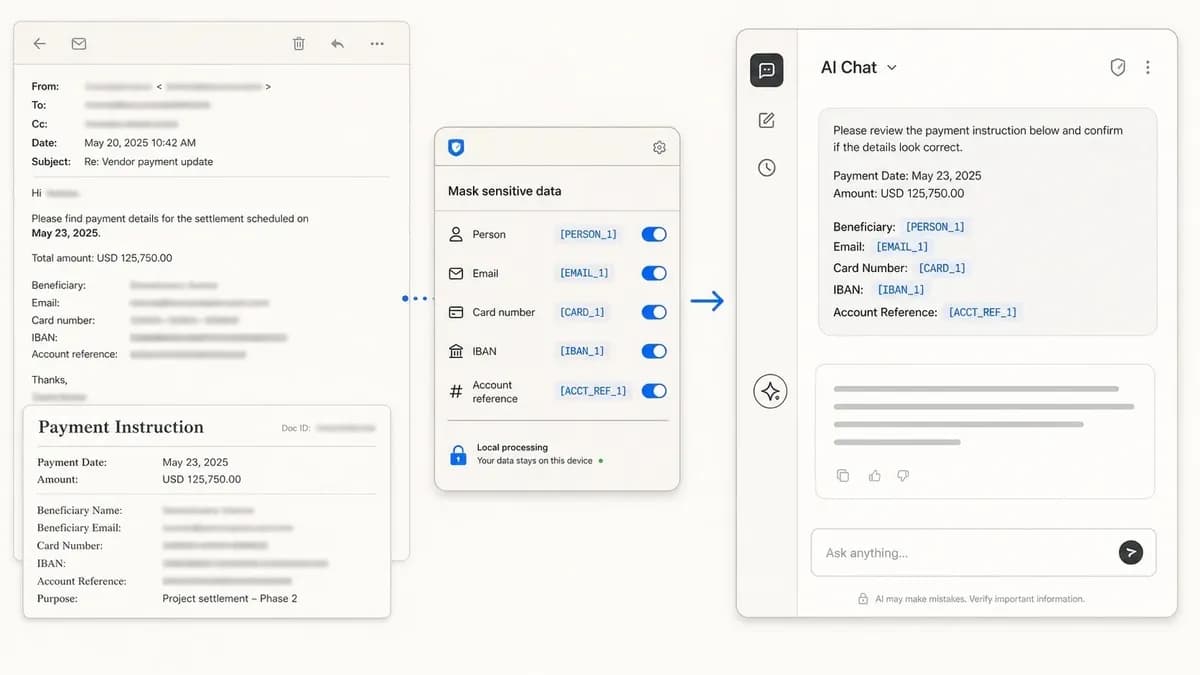
سازوکار: ماسکگذاری محلی PII
ماسکگذاری PII (Personally Identifiable Information) — شبیه به یک فیلتر محلی بین متن مبدأ و پرامپت هوش مصنوعی عمل میکند. این سازوکار مقادیر حساس را شناسایی کرده و آنها را با جایگاهداران (placeholders) پایداری مانند [PERSON_1] یا [EMAIL_1] جایگزین میکند. شمارهگذاری یکسان باعث میشود مدل روابط را بفهمد؛ اگر یک مشتری سه بار در متن تکرار شود، هر سه بار [PERSON_1] میماند تا مدل بتواند بدون دانستن هویت واقعی، ردیابی کند که چه کسی چه کسی است.
این فرآیند باید بهصورت محلی در مرورگر رخ دهد. اگر ابزار ماسکگذاری متن خام را برای پاکسازی به سرور شخص ثالث بفرستد، خودِ ابزار به یک نقطه شکست (single point of failure) جدید تبدیل میشود. پردازش روی دستگاه تضمین میکند که شناسههای خام هرگز از کنترل مستقیم کاربر خارج نشوند. پردازش محلی همچنین پارادوکس این موضوع را حل میکند که آیا ابزاری که از دادههای شما محافظت میکند، خودش از آن دادهها محافظت میکند یا خیر.
تشخیص دادههای حساس معمولاً در دو دسته قرار میگیرد:
- شناسههای ساختارمند (Structured Identifiers): اینها از فرمتهای دقیق و قطعی پیروی میکنند.
