
تیمهای مهندسی اکنون باید بین راحتی APIهای مدیریتشده و کنترل زیرساختی شخصی یکی را انتخاب کنند؛ اما این انتخاب دیگر یک نقطه تصمیمگیرنده نیست. در تاریخ ۲۳ ژوئن ۲۰۲۶، شرکت Modal سرویس Auto Endpoints را برای حذف این تضاد معرفی کرد. هدف این است که تیمها مالکیت کامل پشته استنتاج (Inference Stack) مدلهای زبانی بزرگ (LLM) خود را به دست آورند، بدون اینکه با بارهای عملیاتی سنتی و دشوار دستوپنجه نرم کنند. تیمهای پیشرو از جمله Cognition، Decagon، Fathom و DoorDash در حال حاضر از Modal استفاده میکنند تا مالکیت استنتاج خود را بدون به خطر انداختن سرعت توسعه یا نسبت هزینه-به-عملکرد به دست آورند.
بسیاری از توسعهدهندگان در حال حاضر به ارائهدهندگان مدلهای اختصاصی وابسته هستند که پشته سرویسدهی آنها مانند یک جعبه سیاه است. طبق استدلال Modal، اگر یک ارائهدهنده بهطور بیصدا کیفیت یک مدل را کاهش دهد یا دسترسی به آن را محدود کند، توسعهدهنده کنترل سرنوشت محصولش را از دست میدهد. در حالی که استفاده از مدلهای متنباز از طریق یک ارائهدهنده استنتاج، مقداری کنترل ایجاد میکند، اما Modal باور دارد مالکیت واقعی عمیقتر از یک API ساده است. برای اینکه یک تیم واقعاً مالک استنتاج باشد، باید کدی را که آن را اجرا میکند، بشناسد، درک کند و بهینه سازد.
تنها جایگزین تا پیش از این، راهاندازی یک سرویس استنتاج شخصی بود. این مسیر کنترل کامل را میداد اما بار عملیاتی عظیمی را تحمیل میکرد: از تنظیم دقیق موتور (Engine Tuning) و بنچمارکگذاری نقاط انتهایی (Endpoint Benchmarking) گرفته تا استقرار کانتینرها، مقیاسدهی خودکار نسخههای تکراری (Replica Autoscaling)، روتینگ و مدیریت متریکهای استنتاج. این چالشها بهویژه هنگام کار با مدلهای حجیمتر مشهود است، جایی که بهینهسازیهای معماری ترکیبی CPU-GPU میتواند نیاز به کوانتیزه کردن مدلهای MoE را از بین ببرد و بهرهوری سختافزاری را افزایش دهد.
همانطور که در تحلیلهای قبلی ما درباره امنیت مدلهای بازمتن اشاره کردیم، شفافیت در لایه زیرساخت برای سازمانها حیاتی است. Modal با ارائه یک سرویس سازگار با OpenAI که توسط یک اپلیکیشن قابلکنترل و قابلمشاهده پشتیبانی میشود، این شکاف را پر کرده است. برخلاف ارائهدهندگان مدیریتشده، Modal انتخاب GPU، منطقهبندی (Regionalization) یا پرچمهای موتور (Engine Flags) را پنهان نمیکند. آنها حتی گاهی اوقات وصلههای (Patches) خاص موتور را به اشتراک میگذارند. این شفافیت به توسعهدهندگان اجازه میدهد با یک خط مبنای با عملکرد بالا شروع کنند و با تکامل بار کاری خود، به سمت بهینهسازیهای سفارشی و ویژه حرکت کنند.
