
باید بدانید که دوران افزایش سادهی قدرت محاسباتی برای ارتقای مدلهای بنیادی به پایان رسیده است. اگر تصور میکنید تنها راه رسیدن به مدلهای پیشرو، افزودن تعداد بیشتری GPU به خوشهها است، با واقعیت جدید مهندسی زیرساخت فاصله دارید.
طبق اعلام AWS در ۱۱ مه ۲۰۲۶، مرز پیشروی در مدلهای زبانی اکنون به یک رژیم مقیاسپذیری سهگانه تغییر یافته است: پیشآموزش (Pre-training)، پسآموزش (Post-training) و محاسبات زمان استنتاج (Test-time compute). هر سه محور، نیازمند همگرایی دقیق میان شتابدهندهها و شبکههایی با تأخیر بسیار پایین هستند.
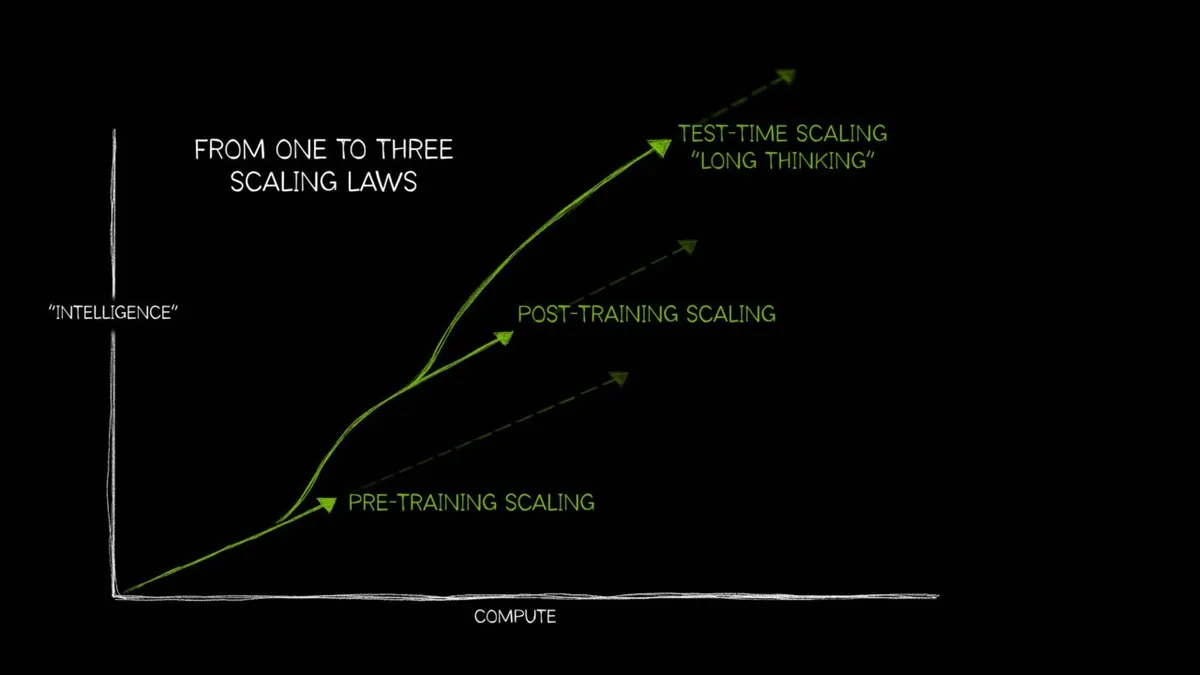
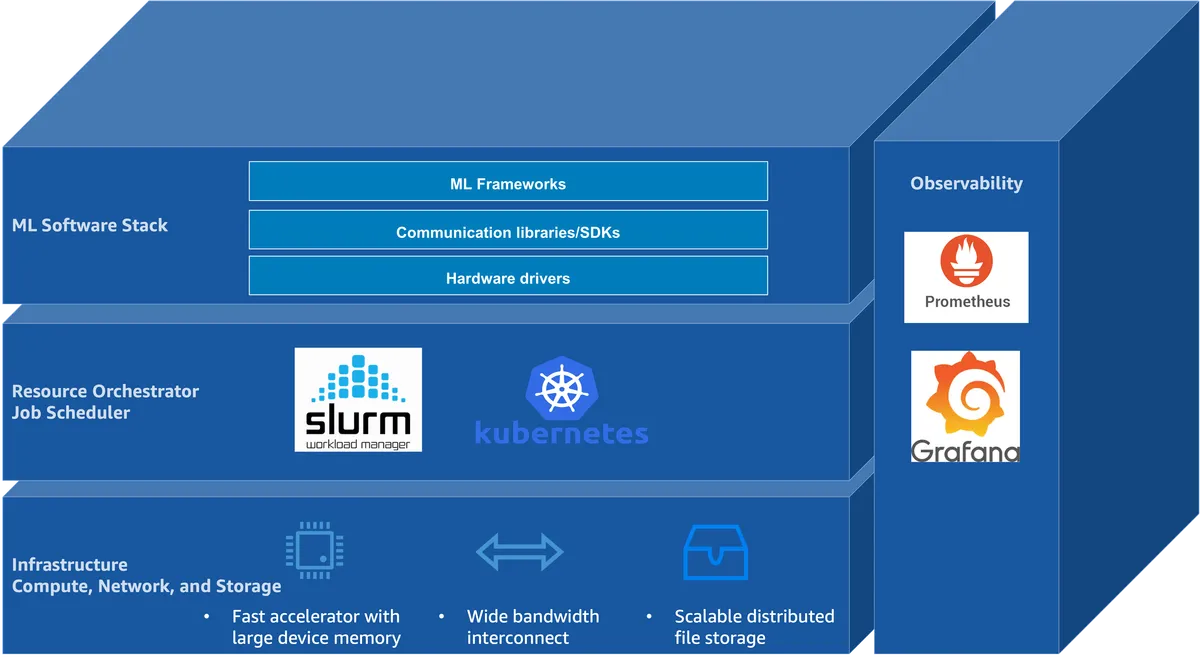
این چرخش در حالی رخ میدهد که صنعت از مقیاسپذیری تک-منحنی فاصله گرفته و به سمت معماریهای پیچیدهای مانند مجموعه متخصصان (Mixture-of-Experts یا MoE) حرکت میکند؛ جایی که سربار ارتباطی اغلب از توان پردازشی خام پیشی میگیرد. همانطور که در تحلیلهای پیشین ما دربارهی بهینهسازی مدلهای MoE اشاره کردیم، مدیریت توزیع توکنها در این مدلها، چالش اصلی سختافزاری است. برای حل این مسئله، AWS یک پشتهی چهارلایه شامل زیرساخت، ارکستراسیون، نرمافزار و مشاهدهپذیری (Observability) طراحی کرده است.
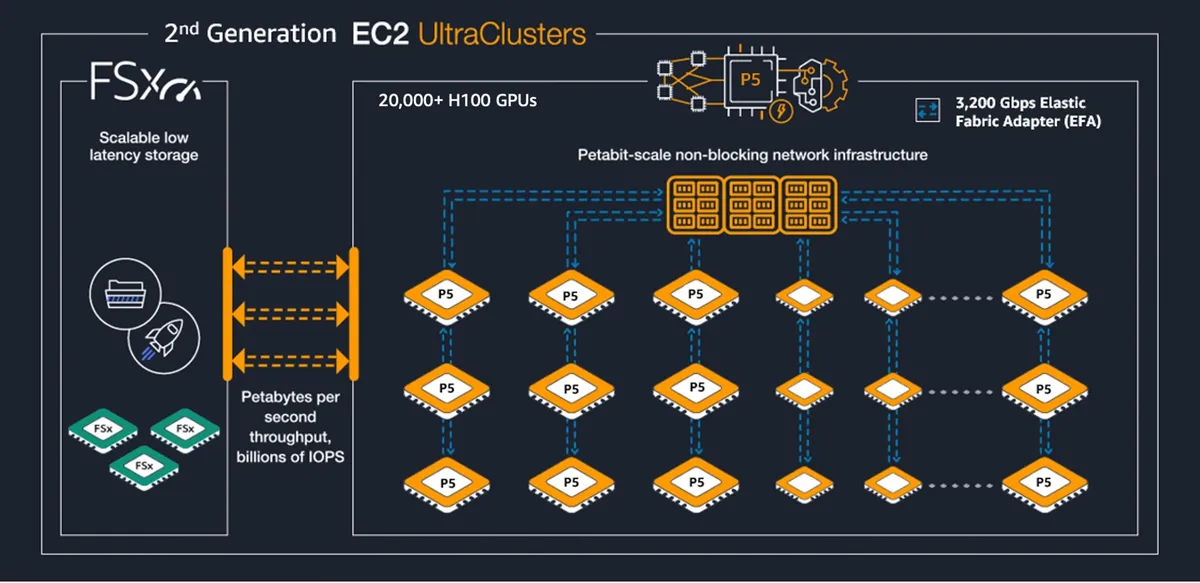
در لایهی زیرساخت، خانوادهی نمونههای Amazon EC2 P6 پردازندههای NVIDIA Blackwell B200 و B300 را معرفی میکنند. برای مقیاسهای حداکثری، سرورهای P6e-GB200 UltraServers دامنه NVLink را به ۷۲ پردازنده گرافیکی و ۱۳.