- شمارههای کارت پرداخت: معمولاً ۱۳ تا ۱۹ رقم هستند و از طریق «چکدایجت لون» (Luhn check digit) تایید میشوند.
- IBANها: با یک کد دو حرفی کشور شروع میشوند و تحت مجموع چکسام mod-97 تعریف شده در استاندارد ISO 13616 تایید میگردند.
- شناسههای امارات (Emirates IDs): توالیهای ۱۵ رقمی که با ۷۸۴ (کد کشور امارات) شروع شده و به دنبال آن سال تولد دارنده، یک شماره سریال و یک رقم چکسام میآید.
- ایمیلها و شماره تلفنها: از فرمتهای شناخته شده و مبتنی بر الگو (pattern-based) پیروی میکنند. در همین راستا، ابزارهای پیشرفتهای نظیر Verifly برای مدیریت ایمیلها در عاملهای هوشمند طراحی شدهاند تا صحت دادهها و تحویلپذیری آنها را در سیستمهای اتوماسیون تضمین کنند.
- موجودات غیرساختارمند (Unstructured Entities): نام افراد، نام شرکتها، آدرسهای خیابان و عناوین پروژهها هیچ چکسام یا فرمت ثابتی ندارند. تشخیص آنها بر اساس حروف بزرگ، کلمات زمینهای (Context words) و لیستهای نامهای شناخته شده است. چون این روش ممکن است نامهایی با املای غیرمعمول را نادیده بگیرد یا نام محصولات را به اشتباه شناسایی کند، مرحله «بازبینی دستی» (manual review) الزامی است.
چه چیزی را ماسک کنیم و چه چیزی را نگه داریم؟
ماسکگذاری همهچیز باعث میشود هوش مصنوعی بیفایده شود. اگر هر عدد و تاریخی را حذف کنید، مدل نمیتواند درباره تکلیف استدلال کند و پاسخهای کلی و عمومی (generic) میدهد. کلید کار، حفظ مقادیری است که تکلیف به آنها وابسته است و حذف شناسههاست. یک تست ساده: آیا هوش مصنوعی میتواند بدون این مقدار خاص، به سوال کاری پاسخ دهد؟
| نگه داشتن (Visible) | مثال | دلیل کمک به مدل |
|---|---|---|
| مبالغ | ۱۸,۵۰۰ درهم یا ۱۲۵,۷۵۰ دلار | اجازه استدلال درباره اندازه پرداخت، آستانهها و نحوه بیان |
| تاریخها | ۱۴ ژوئن یا سه ماهه سوم ۲۰۲۶ | ضروری برای پیشنویس خطوط زمانی و ضربالاجلها |
| نقشهای کلی | مشتری، فروشنده، کارمند | حفظ زمینه تجاری بدون افشای هویت |