هسته فنی Auto Endpoints
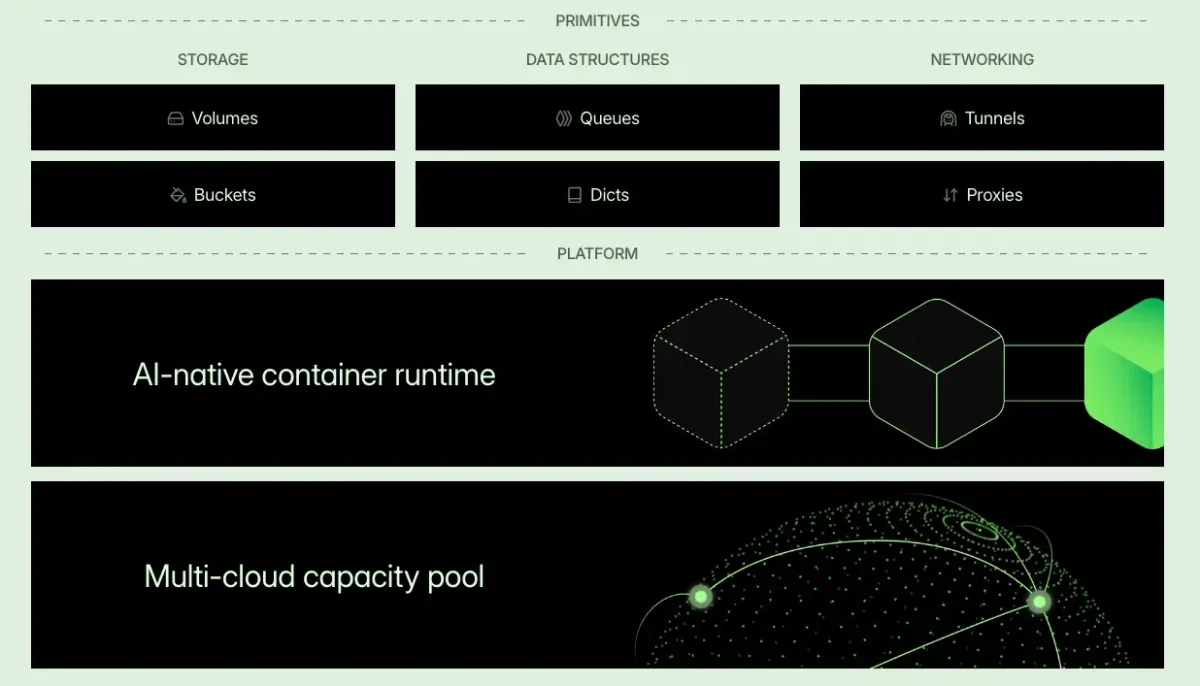
این سیستم بر بستر یک پلتفرم زیرساختی تخصصی بنا شده است که برای بارهای کاری نامنظم و نوسانی هوش مصنوعی طراحی شده است. این همان زیربنایی است که کاربران برای تاختن پروتئینها، هدایت رباتها و تولید موسیقی از آن استفاده میکنند. ارکان فنی اصلی این سیستم عبارتاند از:
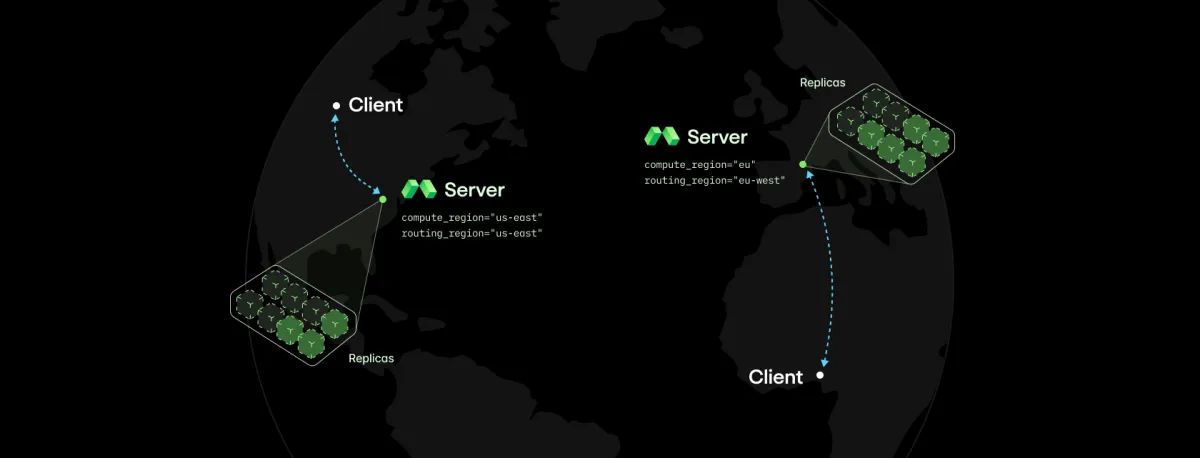
- Modal Servers: اجزای روتینگ جدید با تأخیر بسیار کم که از حالت بتا خارج شدهاند. این سرورها صفهای انتظار (Queueing) را حذف کرده و بهطور پیشفرض منطقهبندی شدهاند. این امر اجازه میدهد درخواستهای HTTP با تنها ۵ میلیثانیه اورهد (Overhead) روی Modal پاسخ داده شوند، بدون اینکه پایایی سیستم به خطر بیفتد.
- معماری DFlash: ادغام معماری درفتر block-diffusion از Z Lab. مودال از این معماری در هر مدل سازگار استفاده میکند. آنها با همکاری نزدیک با Z Lab و تیم SGLang تلاش کردهاند تا DFlash را در سیستمهای سرویسدهی واقعی سریع و قابلاعتماد کنند و برای تضمین عملکرد بهینه، مدلهای درفتر DFlash خود را آموزش داده و منتشر کردهاند.
- مشارکت در متنباز: این پلتفرم با اعمال وصله و ارسال بهبودها به موتورهایی مثل SGLang و کرنلهایی مانند FlashAttention-4 تکامل یافته است. در همین راستا، بهرهگیری از مدلهای زبانی باز برای کاهش ارزیابیهای تنظیم MIMO نشان میدهد که چگونه ساختارهای پیشین در مدلهای بازمتن میتوانند فرآیندهای بهینهسازی را تسریع کنند.
- مقیاسدهی الاستیک: کاربران تنها برای آنچه مصرف میکنند، در همان لحظه هزینه میپردازند. این یعنی دیگر نیازی نیست ماهها ظرفیت GPUهای گرانقیمت را برای بارهای کاری غیرقابلپیشبینی رزرو کنند. این سیستم مقیاسدهی با عملکرد بالا از یک محیط اجرای کانتینری (Container Runtime) سفارشی بهره میبرد.
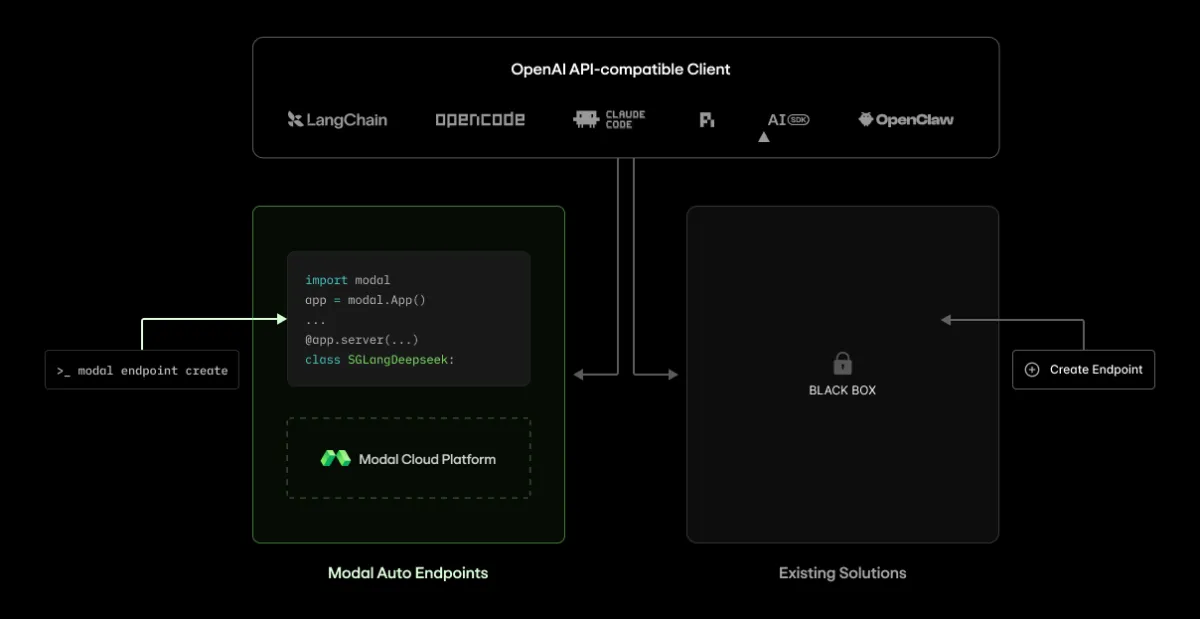
به نقل از مستندات Modal، استقرار یک مدل پیشرو مانند GLM 5.2 اکنون تنها با یک دستور CLI یا از طریق «کلیکاوپس» (Clickops) ممکن است. کاربران دیگر مجبور نیستند برای دسترسی به سختافزارهای سطح بالا، وارد تماسهای فروش یا جلسات زوم شوند. در عوض، آنها از یک محیط اجرای کانتینری سفارشی استفاده میکنند که فارغ از محل قرارگیری کاربران در سطح جهان، بهطور خودکار برای پاسخ به تقاضا مقیاس مییابد.
عملکرد بالا بدون فشار عملیاتی
از نظر Modal، موتورهای استنتاج مشابه سیستمهای مدیریت پایگاهدادهای چون PostgreSQL هستند: نرمافزارهایی حیاتی، پیچیده و حساس که باید تا مرز نهایی سختافزار تنظیم شوند تا بهترین عملکرد را داشته باشند. این فرآیند معمولاً نیازمند یک «سگدوئی» یا فشار زیاد برای تنظیم متغیرهای بیشمار و پیچیده است.
سرویس Auto Endpoints این دشواری را با ارائه نسخههای استقرار آماده (Recipes) برطرف میکند که از تجربه کار با متقاضیترین محصولات هوش مصنوعی جهان استخراج شدهاند. این دستورالعملها در رقابت مستقیم با ارائهدهندگان استنتاج اختصاصی توسعه یافتهاند و با شرطبندی روی متنباز و تمرکز کامل بر رمزگشایی گمانهزنانه (Speculative Decoding) پیروز شدهاند. این رویکرد نیاز توسعهدهندگان به آزمایشهای دستی و خستهکننده با پرچمهای پیچیده موتور را تا زمانی که آماده بهینهسازیهای خاص باشند، از بین میبرد. نمونههایی از پیچیدگیهای فنی که Auto Endpoints مدیریت میکند عبارتاند از:
- دقت و زمانبندی: مدیریت خودکار پرچمهایی مانند
--mamba-scheduler-strategyو--flashinfer-mxfp4-moe-precision. - بنچمارکگذاری: نمایش نتایج در حین راهاندازی، که به کاربران اجازه میدهد توازن (Trade-off) بین تأخیر و توان عملیاتی (Throughput) را بررسی کنند و ببینند سرویسهای با چندین نسخه تکراری (Multi-replica) تحت فشار چگونه رفتار میکنند.
- تخصصگرایی بار کاری: تشخیص این نکته که یک نقطه انتهایی (Endpoint) برای طبقهبندی با تأخیر کم، به تنظیماتی متفاوت از یک حلقه عاملمحور (Agentic Loop) چندمرحلهای نیاز دارد. مودال کاربران را با پیکربندیای شروع میکند که تمیز، قابلبازرسی و بنچمارکشده است، پیش از آنکه تحلیل اثرات (Traces) را آغاز کند.
