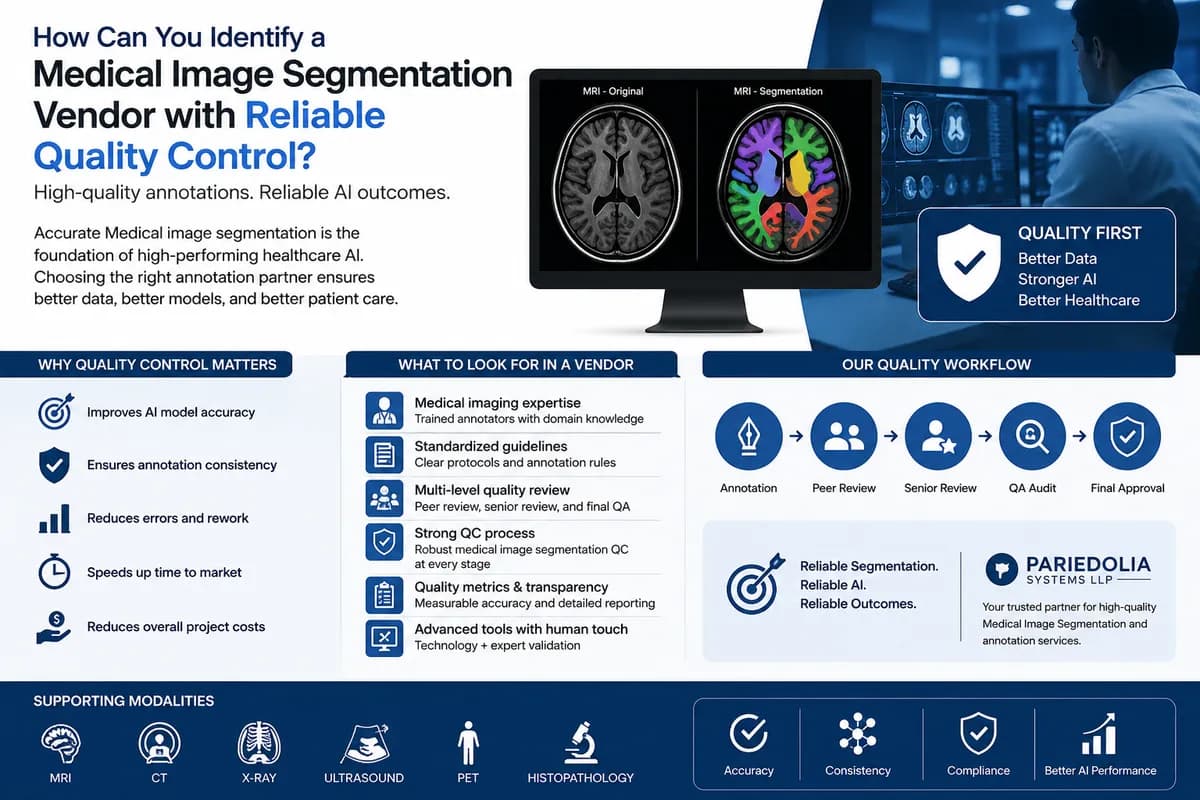
اگر تصور کنید چند پیکسل خطا در یک تصویر MRI میتواند مرز بین تشخیص درست و یک خطای مرگبار پزشکی باشد، متوجه میشوید چرا دقت دادهها از قدرت پردازش مهمتر است. بر اساس گزارش ۳ جولای ۲۰۲۶ از شرکت Pariedolia Systems LLP، دادههای پزشکی با برچسبگذاری ضعیف، سقفی برای عملکرد مدل ایجاد میکنند که هیچ مقدار اضافهی توان محاسباتی نمیتواند آن را بشکند.
قطعهبندی تصویر (Image Segmentation) — شبیه به این است که یک نقاش با دقت تمام، دور هر توده یا رگ خونی در عکسهای MRI و CT را با یک رنگ خاص بکشد تا مدل بفهمد دقیقاً کجای تصویر چیست — برای ایجاد «داده مرجع» (Ground Truth) در یادگیری ماشین ضروری است. در این حوزه، هرگونه ناهماهنگی در برچسبها باعث میشود مدل در محیطهای واقعی دچار تعمیمپذیری ضعیف شود و نرخ مثبتکاذبها بهشدت بالا برود.
همانطور که در تحلیلهای پیشین ما دربارهی امنیت دادههای حساس اشاره کردیم، کیفیت ورودی تعیینکنندهی خروجی است. به نقل از Pariedolia Systems LLP، برای حل این مشکل باید از یک جریان کنترل کیفیت (QC) سیستماتیک استفاده کرد. بازبینی موثری در قطعهبندی، فراتر از چکهای بصری ساده است و نیازمند یک فرآیند چندمرحلهای است که بر محورهای زیر میچرخد:
- دقت مرزها و ثبات در برچسبگذاری
- صحت بالینی و کامل بودن مجموعهدادهها
- دستورالعملهای استاندارد برچسبگذاری و بازبینی توسط همتیمیها (Peer Review)
- حسابرسیهای تصادفی کیفی و بازخورد مستمر به بازبینها
طبق اعلام این شرکت، اجرای سختگیرانه این بازرسیها در مراحل اولیه، زمان توسعه در مراحل بعدی را کاهش میدهد. در غیر این صورت، تیمها با چرخههای آموزشی طولانیتر و بازنگریهای هزینهبر در مجموعهدادهها مواجه میشوند که کل بودجه پروژه را میبلعد.
برای تیمهای هوش مصنوعی، این تغییر به معنای گذار از ذهنیت «دادهی بیشتر، بهتر است» به رویکرد «دادهی باکیفیتتر، بهتر است» است. اولویت دادن به کیفیت برچسبگذاری، تنها راه ساخت سامانههایی است که در محیطهای واقعی بالینی درست عمل کنند، نه فقط روی کاغذ و بنچمارکها.
این رویکرد در واقع برچسبگذاری داده را به جای یک کار اداری ساده، به عنوان یک فرآیند بالینی میبیند. سازمانها با ادغام ارزیابیهای کیفی ارشد و ردیابی عملکرد، یک لایهی اعتماد بین تصویر خام و مدل ایجاد میکنند.
تیمها چه بهصورت داخلی و چه با پیمانکاران خارجی کار کنند، باید پیش از شروع آموزش مدل، مجموعهدادهها را با معیارهای تعریفشده اعتبارسنجی کنند. این کار از چرخه هزینهبرِ کشف خطاهای برچسبگذاری پس از شکست مدل در مرحله آزمون جلوگیری میکند.
گام بعدی شما
- خطوط لولهی فعلی برچسبگذاری خود را با یک چارچوب بازبینی چندسطحی تطبیق دهید تا نقاط نشت دقت شناسایی شوند.
- برای دادههای حیاتی، معیارهای توافق بین برچسبگذاران را به عنوان شرط پذیرش دادهها تعریف کنید.
- بهجای افزایش حجم داده، روی تطهیر (Cleaning) دادههای موجود تمرکز کنید.
اما تأثیر این دقت بر کاهش هزینههای استنتاج در مقیاس وسیع حتی حیاتیتر است — به تحلیل ما دربارهی بهینهسازی حافظه در مدلهای پزشکی مراجعه کنید.



گفتگو