| دستهبندی مشکل | درخواست استرداد وجه، فاکتور گمشده | کمک به مدل برای انتخاب نوع پاسخ مناسب |
| ساختار سند | ردیفهای جدول، نقاط گلولهای (bullets) | حفظ شکل و ساختار مطالب مبدأ |
| قوانین غیرحساس | تاییدیه برای مبالغ بالای ۵۰,۰۰۰ درهم نیاز است | اجازه میدهد مدل دستورات داخلی را اعمال کند |
گردشکار ۵ مرحلهای مرورگر
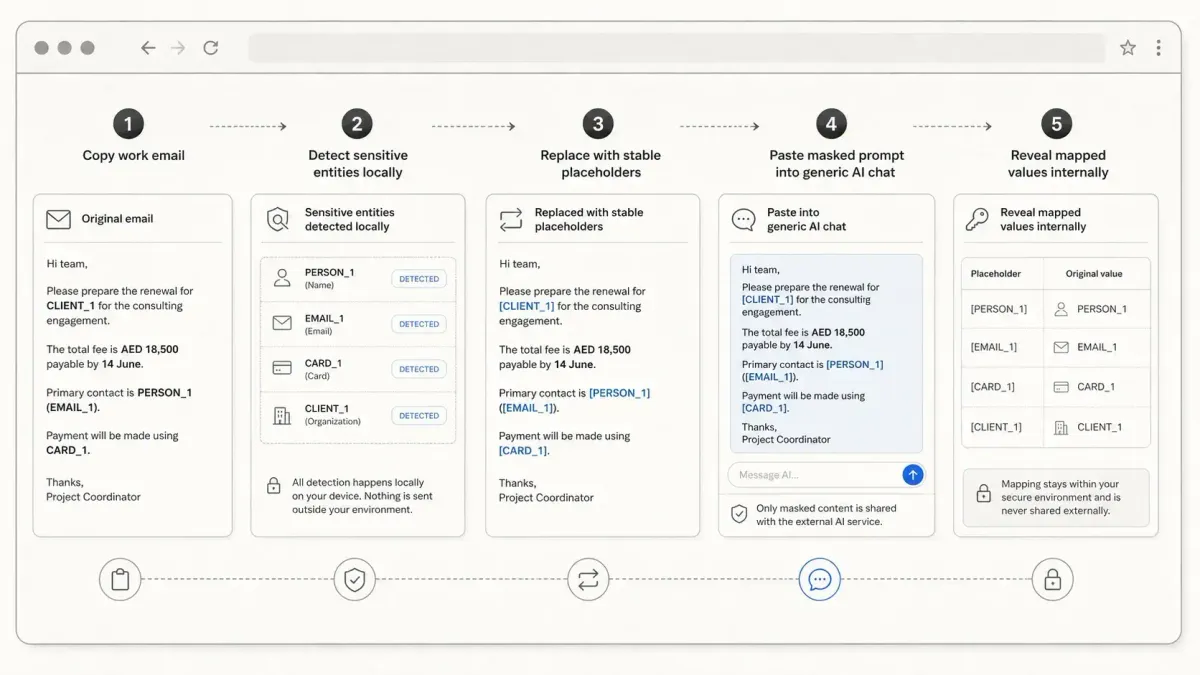
یک گردشکار ماسکگذاری حرفهای، مانند آنچه در Privacy Mask توسط Paperwork اجرا میشود، از یک حلقه دقیق پیروی میکند:
۱. کپی (Copy): کاربر متن خام کاری را برمیدارد. مثال: «سلام سارا، لطفاً استرداد مبلغ ۴,۲۰۰ درهم برای راشد المری، کارت به شماره پایان ۴۸۲۱، حساب REF-88213 را تایید کن. قبل از ۱۴ ژوئن با او به ایمیل [email protected] تماس بگیر.»
۲. تشخیص (Detect): یک افزونه متن را بهصورت محلی اسکن میکند. در این مثال، افزونه دو نام، یک ایمیل، بخشی از یک کارت و یک رفرنس حساب را مییابد.
۳. بازبینی (Review): کاربر ماسک را تایید میکند. او مطمئن میشود که مبلغ (۴,۲۰۰ درهم) و ضربالاجل (۱۴ ژوئن) باقی بمانند، در حالی که هویتها پنهان شوند.
۴. چسباندن (Paste): پرامپت ماسکشده («سلام [PERSON_2]، لطفاً استرداد مبلغ ۴,۲۰۰ درهم برای [PERSON_1]، کارت [CARD_1]، حساب [ACCT_REF_1] را تایید کن...») به هوش مصنوعی ارسال میشود.
۵. کشف (Reveal): کاربر نقشهی محلی (local mapping) را در مرورگر باز میکند تا پاسخ هوش مصنوعی را دوباره به مشتری واقعی و جزئیات تماس مرتبط کند.
کاربردهای تخصصی هر بخش
مالیات و پرداختها:
برای تیمهای مالی، ماسکگذاری برای رعایت استاندارد PCI DSS یک ضرورت است. کپی کردن یک شماره حساب اصلی (PAN) در یک پرامپت عمومی، تقریباً تمام کنترلهای تعریف شده در این استاندارد را نقض میکند.
- باید ماسک شوند: شماره کارتها، حسابهای بانکی، IBANها، نام ذینفعان و شناسههای پرداخت داخلی.
- باید باقی بمانند: مبالغ، ارزها، تاریخهای سررسید و آستانههای تایید.
صورتحسابهای بانکی و تطبیق (Reconciliation):
کارکنانی که بخشهایی از صورتحساب را برای بررسی مجموع ارقام کپی میکنند، باید نام دارنده حساب و طرف مقابل را ماسک کنند اما ارقام مالی را نگه دارند. برای بررسیهای دورهای صورتحساب در مقیاس تیمی، یک گردشکار تحلیل سند ساختاریافته (structured document analysis) بر پنجره چت ترجیح داده میشود تا استخراج و ثبت (logging) بهتری صورت گیرد.
عملیات منابع انسانی (HR) و حقوقی:
در این بخشها، ریسک بر اساس «زمینه» (context) است. همانطور که در NIST SP 800-122 ذکر شده، یک نام کوچک بهتنهایی ممکن است PII نباشد، اما نامی که در کنار حقوق و یک شکایت قرار گرفته باشد، هست.
- باید ماسک شوند: ایمیلهای متقاضیان، شناسههای کارکنان، جزئیات پزشکی، طرفین شکایت و نام پروژههای محرمانه.
- نتیجه: مدل همچنان در مورد لحن، ساختار و شناسایی مسائل کمک میکند، بدون اینکه بداند درباره چه کسی صحبت میشود.
پشتیبانی مشتریان:
تیمهای پشتیبانی از AI برای کوتاهتر کردن پاسخها یا دستهبندی شکایات استفاده میکنند. یک پرامپت ماسکشده همچنان میتواند بیان کند که [CUSTOMER_1] درباره یک فاکتور تأخیری به مبلغ ۴,۲۰۰ درهم شکایت کرده است؛ این به AI اجازه میدهد پیشنویس پاسخی را بنویسد که کارشناس سپس آن را با مقادیر واقعی در CRM بازیابی میکند. این رویکرد به ویژه در پیادهسازی سیستمهای پاسخگویی خودکار کاربرد دارد، مشابه آنچه در مقایسه ابزارهایی چون Bland AI و Vapi برای عاملهای صوتی دیده میشود، جایی که حفظ حریم خصوصی در عین تعامل طبیعی با مشتری کلیدی است.
حاکمیت و انطباق (Governance and Compliance)
ماسکگذاری با قوانین بینالمللی و استانداردهای امنیتی همسو است:
- قانون شماره ۴۵ سال ۲۰۲۱ امارات (Federal Decree-Law No. 45): پردازش دادههای شخصی بدون رضایت را ممنوع کرده و سازمانها را ملزم به حفظ محرمانگی میکند. کپی کردن جزئیات در یک هوش مصنوعی مصرفکننده، استفادهای از دادهها است که احتمالاً این تعهدات دور میزند.
- ماده ۵(۱)(c) GDPR: ایجاب میکند که دادهها «کافی، مرتبط و محدود به آنچه ضروری است» باشند. ماسکگذاری با حذف هویتهای غیرضروری برای انجام تکلیف، این اصل را پیاده میکند.
- PCI DSS: شماره حساب اصلی را به عنوان دادهای تلقی میکند که باید در هر کجا که ظاهر میشود، از جمله پنجرههای چت، محافظت شود.
تحلیل: تغییر به سمت کنترل در سطح فردی
سالها بود که صنعت بر «درگاه سازمانی» (Enterprise Gateway) تمرکز داشت؛ این ایده که IT میتواند یک سایت را مسدود کند یا نسخه شرکتی Claude را فراهم کند. این روش به دلیل «اثر ضربالاجل» (deadline effect) شکست میخورد: کارکنان وقتی ابزار شرکتی بیش از حد کند یا محدودکننده باشد، از حسابهای شخصی خود در گوشی یا لپتاپهای خانگی استفاده میکنند.
ماسکگذاری محلی، مرز امنیتی را از شبکه به مرورگر منتقل میکند. این رویکرد میپذیرد که «پرامپت» بردار اصلی نشت داده است. با تبدیل هوش مصنوعی به یک «جعبه سیاه» که فقط جایگاهداران را دریافت میکند، سیاستهای آموزشی خاص هر ارائهدهنده دیگر اهمیتی ندارد.