مشاهدهپذیری در سطح موتور
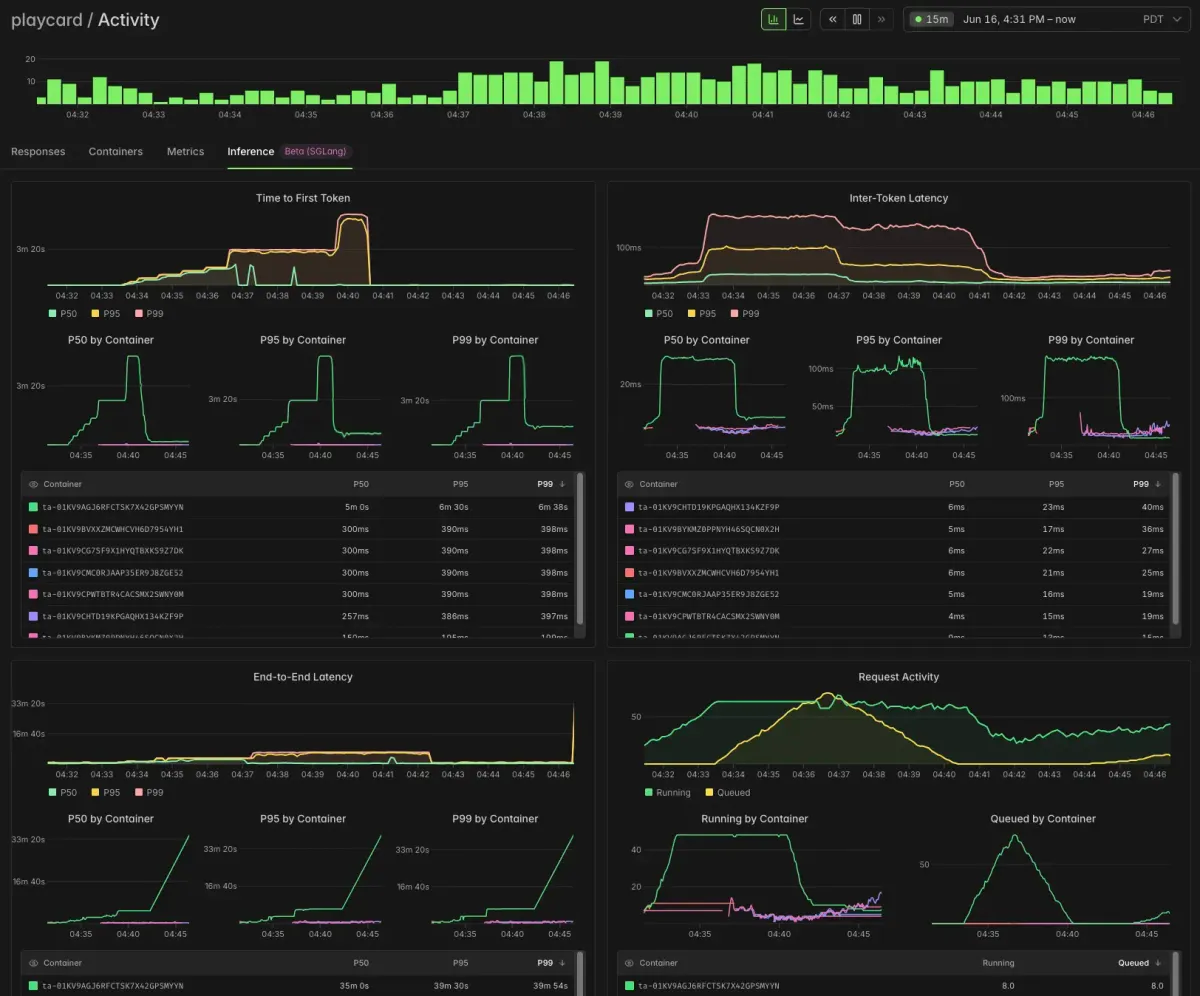
مالکیت مستلزم مشاهدهپذیری است. برای ریشهیابی مشکلات برنامه، Modal متریکهای دقیقی را در داشبورد و از طریق خروجی OTEL ارائه میدهد. آنها این دادهها را به دو گروه متمایز تقسیم میکنند:
۱. متریکهای سرور: شاخصهای سلامت فیزیکی که عمیقتر از ارائهدهندگان استاندارد هستند و مواردی مثل دمای GPU، توان مصرفی و میزان بهرهبرداری واقعی را شامل میشوند.
