
تصور کنید گرانترین GPUهای دنیا را خریدهاید، اما آنها صرفاً منتظرند تا یک پردازش سادهی پایتونی به پایان برسد. این «دیوار GIL» دقیقاً همان جایی است که بهرهوری مدلهای زبانی بزرگ در مقیاس صنعتی متوقف میشود.
در ۳۰ آوریل ۲۰۲۶، بنیاد LightSeek با معرفی Shepherd Model Gateway (SMG) این ناکارآمدی را هدف قرار داد. به نقل از گزارش pytorch.org، این ابزار کل بار کاری CPU را از مسیر GPU جدا کرده و فرآیندهای توکنایز کردن، دیتوکنایز کردن و سازماندهی ابزارها را به یک لایهی سرویسدهندهی خالص در زبان Rust منتقل میکند که از طریق gRPC ارتباط برقرار میکند.
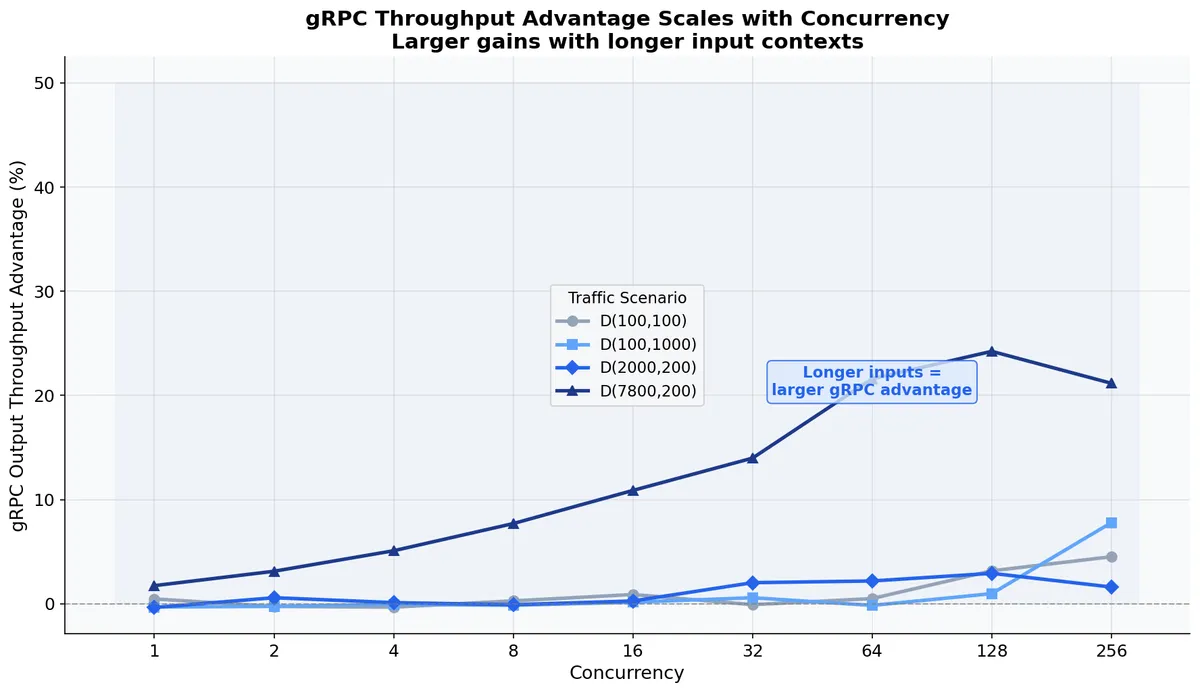
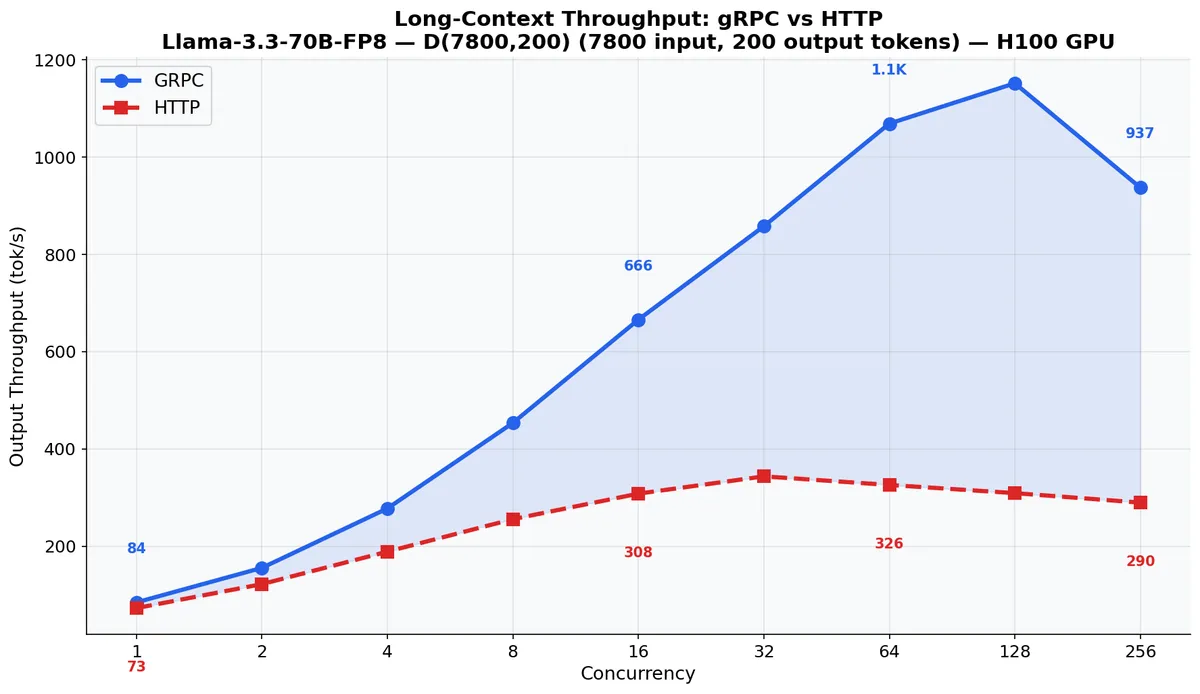
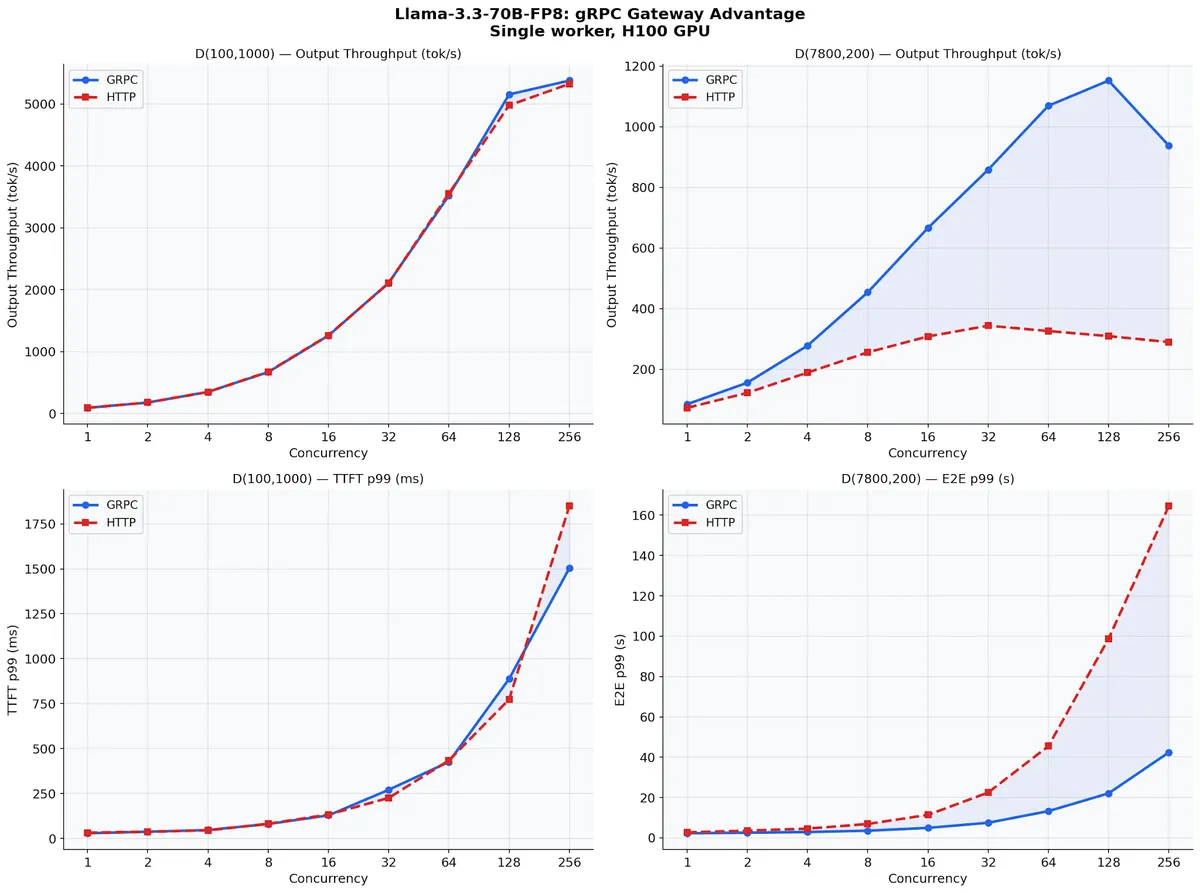
طبق اعلام این بنیاد، بیشترین جهش عملکرد در سناریوهای با ترافیک بالا و بافتار بلند (Long-context) دیده میشود. در بنچمارکهای مربوط به مدل Llama-3.3-70B-FP8 با ورودیهای ۷,۸۰۰ توکنی، SMG توانست نرخ خروجی را از ۳۲۷ توکن در ثانیه به ۱,۱۵۰ توکن برساند؛ یعنی افزایشی ۳.۵ برابری در سرعت استنتاج (Inference).