این کار بهطور مؤثری بهرهوری را از حریم خصوصی جدا میکند. یک تیم میتواند از توانمندترین مدل موجود (حتی نسخه رایگان مصرفکننده) بدون ریسک نشت دادههای میلیون دلاری استفاده کند، به شرطی که نقشهی جایگزینی (mapping) روی دستگاه محلی باقی بماند.
اشتباهات رایج در ماسکگذاری
ماسکگذاری در الگوهای پیشبینیپذیری شکست میخورد. برای اجتناب از آنها، تیمها باید این عادتها را اتخاذ کنند:
- ماسکگذاری بیش از حد (Over-masking): حذف هر عدد یا تاریخی منجر به پاسخهای کلی میشود. مقادیر ضروری برای تکلیف را نگه دارید.
- جایگاهداران ناسازگار: استفاده از تگهای مختلف برای یک شخص، مدل را گیج میکند. از شمارهگذاری پایدار استفاده کنید (بهطور مداوم [PERSON_1]).
- راه-نفوذ اسکرینشات (The Screenshot Loophole): ماسک کردن متن اما ضمیمه کردن یک اسکرینشات خام. تصاویر، PII اصلی را از سد ماسک عبور میدهند.
- نشت بازخورد (The Feedback Leak): کپی کردن مجدد مقادیر اصلی در چت برای «بررسی» پاسخ. این کار دوباره باعث نشت داده میشود.
- انحراف گردشکار (Workflow Drift): برخورد با ماسکگذاری به عنوان یک پاکسازی یکباره. این فرآیند باید در سیاست رسمی استفاده از AI در تیم ادغام شود.
محدودیتها و پیشنیازها
ماسکگذاری یک راه حل مطلق نیست. برخی ریسکها باقی میمانند:
- تکالیف وابسته به هویت: بررسیهای Due-diligence یا تداخل منافع (conflict checks) روی اشخاص نامگذاری شده خاص را نمیتوان ماسک کرد. این موارد نیازمند سیستمهای تایید شده با کنترلهای دسترسی سختگیرانه هستند.
- نشت استراتژی: یک بند در قرارداد ممکن است همچنان قیمتگذاری یا استراتژی را فاش کند، حتی اگر طرفین حذف شده باشند.
- بازشناسی از طریق زمینه غنی (Rich Context Re-identification): پرامپتی که «مدیر مالی یک مشتری نامبرده که در ژوئن استعفا داد» را توصیف میکند، بدون ذکر نام، شخص را شناسایی میکند. مرحله بازبینی انسانی تنها راه شناسایی این موارد است.
- دقت هوش مصنوعی: ماسکگذاری توهمات (hallucinations) یا جمعهای اشتباه را برطرف نمیکند. بازبینی معمول کاری همچنان مورد نیاز است.
افزونه Privacy Mask
Privacy Mask یک افزونه کروم توسط Paperwork است که در یک پنل کناری در کنار ابزارهایی مثل ChatGPT، Claude، Gemini، Grok، Copilot، DeepSeek و Perplexity قرار میگیرد. این ابزار به کاربران اجازه میدهد انواع موجودات خاص (شخص، ایمیل، کارت، IBAN، رفرنس حساب) را فعال یا غیرفعال کنند. چون بهصورت محلی عمل میکند، مقادیر خام هرگز به سرور Paperwork ارسال نمیشوند.
برای کسانی که با کل فایلها، آپلودهای دستهای (batch uploads) یا نیاز به گزارشهای حسابرسی (audit logs) سر و کار دارند، یک گردشکار کامل «ناشناسسازی سند» (Document Anonymization) انتخاب درستی است. در حالی که یک افزونه مرورگر برای لحظات سریع کپی-پیست مناسب است، سرویسهای ناشناسسازی، سیاستهای اجباری، مسیر یابی API و توکنگذاری قطعی (deterministic tokenization) را برای بررسیهای تنظیمشده فراهم میکنند.
گام بعدی: برای ایمن کردن تیم خود، سیاست فعلی استفاده از AI را بازبینی کنید تا ببینید آیا لیست مشخصی از «موجودات حساس» (Sensitive Entities) که باید پیش از ارسال هر پرامپت ماسک شوند، تعریف شده است یا خیر.



گفتگو