تصور کنید میخواهید یک مدل پیشبینی قیمت سهام بسازید، اما به جای تمرکز بر منطق، ساعتها وقت خود را صرف نوشتن کدهای تکراری برای گرادیانها و دستهها میکنید. اگر هنوز برای مدیریت چرخههای آموزش از کدهای طولانی و دستی استفاده میکنید، زمان آن رسیده است که با استانداردهای جدید آشنا شوید و بررسی کنید که چه پل دقیقی برای اتصال یک سلول ریاضی به حلقه آموزش هنگام ساخت یک مدل LSTM از ابتدا مورد نیاز است. در این راستا، درک ساختار داخلی این مدلها ضروری است؛ شما میتوانید جزئیات بیشتری را در مورد نحوه ساخت یک واحد حافظه کوتاهمدت و بلندمدت با Lightning AI مطالعه کنید.
طبق گزارشی که در ۲۶ ژون ۲۰۲۶ در وبسایت dev.to منتشر شد، یک راهنمای فنی توضیح داد که چگونه میتوان تابع training_step() را با استفاده از پایتورچ لایتنینگ (PyTorch Lightning) پیادهسازی کرد تا این انتقال بهطور بهینه مدیریت شود. در واقع، مدیریت دستی دستهها (batch) و گرادیانها در پایتورچ استاندارد، اغلب منجر به کدهایی بسیار طولانی و مستعد خطا میشود. با استفاده از لایتنینگ، توسعهدهندگان میتوانند کدهای تکراری (boilerplate) را تجرید کنند و تنها بر منطق اصلی تمرکز نمایند: پیشبینی یک مقدار و اندازهگیری میزان خطا.
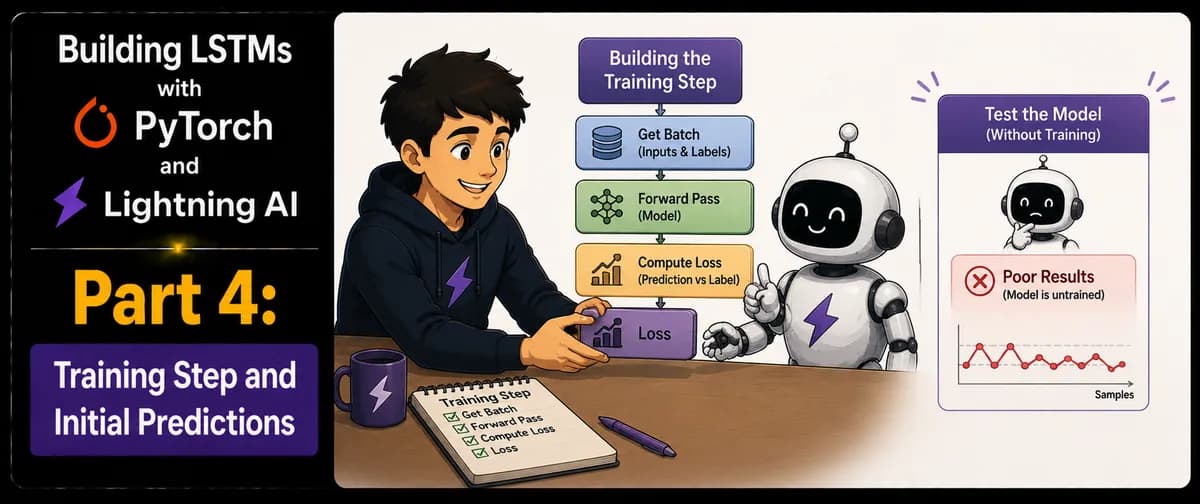
به نقل از این آموزش، تابع training_step() سه عملیات کلیدی و प्राथमिक را مدیریت میکند:
- پیشبینی: ارسال یک دسته از دادههای آموزش به متد
forward()برای تولید یک خروجی. - محاسبه زیان: تعیین تفاضل مجذور (Squared Residual) میان مقدار پیشبینیشده و برچسب مشاهدهشده (observed label). این مرحله مانند یک خطکش برای اندازهگیری میزان اشتباه مدل عمل میکند.
- ثبت خودکار: استفاده از تابع
log()برای ذخیره زیان آموزش و پیشبینیها برای موجودیتهای خاص (مثلاً شرکت A در مقابل شرکت B) در دایرکتوریlightning_logsبرای تحلیلهای بعدی.

برای آزمایش منطق مدل پیش از شروع آموزش کامل، این راهنما نحوه ارسال یک تنسور از قیمتهای سهام برای روزهای ۱ تا ۴ را نشان میدهد. مدل مقدار روز ۵ را پیشبینی کرده و هم پیشبینی و هم گراف محاسباتی (computation graph) مربوط به آن را برمیگرداند. در اینجا کاربران باید متد .detach() را فراخوانی کنند تا پیشبینی از گراف جدا شود و یک خروجی پاکیزه و بدون وابستگیهای محاسباتی نمایش داده شود.
در تستهای اولیه، مدل آموزشندیده نتایج متناقضی را نشان داد. برای «شرکت A»، پیشبینی به مقدار مشاهدهشده یعنی ۰ نسبتاً نزدیک بود، اما برای «شرکت B»، پیشبینی مقدار ۰.۲۳۶۰- را نشان داد که فاصله بسیار زیادی با مقدار مورد انتظار یعنی ۱ داشت.
این شکاف یک حقیقت بنیادی در یادگیری ماشین (ML) را اثبات میکند: یک معماری که بهدرستی پیادهسازی شده باشد، بدون وزنهای بهینهشده کاملاً بیفایده است. شکست مدل آموزشندیده در این مرحله ثابت میکند که بهینهساز Adam و فرآیند پسانتشار (backpropagation) برای اصلاح و پالایش تنسورهای داخلی مدل ضروری هستند.
برای توسعهدهندگان، این بدان معناست که «لولهکشی» (plumbing) مدل اکنون کامل شده است. تمرکز حالا از تعریف اینکه مدل «چگونه فکر کند» به این تغییر میکند که به او «چگونه از دادهها یاد بگیرد» آموزش دهند.
برای بهبود بیشتر دقت، توسعهدهندگان باید اکنون چرخه کامل آموزش را پیادهسازی کنند تا زیان تفاضل مجذور را در مجموعهدادههای بزرگتر به حداقل برسانند.
گام بعدی شما
- پیادهسازی کامل چرخه آموزش برای کاهش میانگین مربعات خطا (MSE) در مجموعهدادههای بزرگتر.
- تست مدل با دادههای خارج از توزیع (OOD) برای بررسی تعمیمپذیری.
- بررسی اثر تغییر نرخ یادگیری بر سرعت همگرایی مدل.
اما بهینهسازی این مدلها تنها بخشی از ماجراست؛ اثر استفاده از سختافزارهای تخصصی بر سرعت استنتاج را در بررسی ما درباره TPUها بخوانید.



گفتگو