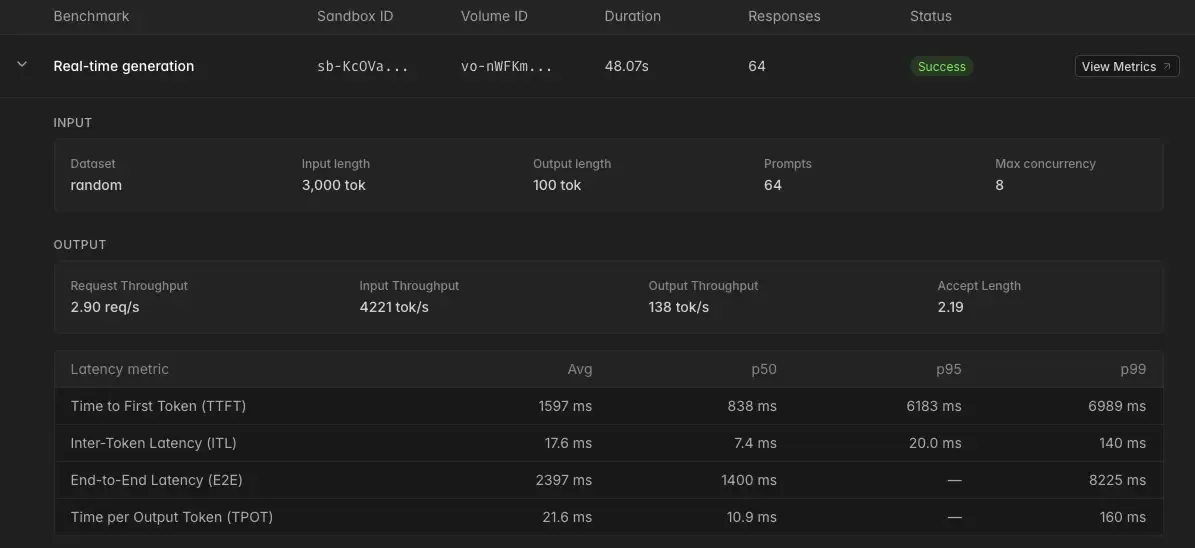
۲. متریکهای استنتاج: دادههای حیاتی عملکردی که توسط موتورهای استنتاج صادر میشوند، مانند زمان تا نخستین توکن (TTFT)، تأخیر بین توکنها (ITL)، صفهای انتظار و طول پذیرش در رمزگشایی گمانهزنانه.
این سطح از جزئیات به تیمها اجازه میدهد دقیقاً تشخیص دهند چرا جهشهای تأخیر (Latency Spikes) رخ میدهند. برای مثال، در زمان افزایش شدید ترافیک، داشبورد نشان میدهد که یک کانتینر تنها در حال مدیریت بار پایه است و TTFT آن بهطور مداوم افزایش مییابد (به دلیل صف پیشپُرکردن یا Prefills)، و به دنبال آن ITLها بالا میروند (به دلیل صف رمزگشایی یا Decodes). این زنجیره منجر به افزایش تأخیر کلی از ابتدا تا انتها (End-to-End) میشود.
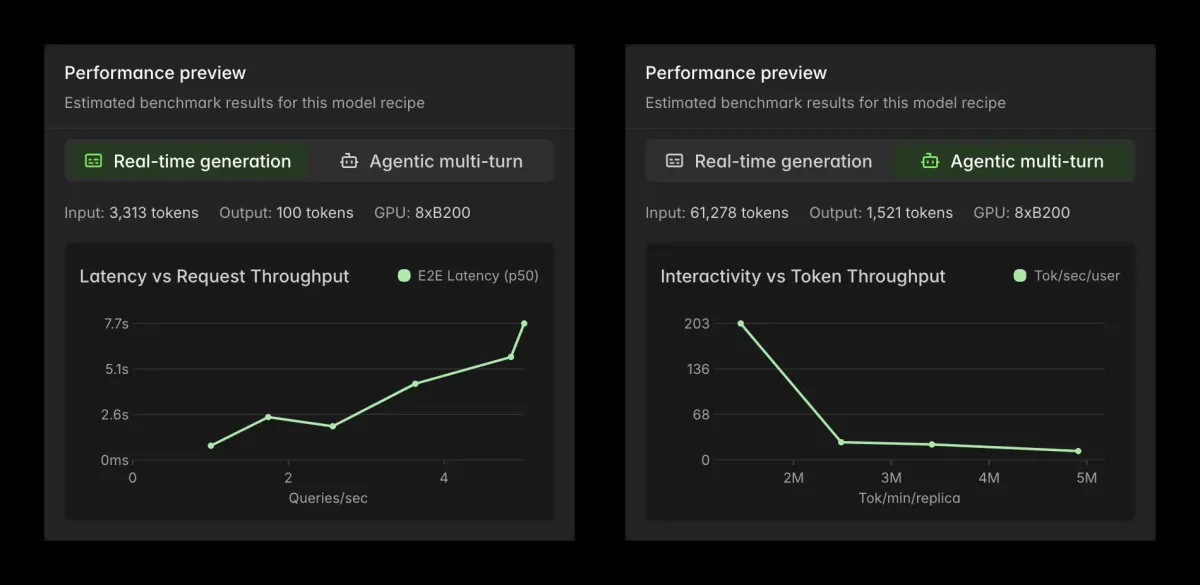
سیستم سپس بهطور خودکار نسخههای اضافی (Replicas) — برای مثال دو کانتینر جدید — را فعال میکند تا صف کاهش یابد و تأخیرها به سطوح قابلقبول بازگردند. این فرآیند از طریق اتوماسیون زیرساختی رخ میدهد، نه از طریق یک هشدار دستی در PagerDuty.