دستاوردهای فنی کلیدی این سیستم عبارتاند از:
- پردازش چندوجهی (Multimodal) بومی در Rust: بازنویسی کامل پردازشگرهای تصویر Hugging Face برای حذف کامل سربار پایتون.
- کش توکنایزر دو سطحی: سیستمی با دو لایه L0 (تطبیق دقیق) و L1 (آگاه از پیشوند) که توکنایز کردن را از مسیر موتور استنتاج خارج میکند.
- مسیریابی آگاه از کش: بازنویسی جریان مسیریابی که ۱۰ تا ۱۲ برابر سریعتر شده و میانگین زمان رسیدن به اولین توکن (TTFT) را در ۸ نسخه Llama تا ۲۳٪ کاهش داده است.
علاوه بر سرعت، SMG قابلیت سازماندهی ابزارهای پروتکل بافتار مدل (Model Context Protocol - MCP) و یک میانافزار مبتنی بر WASM را برای توسعهپذیری ایزوله فراهم میکند. این یعنی توسعهدهندگان میتوانند مدلهای Llama یا Qwen را با قابلیتهای داخلی مشابه GPT-4 مستقر کنند، بدون اینکه نیاز به تغییر در موتور استنتاج اصلی باشد.
همانطور که در تحلیل قبلی ما دربارهی بهینهسازی زیرساختهای استنتاج اشاره کردیم، SMG نشاندهندهی گذار به سمت زیرساختهای سطح حرفهای است. در این مدل، گیتوی به عنوان یک لایهی هوشمند و مستقل عمل میکند تا موتور استنتاج صرفاً بر محاسبات تانسوری تمرکز کند و لایهی Rust تمام کارهای «اداری» خط لوله هوش مصنوعی زاینده (Generative AI) را مدیریت کند.
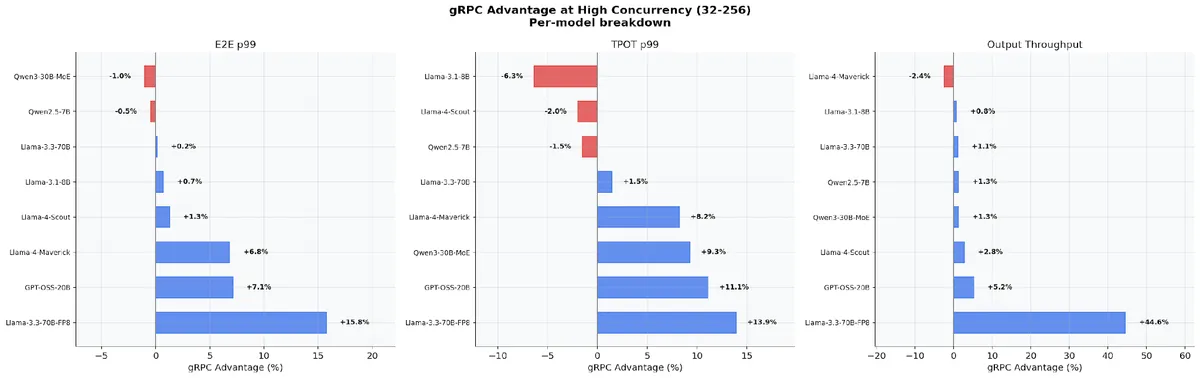
با پذیرش این فناوری در گوگل کلاد (Google Cloud Platform)، اوراکل (Oracle Cloud Infrastructure) و TogetherAI، صنعت به سمتی میرود که پشتهی سرویسدهی به اندازه خودِ وزنهای مدل بهینه شود. اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- بررسی جایگزینی لایههای پیشپردازش پایتونی با پیادهسازیهای Rust برای کاهش تأخیر.
- مطالعه مستندات MCP برای پیادهسازی ابزارهای پیشرفته در مدلهای وزنباز.
- ارزیابی تأثیر کاهش TTFT بر تجربه کاربری در اپلیکیشنهای چتبات.



گفتگو