اگر امروز برای یک دستیار کدنویسی هزینه میکنید، احتمالاً بزرگترین نگرانی شما قیمت توکنها و سرعت پاسخ است. مایکروسافت با معرفی MAI-Code-1-Flash در ۲ ژوئن ۲۰۲۶، دقیقاً روی همین نقطه دست گذاشته است.
بسیاری از مدلهای فعلی به دنبال رکوردهایی هستند که در محیط واقعی برنامهنویسی کاربردی ندارند. همانطور که در تحلیل قبلی ما دربارهی Scout AI اشاره کردیم، مایکروسافت حالا از بنچمارکهای انتزاعی فاصله گرفته است. این شرکت اکنون آموزش مدل را بر اساس محیطهایی پیش میبرد که برنامهنویسان هر روز با آنها سروکار دارند. در واقع، مدل زبانی بزرگ (LLM) — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — در این نسخه، بیشتر شبیه یک مهندس عملیاتی شده است.
به نقل از گزارش رسمی microsoft.ai، این مدل از سازوکاری به نام کنترل تطبیقی طول پاسخ (adaptive solution length control) استفاده میکند. این قابلیت مثل آشپزی است که برای یک سالاد ساده وقت کمی میگذارد، اما برای یک غذای پیچیده، زمان و دقت بیشتری صرف میکند. در نتیجه، مدل برای درخواستهای ساده کوتاه میماند و بودجهی استدلالی خود را فقط برای مسائل سخت ذخیره میکند.
طبق گزارش بررسیهای انجام شده با ابزارهای GitHub Copilot، نتایج رویارویی این مدل با Claude Haiku 4.5 تکاندهنده است:
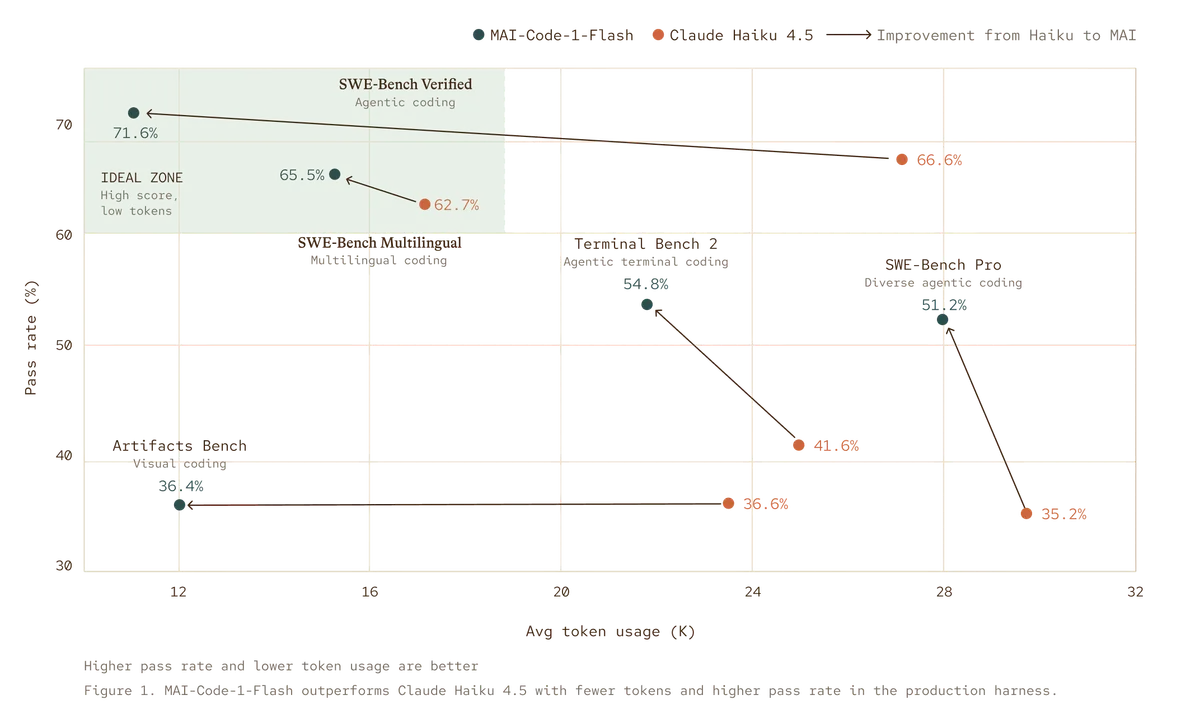
- نرخ موفقیت ۵۱.۲ درصدی در آزمون SWE-Bench Pro (در مقابل ۳۵.۲ درصد برای رقیب).
