
نمونههای اولیه در Jupyter Notebook هرگز یک محصول نیستند؛ تبدیل آنها به یک سرویس ابری پایدار، نیازمند عبور از 실험های احتمالی به نظم سختگیرانه مهندسی است. طبق اعلام TechCirkle، مدلها تنها زمانی ارزش تجاری قابلاتکا تولید میکنند که توسط چارچوبهای ارزیابی خودکار، ذخیرهسازهای ویژگی قطعی و لایههای ارکستراسیون مقاوم پشتیبانی شوند.
بسیاری از سازمانها در «شکاف نمونه اولیه» دستوپنجه نرم میکنند؛ وضعیتی که مدل در محیط ایزوله عالی عمل میکند اما در برابر ترافیک واقعی شکست میخورد. این چالش دقیقاً همان نقطهای است که ناهماهنگی میان دموهای ناپایدار و حاکمیت صنعتی را آشکار میکند. در حالی که مهندسی نرمافزار سنتی بر ساختارهای منطقی و قانونمحور استوار است، بازارهای امروز نیازمند سیستمهایی هستند که بهصورت پویا تطبیق یابند. در ۲۱ ژوئن ۲۰۲۶، تیم TechCirkle ماتریس زیرساختی خاصی را برای پر کردن این شکاف معرفی کرد تا تمرکز را از انتخاب صرفِ مدل به موتور محاسباتی زیربنایی منتقل کند.
یادگیری ماشین پارادایم محاسبات را از شاخههای شرطی سختافزاری به الگوهای احتمالی تغییر میدهد. این تغییر به کسبوکارها اجازه میدهد روندهای پنهان سیستم را شناسایی، لجستیکهای پیچیده را بهینه و نقاط تماس کاربر را در مقیاس وسیع شخصیسازی کنند. همگرایی این علوم داده با استراتژیهای هوش مصنوعی در واقع پیششرط اصلی برای دستیابی به چنین مقیاسپذیری در سطح سازمان است. اما انتقال از محیط اجرای محلی یک دانشمند داده به اکوسیستم سازمانی، نیازمند یک ماتریس زیرساختی منظم است. همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، زیرساخت همواره نقطه ضعف زنجیرهی ارزش AI است.

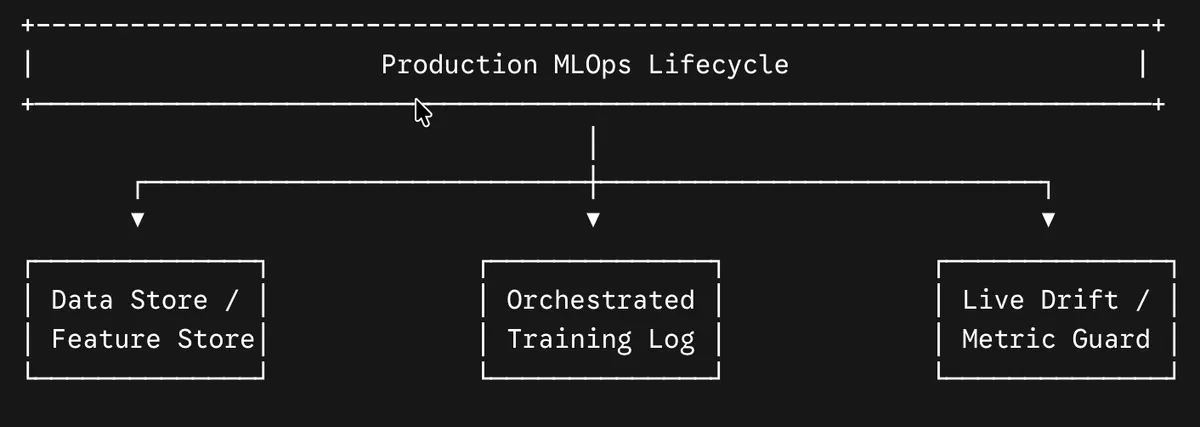
بر اساس مستندات معماری TechCirkle، مدلهای سطح عملیاتی بر این ستونهای فنی استوارند:
جزئیات: ماتریس زیرساختی
- تغذیه قطعی ویژگیها (Deterministic Feature Ingestion) — مثل یک سیستم تدارکاتی دقیق که تضمین میکند مواد اولیهی آشپزی در رستوران دقیقاً همان چیزی باشد که در دستور پخت نوشته شده است — با استفاده از Feature Storeهای متمرکز، پارامترهای آنی و دستهای را پاکسازی میکند. این روند تضمین میکند ساختارهای ریاضی در زمان آموزش با جریان دادههای زنده وب مطابقت داشته باشند.
- MLOps استاندارد شده: اجرای تنظیمات ردیابی سختگیرانه برای نظارت بر پارامترهای کد، کنترل نسخههای فعال مدل و مدیریت مخازن Image برای جلوگیری از بدهی فنی (Technical Debt) و عدم تطابق نسخهها. پیادهسازی این چارچوبها میتواند هزینههای استنتاج را در مقیاس تجاری به نصف کاهش دهد و بهرهوری عملیاتی را افزایش دهد.
- پایش مستمر و شناسایی رانش مفهوم (Concept Drift Detection) — شبیه به راداری که متوجه میشود سلیقه مشتریان تغییر کرده و نقشه قدیمی دیگر کاربرد ندارد — با استقرار حلقههای خودکار، زمانی را که روندهای دنیای واقعی تغییر کرده و مرزهای آموزشی قدیمی بیاعتبار میشوند، شناسایی میکند. پلتفرمها باید در صورت افت معیارهای عملکرد به زیر خط قرمز، خط لولههای بازآموزی خودکار را فعال کنند.
جزئیات: امنیت و حاکمیت
- حریم خصوصی دادهها: ایزولهسازی مجموعههای آموزشی در شبکههای مجازی و ماسک کردن دادههای کاربر پیش از رسیدن به لاگهای تغذیه برای رعایت الزامات قانونی.
- ردپای حسابرسی: ایجاد لاگهای مفصلی برای توضیح دقیق نحوه رسیدن مدل به پیشبینیهای خاص جهت شفافیت سازمانی.
مدیران مهندسی باید بین دو مسیر استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند، مثل خودِ آشپزی و نه دوره آموزش آن — تصمیم بگیرند: میزبانی مدلهای سنگین روی گرههای ابری مقیاسپذیر یا کامپایل نسخههای سبک برای اجرا روی سختافزار دستگاه (On-device). اپلیکیشنهای بومی میتوانند مدلهای بهینه شده را مستقیم روی تراشههای دستگاه اجرا کنند تا زمان پاسخگویی به حداقل برسد. این انتخاب مستقیماً بر تأخیر و هزینههای عملیاتی اثر میگذارد؛ هزینههایی که اگر گرههای محاسباتی با توان عملیاتی بالا بهینه نشوند، بهسرعت افزایش مییابند.
از دیدگاه معماری، این چرخش نشان میدهد که عصر هوش مصنوعی از فاز «کشف» به فاز «بهینهسازی» وارد شده است. ارزش دیگر در وجود مدل نیست، بلکه در قابلیت اطمینان و بهرهوری هزینه خط لوله (Pipeline) است. برای کاربر، این یعنی گلوگاه بازگشت سرمایه (ROI) در هوش مصنوعی، اکنون مهندسی داده است، نه وزنهای مدل.
برای پیادهسازی این الگوها، توسعهدهندگان باید ابتدا فرضیات پیشبینی هسته را از طریق یک نمونه اولیه هدفمند اعتبارسنجی کنند و سپس به سمت شبکه سفارشی گسترده بروند. این رویکرد ناب از انباشت بدهی فنی جلوگیری کرده و هزینههای ابری را در مراحل رشد اولیه مدیریت میکند. انتقال یک مدل پیشرفته از اعتبارسنجی آماری به یک محصول دیجیتال، نیازمند دانش عمیق در معماری ابری و طراحی منظم کد است.
گام بعدی شما
- پیش از مقیاسدهی، یک Feature Store ساده برای تطبیق دادههای آموزشی و عملیاتی پیاده کنید.
- مکانیزمهای شناسایی Concept Drift را در لایهی مانیتورینگ مدلهای خود بگنجانید.
- تحلیل هزینه-فایده بین اجرای ابری و اجرای روی دستگاه (On-device) را برای کاهش Latency بررسی کنید.
اما اثر این بهینهسازیها بر مدلهای عاملمحور حتی پیچیدهتر است؛ برای درک چگونگی ادغام این زیرساختها با گردشکارهای Agentic، تحلیل ما دربارهی معماری عاملها را بخوانید.
گفتگو