مسیر رسیدن به استنتاج «کاملاً خودکار»
هدف Modal حرکت به سمت یک رابط تعریفکننده (Declarative Interface) بر اساس بارهای کاری و توافقنامههای سطح خدمات (SLO) است. این رویکرد حاصل سالها بهینهسازی استنتاج برای مشتریان سطح اول است. مودال دیگر کدهای استقرار را صرفاً بهصورت دستی نمینویسد؛ آنها اکنون از یک سیستم عاملمحور داخلی (Internal Agentic System) به سبک autoresearch استفاده میکنند که موتورها را پیکربندی کرده و برای رسیدن به بالاترین عملکرد، روی منحنی بهینهسازی حرکت میکند (Hill-climbing)، در حالی که صحت و کیفیت خروجی را حفظ مینماید.
این تکامل به آیندهای اشاره دارد که در آن اتوماسیون کامل حاکم است و مهندسی دیگر یک گلوگاه نیست. نقشه راه Modal شامل موارد زیر است:
- Autoinference: خودکارسازی کامل پیکربندی، اعمال وصلهها (Patching) و بنچمارکگذاری سرورهای استنتاج.
- Autospec: ایجاد و بهروزرسانی مدلهای گمانهزن (Speculator) بر اساس دادههای سنتتیک و دادههای واقعی تولید. مدلهای گمانهزن فعلی در چندین بنچمارک، بیش از ۴ برابر سریعتر از نسخههای پایه و بیش از ۱.۵ برابر سریعتر از سایر گمانهزنهای عمومی هستند، اما آموزش آنها روی دادههای تولیدی خاص، عملکرد را باز هم بهبود میبخشد.
- Autodistill: تقطیر خودکار (Automated Distillation) قابلیتها از مدلهای مستقر شده به مدلهای کوچکتر و سریعتر.
- Autoresearch: توسعه خودکار ویژگیهای عملکردی جدید، موتورهای استنتاج و مدلهای تازه.
در حال حاضر، مهندسان انسانی همچنان بر این سیستم عاملمحور نظارت میکنند تا اطمینان حاصل شود که تنها کدهای سطح تولید (Production-grade) قدرتبخش نقاط انتهایی هستند. با این حال، هدف نهایی حذف گلوگاه نظارت انسانی بر فرآیندهای آموزش است. مودال در حال توسعه سیستمهای شناسایی خودکار فرصتهای بازآموزی و خطلولههای (Pipelines) آموزش خودکار است تا از این فرصتها بهره ببرد.
این چرخش، فرض بنیادی استقرار مدلهای زبانی را تغییر میدهد. استنتاج دیگر انتخابی بین یک API «جعبه سیاه» و یک سرور «کارِ دستی» نیست؛ بلکه به یک دارایی برنامهریزیپذیر و مشاهدهپذیر تبدیل شده است که خود را بر اساس ترافیک زنده بهینه میکند.
گام بعدی شما
- اگر از APIهای بسته خسته شدهاید، مدلهای GLM یا Llama را روی Modal تست کنید تا تفاوت مشاهدهپذیری لایه ۲ (L2) را ببینید.
- متریکهای TTFT و ITL را در داشبورد خود بررسی کنید تا گلوگاههای واقعی استنتاج را شناسایی کنید.
- استراتژیهای رمزگشایی گمانهزنانه را برای کاهش هزینههای GPU در ترافیک بالا بررسی نمایید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما درباره تراشههای Blackwell مراجعه کنید.



گفتگو