- عملکرد برتر در آزمونهای Multilingual و Terminal Bench 2.
- حل مسائل سخت با ۶۰٪ توکن کمتر در SWE-Bench Verified.
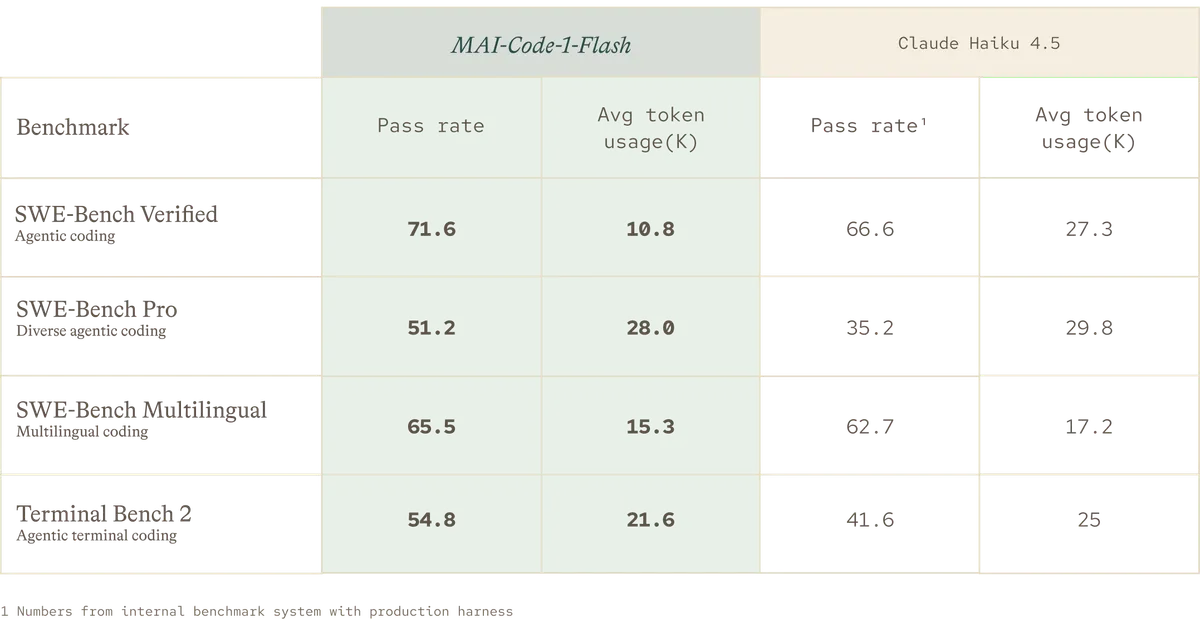
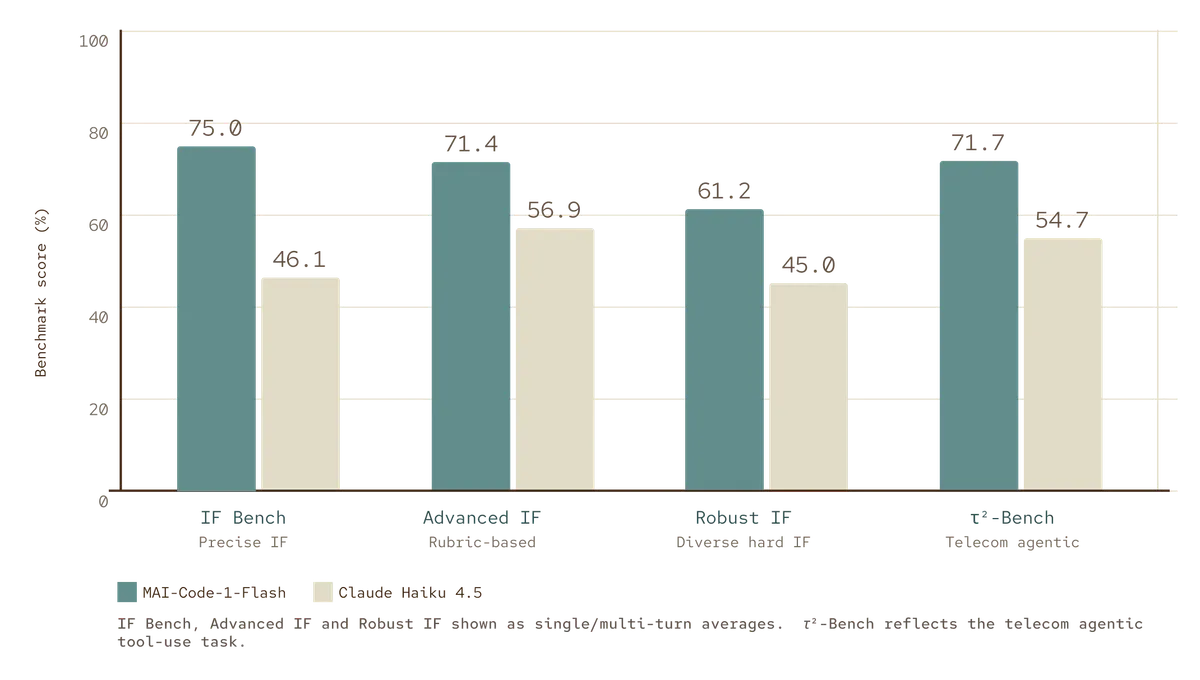
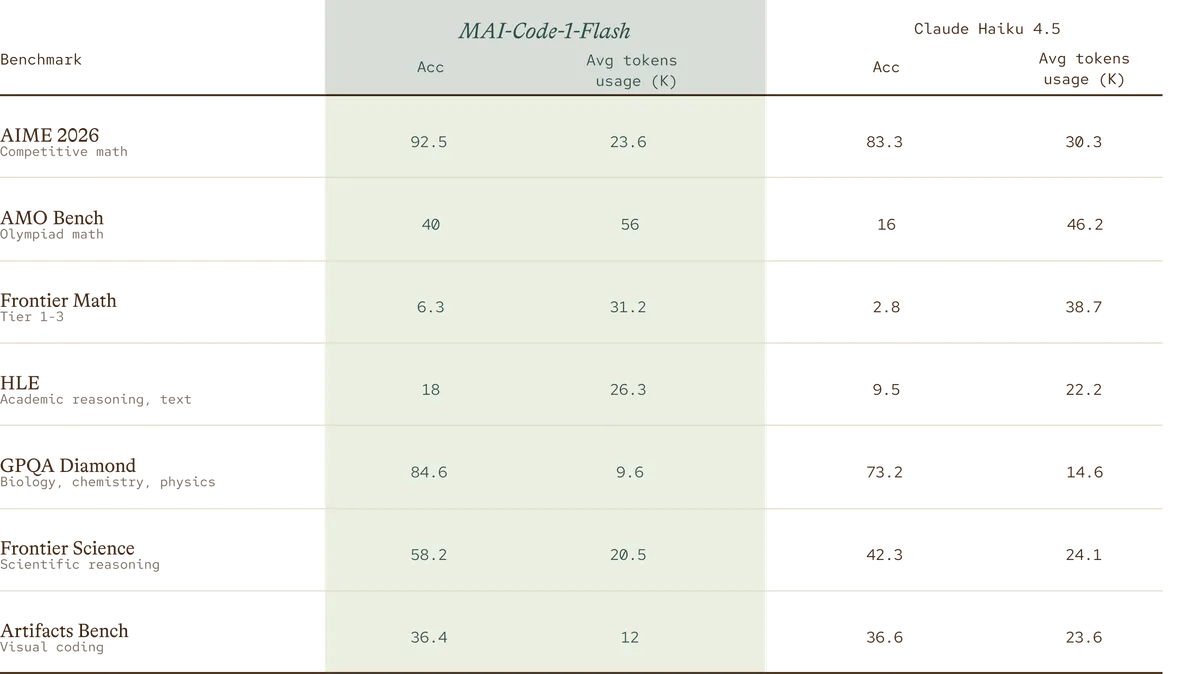
این تغییر نشان میدهد که دقت بالاتر و کارایی دیگر با هم در تضاد نیستند. برای هر کسبوکاری، این یعنی پاسخهای سریعتر برای برنامهنویسان و صورتحساب ماهانه کمتر برای APIها. در واقع، «بازگشت سرمایه توکن» به معیار اصلی موفقیت در گردشهای کاری عاملمحور (agentic) تبدیل شده است.



گام بعدی شما
- بررسی کنید آیا این مدل به موتور پیشفرض بهروزرسانیهای جدید GitHub Copilot تبدیل میشود یا خیر.
- دادههای کامل بنچمارک و مفهوم «ناحیهی ایدهآل» (Ideal Zone) را در وبلاگ مایکروسافت مطالعه کنید.
- استراتژی مصرف توکنهای خود را با توجه به کاهش هزینهی استنتاج (Inference) — لحظهای که مدل واقعاً جواب تولید میکند — بازنگری کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است؛ به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو