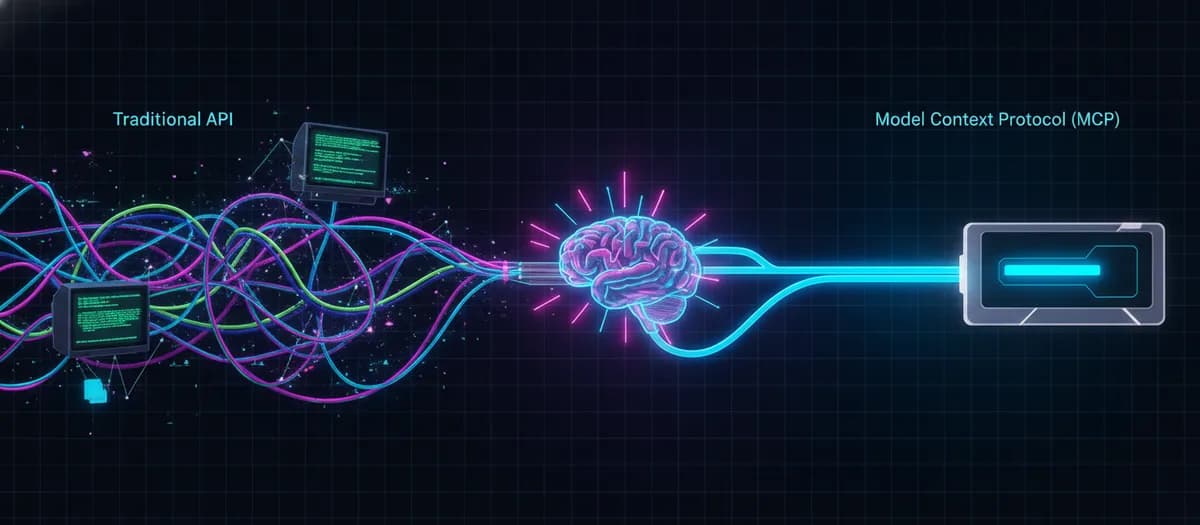
اگر اکنون در حال توسعهٔ عاملهای هوش مصنوعی هستید، احتمالاً با کابوس کدنویسی لایههای واسط برای هر ابزار جدید دستوپنجه نرم میکنید. باید بدانید که دوران نوشتن دستیِ «کدهای چسبناک» برای اتصال مدلها به ابزارها رو به پایان است. توسعه عاملهای خودمختار با استفاده از APIهای سنتی REST، معماری شکنندهای ایجاد میکند که منجر به افزایش هزینهها و کاهش سرعت عملکرد میشود.
طبق اعلام Anthropic، پروتکل زمینهٔ مدل (Model Context Protocol یا MCP) — که اکنون توسط بنیاد لینوکس (Linux Foundation) پشتیبانی میشود — بهعنوان یک آداپتور جهانی برای مدلهای زبانی بزرگ (LLM) معرفی شده است تا دقیقاً همین مشکل را حل کند. این مدل زبانی بزرگ — مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — برای عملکرد صحیح به دسترسی ساختاریافته به دادهها نیاز دارد.
همانطور که در تحلیلهای قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، اتصالات غیربهینه اغلب منجر به نشت داده یا شکست در اجرای توابع میشوند. سالها بود که توسعهدهندگان برنامههای وب را با استفاده از نقاط اتصال (Endpoint) ایستا و قطعی میساختند. اما صنعت اکنون در حال تغییر مسیر به سمت عاملهای احتمالی (Probabilistic Agents) است. این عاملها بهجای مسیرهای سختافزاری و از پیش تعیین شده، به استدلال در لحظه (Runtime Reasoning) نیاز دارند. در واقع، APIهای سنتی با مدلها طوری رفتار میکنند که انگار آنها برنامهنویسان بخش فرانتاند هستند و فقط باید داده را از یک نقطه دریافت کنند؛ این یک اشتباه بنیادین در معماری است و منجر به انباشت بدهی فنی گسترده در قالب لایههای ادغام سفارشی میشود.
کابوس ادغام N در M
در برنامههای سنتی، اگر بخواهید سیستم شما (چه در بخش فرانتاند و چه بکانْد) با GitHub، Slack و Jira صحبت کند، باید سه لایه ادغام مجزا بنویسید. شما باید بهصورت دستی ساختار JSON سفارشی هر کدام را نگاشت کنید، روشهای احراز هویت خاص آنها را مدیریت نمایید و هر مسیر اجرا را سختافزاری کنید. این روش جواب میدهد چون کدهای نوشتهشده توسط انسان، قطعی (Deterministic) هستند.
اما عامل (Agent) بر اساس قصد و استدلال عمل میکند و اینجاست که بحران مقیاسپذیری رخ میدهد:
- اثر ضربدری: اگر ۵ چارچوب مختلف مثل LangChain، LlamaIndex یا تنظیمات سفارشی عاملها داشته باشید و بخواهید آنها را به ۵ ابزار سازمانی مختلف متصل کنید، ناگهان مجبور به نگهداری $5 \times 5 = 25$ کانکتور سفارشی میشوید.
- راهکار MCP: این پروتکل معماری را به یک ساختار $N + M$ تبدیل میکند. در این مدل، هر ابزار فقط یک سرور MCP را پیادهسازی میکند و هر چارچوب عامل هوش مصنوعی تنها یک کلاینت MCP را پیاده میکند. در واقع MCP مانند «پورت USB-C» برای مدلهای زبانی است که همه چیز را استاندارد میکند.
شکست REST و GraphQL در دنیای عاملها
به گزارش منابع فنی، APIهای سنتی در سه مورد حیاتی برای عاملهای هوش مصنوعی شکست میخورند:
اول، اکتشاف پویا در برابر ایستاست. نقاط اتصال REST مانند GET /api/v1/users/{id} سختافزاری هستند و اپلیکیشن نمیتواند از این مسیر منحرف شود. در روش REST، شما مجبورید کل طرح (Schema) API را در پرامپت سیستمی (System Prompt) مدل بگنجانید تا مدل بداند چه چیزهایی وجود دارد. اگر یک نقطه اتصال جدید اضافه کنید یا یک پارامتر را بهروزرسانی کنید، باید پرامپت را تغییر داده و دوباره برنامه را مستقر (Deploy) کنید. اما در MCP، مدل با یک درخواست tools/list لیست قابلیتها، توضیحات به زبان طبیعی و محدودیتهای ساختاری را بهصورت ماشینی دریافت میکند و در لحظه میفهمد چه کاری میتواند انجام دهد.
دوم، «مالیات توکن» و تورم زمینه است. در توسعه فرانتاند، دریافت دادههای بیش از حد (Over-fetching) یک مزاحمت جزئی است. اگر یک پاسخ JSON شامل ۵۰ فیلد باشد در حالی که شما فقط به ۲ مورد نیاز دارید، جاوااسکریپت آن را در چند میکروثانیه مدیریت میکند. اما در دنیای هوش مصنوعی، توکن (Token) — که مثل برشهای یک کیک طولانی است و مدل تکهتکه آن را میخورد — ارز واقعی است. ارسال پاسخهای حجیم و bloated سازمانی REST مستقیماً به یک LLM باعث اتلاف هزینه و افزایش تأخیر میشود. بدتر از آن، این موضوع باعث «پوسیدگی زمینه» (Context Rot) میشود؛ وضعیتی که در آن مدلها تمرکز خود را از دست میدهند یا دادههای حیاتی را که در اعماق اشیاء JSON تو در تو دفن شدهاند، نادیده میگیرند. سرورهای MCP دادهها را بهطور خاص برای پنجرههای زمینه LLM بهینهسازی میکنند.
سوم، نبود وضعیت (Statelessness) است. پروتکل REST ذاتاً بدون وضعیت است و هر درخواست را یک رویداد ایزوله میبیند. اما عاملهای هوش مصنوعی در یک حلقه مداوم از تفکر، اقدام، مشاهده و اصلاح عمل میکنند. MCP از نشستهای وضعیتدار JSON-RPC 2.0 استفاده میکند — که معمولاً از طریق stdio برای ابزارهای محلی یا WebSockets/SSE برای سرویسهای راه دور برقرار میشود. این امر اجازه میدهد یک مذاکره وضعیتدار شکل بگیرد که در آن زمینه (Context) بدون نیاز به ارسال مجدد حجم بالای داده در هر بار درخواست، حفظ شود.
معماری اولیه MCP
این پروتکل تعاملات را با تقسیم آنها به سه Primitive (بنیان) اصلی، تفکیک دقیقی از مسئولیتها ایجاد میکند:
- ابزارها (Tools): اقداماتی قابل اجرا که مدل میتواند انجام دهد. برای مثال: «این commit گیت را اجرا کن» یا «این کوئری SQL را اجرا کن».
- منابع (Resources): منابع دادهای فقطخواندنی که زمینه خام را به مدل ارائه میدهند؛ مانند فایلهای لاگ، مستندات Markdown محلی یا پاسخهای API.
- پرامپتها (Prompts): قالبهای قابل استفاده مجدد که به هدایت جریان استدلال خاص مدل کمک میکنند.
در این لایهبندی، اپلیکیشن میزبان (Host App) مانند Cursor، Claude Desktop یا یک چارچوب سفارشی، شامل کلاینت MCP است. این کلاینت از طریق JSON-RPC 2.0 با سرور MCP ارتباط برقرار میکند و سپس سرور، این درخواستها را به کوئریهای Postgres یا فراخوانیهای API گیتهاب ترجمه میکند.
باید تاکید کرد که MCP جایگزین پایگاهداده یا APIهای بکاند شما نمیشود. سرور MCP شما در لایههای زیرین همچنان APIهای REST داخلی شما را فراخوانی میکند. آنچه MCP جایگزین میکند، آن کدهای چسبناک، سفارشی و شکنندهای است که معمولاً برای نمایش آن سرویسها به یک مدل زبانی استفاده میشد.
پیادهسازیهای واقعی در حال حاضر در حال انجام است؛ برای نمونه، وبسایت devmindset.dev اکنون از یک سرور MCP مبتنی بر پایتون برای مدیریت متادیتای SEO و انتشار پستها استفاده میکند.
این چرخش معماری، اساساً نحوه برخورد ما با «کدهای واسط» بین مدلها و دادهها را تغییر میدهد. ما از تبدیل پاسخهای JSON به رشتههای متنی در آرایههای ابزار و فشار دادن آنها به درون فراخوانیهای API فاصله میگیریم و به سمت یک اکوسیستم ساختاریافته و قابل اکتشاف حرکت میکنیم.
برای توسعهدهندگان، این بدان معناست که عصر بستهبندی دستی APIها در حال پایان است. صنعت بهسرعت حول MCP به عنوان استانداردی برای IDEها و چارچوبهای ارکستراسیون جمع میشود، زیرا این پروتکل «پنجره زمینه» مدل را بر مستندات API قابل خواندن برای انسان ترجیح میدهد.
اگر همچنان ویژگیهای عاملمحور (Agentic) خود را با استفاده از Wrapperهای سفارشی و فراخوانی دستی توابع میسازید، در حال انباشت بدهی فنی هستید که پرداخت آن در آینده بسیار گران خواهد بود. انتقال به MCP کمتر به معنای استفاده از یک ابزار جدید و بیشتر به معنای پذیرش پشتهای (Stack) است که برای آیندهی احتمالی و عاملمحور ساخته شده است.
منتظر پذیرش گستردهتر MCP توسط IDEهای بزرگ باشید و بررسی کنید که آیا چارچوب ارکستراسیون فعلی شما از استاندارد JSON-RPC 2.0 پشتیبانی میکند یا خیر. نظر شما چیست؟ آیا ابزارهای داخلی خود را به MCP منتقل کردهاید یا هنوز از فراخوانی دستی توابع استفاده میکنید؟ در کامنتهای پایین با ما در میان بگذارید!
گام بعدی شما
- بررسی پشتیبانی چارچوبهای ارکستراسیون فعلی خود از استاندارد JSON-RPC 2.0
- جایگزینی توابع فراخوانی (Function Calling) دستی با سرورهای MCP برای کاهش مصرف توکن
- مطالعه مستندات بنیاد لینوکس برای پیادهسازی اولین سرور MCP محلی
اما تأثیر این استاندارد بر سرعت استنتاج مدلها در محیطهای ابری پیچیدهتر است؛ به تحلیل ما دربارهی بهینهسازیهای لایه استنتاج مراجعه کنید.



گفتگو