
احتمالاً خط لوله تولید شما در حال پذیرش دادههای توهمی است، فقط چون در یک قالب JSON بینقص بستهبندی شدهاند. اگر هنوز تصور میکنید خروجی ساختاریافته به معنای صحت دادههاست، باید بدانید که در حال اعتماد به یک سراب فنی هستید.
به نقل از گزارشی که در ۲۹ آوریل ۲۰۲۶ توسط Interfaze منتشر شد، تکیه صنعت بر «نرخ پذیرش JSON» (JSON Pass Rate) به عنوان معیار موفقیت، بهطور بنیادین گمراهکننده است. این مطالعه نشان میدهد که مدلها میتوانند در عین رعایت کامل دستورالعملهای ساختاری، در محتوای دادهها دچار توهم (Hallucination) شوند.
Interfaze برای جداسازی توانایی استخراج داده از استدلال کلی، بنچمارک خروجی ساختاریافته (Structured Output Benchmark - SOB) را معرفی کرد. نتایج این بررسی، یک «شکاف دقت» بحرانی را آشکار میکند: در حالی که تقریباً تمام مدلهای پیشرو نرخ پذیرش JSON بالای ۹۵ درصد دارند، اما «دقت مقداری» (Value Accuracy) — یعنی سهم فیلدهایی که بدون بازبینی انسانی قابل اعتماد هستند — بین ۱۵ تا ۳۰ درصد کاهش مییابد.
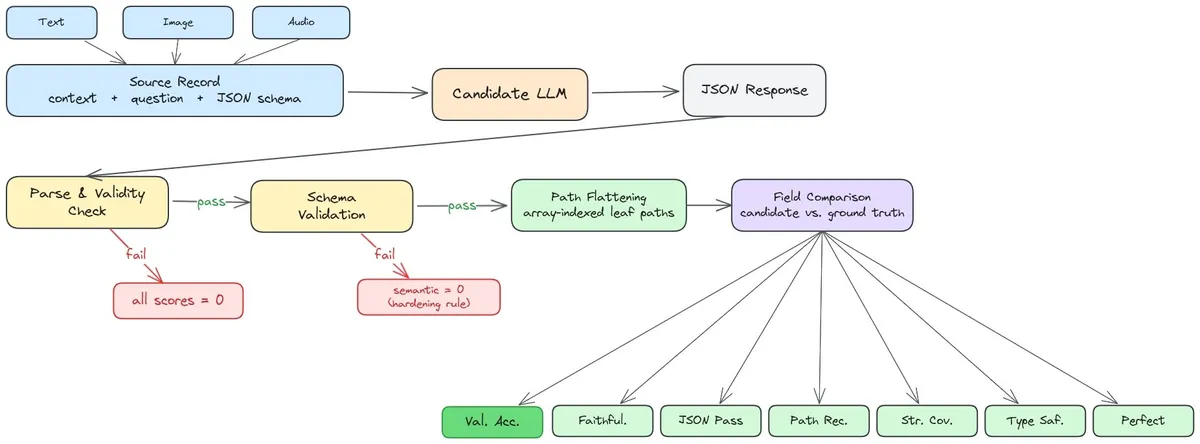
طبق گزارش این مطالعه، چارچوب SOB مدلها را در سه وجه مختلف و با هفت معیار ارزیابی کرده است که یافتههای کلیدی آن عبارتند از:
- واگرایی دقت مقداری: مدل Qwen3.5-35B کمترین شکاف (۱۶.۸ واحد) را داشت، در حالی که Schematron-8B با افت شدید ۲۵.۶ واحدی بین پذیرش ساختاری و دقت محتوایی، ضعیفترین عملکرد را ثبت کرد.
- اندازه، همه چیز نیست: مدلهای کوچکتر مانند Qwen3.5-35B و GLM-4.7 در دقت مقداری از مدلهای غولپیکری مثل GPT-5 و Claude-Sonnet-4.6 پیشی گرفتند.
- فروپاشی وجهی (Modality Collapse): با تغییر منبع داده، عملکرد بهشدت افت میکند. دقت مقداری در متن (۸۳.۰٪ برای GLM-4.7) در تصاویر به ۶۷.۲٪ (Gemma-4-31B) و در صوت به رقم تکاندهنده ۲۳.۷٪ (Gemini-2.5-Flash) سقوط میکند.
این افت کیفیت بهویژه در نسخههای متنی صوت (Transcripts) با میانگین ۷۳۰۰ توکن مشهود است. همانطور که در تحلیل قبلی ما دربارهی مدیریت کانتکست بلند در PyTorch اشاره کردیم، حتی با وجود مدیریت بهینه حافظه، توانایی مبنیسازی (Grounding) مقادیر ساختاریافته در گفتگوهای طولانی و همپوشان، همچنان نقطه شکست اصلی هوش مصنوعی زاینده (Generative AI) است.
برای توسعهدهندگان، پیام روشن است: مدلی که تست اسکیما را پاس میکند، لزوماً حقیقت را نمیگوید. خطرناکترین باگها، «توهمات ساختاریافته» هستند؛ مقادیری که از نظر نوع داده درست و پذیرفتنی به نظر میرسند، اما از نظر واقعیت کاملاً غلطاند.
اما بحران مبنیسازی در دادههای صوتی تنها بخشی از یک معمای بزرگتر است؛ در گزارش بعدی به بررسی تأثیر این موضوع بر عاملهای (Agents) خودکار خواهیم پرداخت.
گام بعدی شما
- استفاده از «نرخ پذیرش JSON» را به عنوان تنها معیار کیفیت متوقف کنید.
- برای دادههای حساس، لایهای از اعتبارسنجی مقداری (Value Validation) را به خط لوله خود اضافه کنید.
- در پروژههای تبدیل صوت به داده، انتظار دقت پایین داشته باشید و نظارت انسانی را افزایش دهید.



گفتگو