۴ ترابایت حافظه HBM3e گسترش میدهند تا دفعات خروج دادههای حساس از محیط NVLink کاهش یابد. مدیریت شبکه نیز بر عهدهی Elastic Fabric Adapter (EFA) v4 است که بر اساس مستندات فنی، ۱۸ درصد بهبود عملکرد در ارتباطات جمعی نسبت به نسخه v3 دارد.
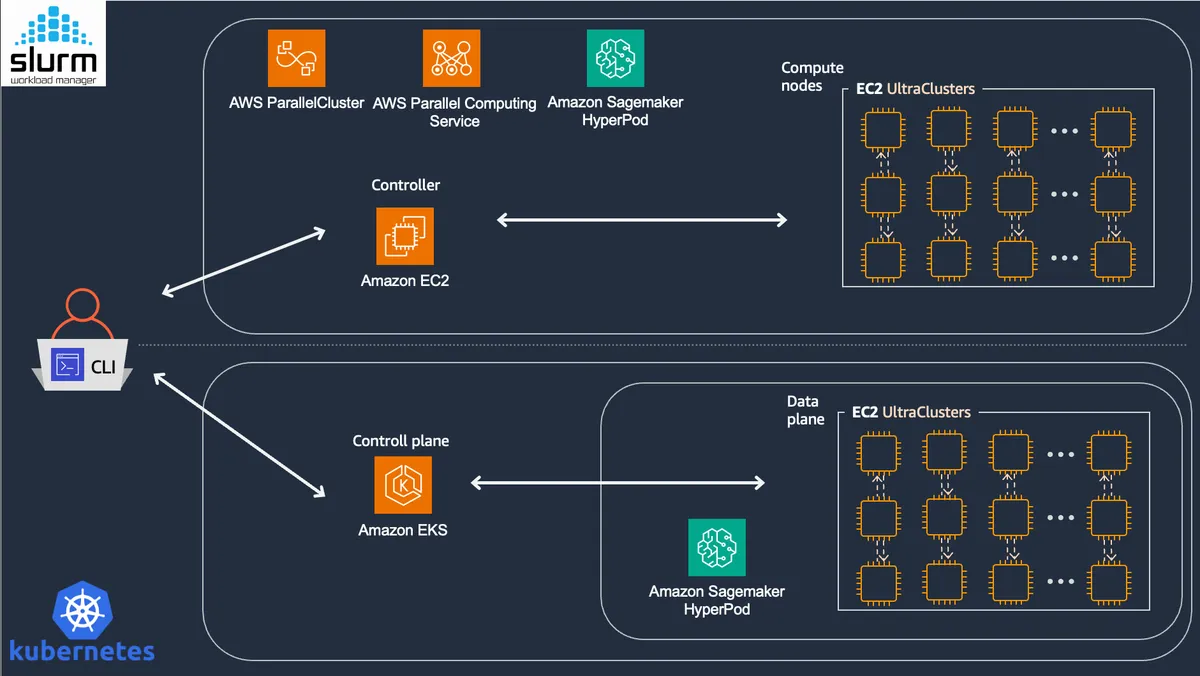
ارکستراسیون منابع از طریق Slurm برای کارهای سبک HPC یا Kubernetes برای استقرار مبتنی بر API مدیریت میشود. در این میان، Amazon SageMaker HyperPod با افزودن نظارت مستمر بر سلامت گرهها و قابلیت «آموزش بدون چکپوینت»، تأخیر بازیابی را کاهش میدهد. در لایهی نرمافزار، پلاگین aws-ofi-nccl وظیفهی نگاشت NCCL انویدیا به شبکهی OS-bypass در EFA را بر عهده دارد و استنتاج (Inference) از طریق vLLM و SGLang با استفاده از تکنیکهای PagedAttention و RadixAttention بهینه شده است.
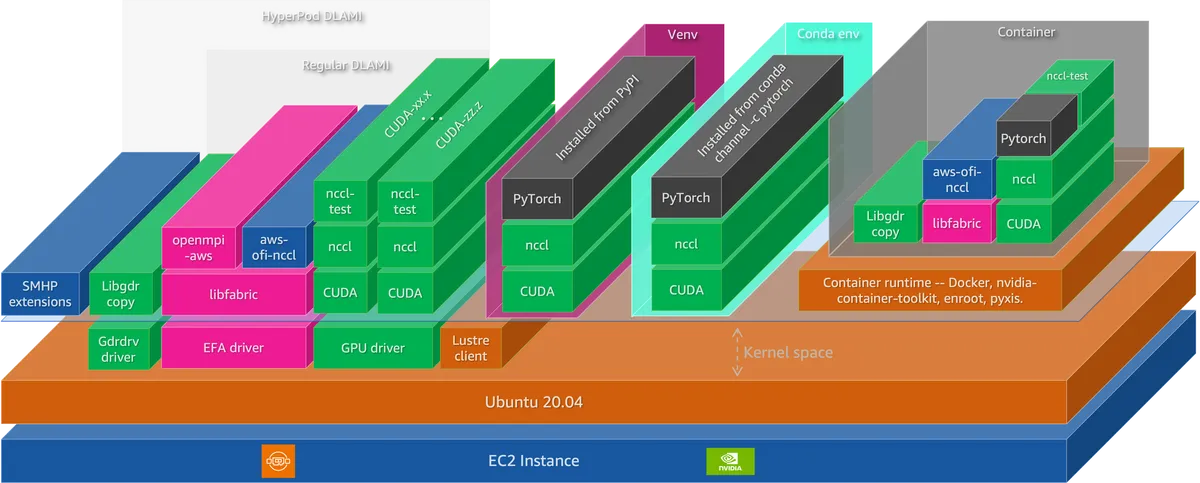
این معماری نشاندهندهی یک تغییر بنیادین است: گلوگاه اصلی مدلهای پیشرو از FLOPS (تعداد عملیات ممیز شناور در ثانیه) به زیربنای ارتباطی منتقل شده است. با گسترش دامنه NVLink و بهینهسازی شبکه EFA، اولویت AWS بر توزیع «همه-به-همه» (all-to-all) توکنهاست که برای مدلهای MoE حیاتی است. برای مهندسان، این بدان معناست که انتخاب میانرابط (Interconnect) و کارایی پلاگین ارتباطی، اکنون به اندازه انتخاب نوع GPU اهمیت دارد.
گام بعدی شما
- بررسی مستندات معماری مشاهدهپذیری AWS برای تشخیص خطاهای XID در GPUها در مقیاس پتابیت.
- تحلیل نرخ خروجی (Throughput) واقعی خوشههای B300 در محیطهای استنتاج مجزا (Disaggregated Inference).
- ارزیابی تأثیر EFAv4 بر کاهش تأخیر در مدلهای با پارامترهای تریلیونی.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو