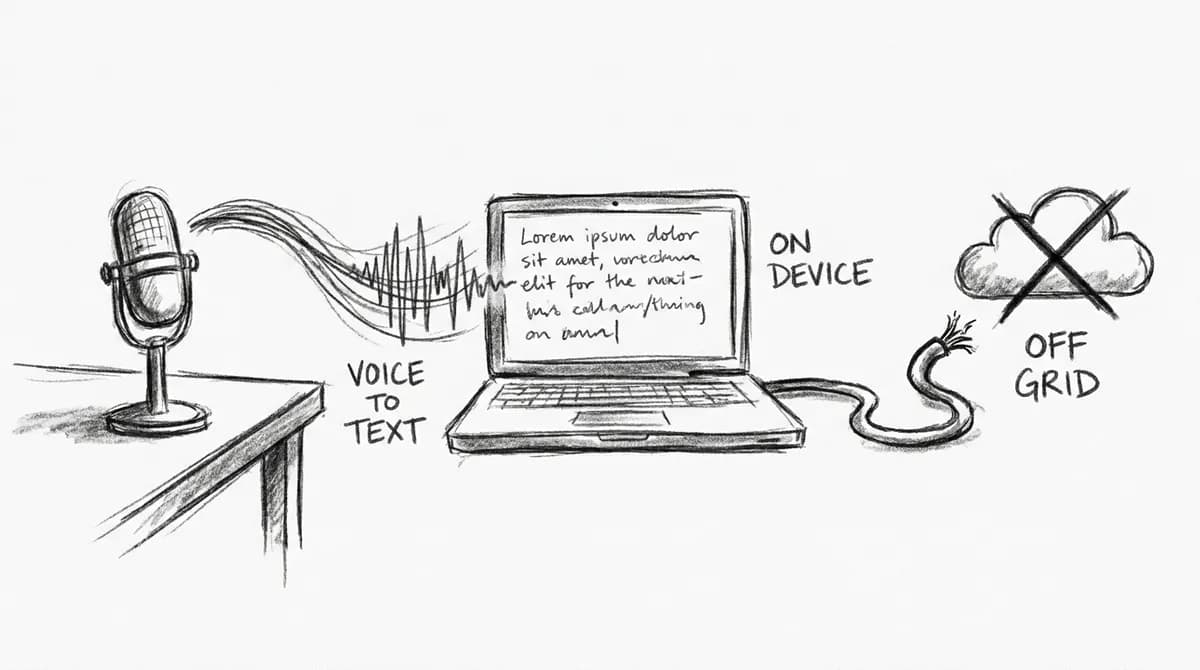
تصور کنید تمام یادداشتهای صوتی شما، بدون اینکه حتی یک بایت داده از رایانه خارج شود، با دقت میلیمتری به متن تبدیل شوند. اگر از ابزارهای ابری برای تایپ صوتی استفاده میکنید، احتمالاً میدانید که در واقع دارید حریم خصوصی خود را با بهرهوری معاوضه میکنید.
Off Grid AI Desktop که صراحتاً به عنوان یک ابزار متنباز تحت مجوز AGPL-3.0 منتشر شده است، از مدل Whisper برای تبدیل صدا به متن بهصورت محلی (On-device) بهره میبرد. OpenAI مدل Whisper را بر روی ۶۸۰,۰۰۰ ساعت دادههای صوتی آموزش داده است. این مجموعه آموزشی عظیم به نسخههای کوچکتر مدل اجازه میدهد تا روی CPU یک لپتاپ بهصورت آنی (Real-time) اجرا شوند. برای بسیاری از کاربران، این قدرت سختافزاری در حالی بلااستفاده میماند که آنها هر ماه هزینهی اشتراک پرداخت میکنند تا یادداشتهای صوتی خود را برای تبدیل به متن به سرورهای خارجی ارسال کنند. Off Grid AI Desktop این نیاز را کاملاً از بین میبرد؛ این ابزار رایگان است، متنباز است و بهطور کامل آفلاین عمل میکند. در اینجا هیچ حسابی برای ایجاد وجود ندارد و نیازی به مدیریت کلید API (API Key) نیست.
این تغییر رویکرد به سمت پردازش محلی، یک نقطه اصطکاک حیاتی در بهرهوری را حل میکند: شکاف سرعت میان صحبت کردن (حدود ۱۵۰ کلمه در دقیقه) و تایپ کردن (شاید ۴۰ کلمه در دقیقه). در حالی که اکثر ابزارهای دیکته این شکاف را از طریق فضای ابری پر میکنند، اما این کار را با ضبط صداهای خام انجام میدهند که ممکن است شامل رمزهای عبوری باشد که بهطور تصادفی بلند خوانده شدهاند، یا نام مشتریان و ایدههایی که هنوز کامل نشدهاند. همانطور که در پوشش پیشین ما از MiniCPM-Desk-Pet و موج رایانههای شخصیِ هوشمند دیدیم، این ابزار لایهی تبدیل گفتار به متن را از ابر به لبه (Edge) منتقل میکند. با استفاده از Whisper محلی، صدا در همان ماشینی که پشت آن نشستهاید ضبط، تبدیل و به متن تبدیل میشود. این رویکرد مشابه استراتژیهایی است که در بررسی OpenWhispr و برتری پردازش محلی در کدنویسی مشاهده کردیم، جایی که سرعت و امنیت دادهها اولویت اصلی بود.
بر اساس راهنمای فنی منتشر شده در ۲۵ ژوئن ۲۰۲۶ در وبسایت dev.to، این اپلیکیشن از whisper.cpp استفاده میکند؛ یک پورت به زبان C++ که اجازه میدهد مدل بدون نیاز به پایتون یا یک سرور مقیم (Resident Server) اجرا شود. این معماری امکان چندین گردش کار خاص را فراهم میکند:
قابلیتهای کلیدی
- ترکیبکنندهی داخلی (Integrated Composer): کاربران روی میکروفون کلیک کرده و صحبت میکنند و کلمات بهصورت متن در باکس چت قرار میگیرند تا پیش از ارسال، ویرایش شوند.
- پرامپتنویسی بدون دست (Hands-Free Prompting): پرامپتهای طولانی و پیچیده برای مدلهای زبانی محلی (LLM) را میتوان در حالی که کاربر دور از کیبورد است دیکته کرد؛ مثلاً هنگام قدم زدن در اتاق یا شستن ظرفها. این قابلیت زمانی که در کنار استقرار محلی مدلهایی مانند Qwen3-Coder با Ollama استفاده شود، یک محیط کاملاً خصوصی و بدون هزینه توکن برای برنامهنویسی ایجاد میکند.
- یادداشتهای اولویتدار بر حریم خصوصی: یادداشتهای پزشکی، حقوقی یا شخصی محلی میمانند. تبدیل متن روی دستگاه تضمین میکند که صداهای حساس هرگز به دادههای آموزشی شرکتهای دیگر یا یک ورودی در لاگهای شرکتی تبدیل نشوند.
- حلقهی بسته هوش مصنوعی (Local AI Loop): کاربران میتوانند یک سوال خام را دیکته کنند، اجازه دهند یک LLM محلی روی دستگاه پاسخ دهد و سپس سوالات تکمیلی را باز هم دیکته کنند. تمام این حلقهی ارتباطی روی سختافزار کاربر باقی میماند.
نیازمندیهای سختافزاری و فنی
مدلهای Whisper بهقدری سبک هستند که اکثر آنها روی سختافزارهای موجود بهخوبی اجرا میشوند. خودِ مدلهای تبدیل متن تنها چند صد مگابایت حجم دارند که بسیار کمتر از یک مدل کامل چت LLM است. برای حفظ سرعت آنی، اپلیکیشن از شتابدهندههای سختافزاری استفاده میکند.
در سیستمهای macOS، برنامه از Metal برای بهرهگیری از حافظهی یکپارچهی تراشههای اپل سیلیکون استفاده میکند؛ این بدان معناست که CPU و GPU از یک استخر حافظه مشترک استفاده میکنند و نیازی به کپی کردن دادهها به عقب و جلو نیست. این قابلیت به لپتاپهای سری M بدون فن اجازه میدهد تا تبدیل متن را بهطور بیصدا مدیریت کنند. کاربران ویندوز شتابدهی را از طریق CUDA برای کارتهای گرافیک NVIDIA یا Vulkan برای طیف گستردهتری از GPUها دریافت میکنند. اگر هیچ GPU سازگاری پیدا نشود، مسیر CPU همچنان کار میکند، هرچند برای مدلهای بزرگتر کندتر است.
حداقل نیازمندیها عبارتند از:
- macOS: تراشه اپل سیلیکون (M1) یا اینتلهای جدید، ۸ گیگابایت رم، نسخه macOS 13 به بالا.
- Windows: هر پردازندهی ۶۴ بیتی، ۸ گیگابایت رم، ویندوز ۱۰ به بالا.
- فضای دیسک: حدود ۲ گیگابایت برای اپلیکیشن و یک مدل کوچک.
سختافزار پیشنهادی برای عملکرد بهتر شامل مکهای M2 یا جدیدتر با ۱۶ گیگابایت حافظه یکپارچه، یا ماشینهای ویندوزی با GPU انویدیا (CUDA) و ۱۶ گیگابایت رم است. همچنین یک میکروفون USB یا داخلی با سیگنال پاک مورد نیاز است.
موازنه در انتخاب مدل
کاربران مدل را بر اساس توازن بین سرعت و دقت انتخاب میکنند. راهنما اشاره میکند که مدلها «کوانتایز» (Quantized) شدهاند؛ یعنی در یک فرمت عددی فشرده ذخیره شدهاند تا در رمهای استاندارد مصرفکننده جای بگیرند و سریع بارگذاری شوند. این کوانتایزاسیون دلیل اصلی اجرای نرمافزار روی سختافزارهای معمولی است:
- مدل Tiny / Base (حدود ۷۵ تا ۱۵۰ مگابایت): بسیار سریع؛ بهترین گزینه برای یادداشتهای سریع روی ماشینهای قدیمی، هرچند در تشخیص لهجهها و اسامی خاص انعطاف کمتری دارد.
- مدل Small (حدود ۵۰۰ مگابایت): خط پایه پیشنهادی برای دیکته روزمره و تعادلی مناسب برای اکثر کاربران.
- مدل Medium (حدود ۱.۵ گیگابایت): کندتر اما بهطور قابلتوجهی دقیقتر برای اصطلاحات تخصصی و لهجههای متنوع.
به کاربران توصیه میشود با مدل 'small' شروع کنند و تنها در صورتی که سیستم نامهای خاص یا اصطلاحات حرفهای را اشتباه میشنود، به مدل بالاتر بروند.
نکاتی برای بهینهسازی
دقت تبدیل بیشتر به عادتهای استفاده وابسته است تا اندازه مدل. راهنمای مذکور چند عادت خاص را برای افزایش دقت پیشنهاد میکند:
- کیفیت سیگنال: به میکروفون نزدیک شوید؛ در حالی که Whisper در برابر نویز مقاوم است، اما یک سیگنال پاک همیشه برنده است.
- ساختار جملات: بهجای تکههای پراکنده، در قالب جملات کامل صحبت کنید؛ زیرا مدل از بافت کلمات اطراف برای تشخیص درست آنچه شنیده است استفاده میکند.
- سرعت بیان (Pacing): برای دیکتههای طولانی، بین افکار خود مکثهای طبیعی داشته باشید. این مکثها مرزهای پاکی را برای رمزگشا (Decoder) فراهم میکنند و خطاهای ادغام جملات را کاهش میدهند.
- تطبیق مدل: اگر سرعت تبدیل از سرعت صحبت کردن شما عقب میماند، به مدل کوچکتر بروید. اگر اپلیکیشن نامها را به هم میریزد، یک سایز بالاتر بروید.
این رویکرد محلی، مدل اعتماد در ابزارهای هوش مصنوعی را بهطور بنیادی تغییر میدهد. یک سرویس ابری صدای خام را دریافت میکند و ممکن است آن را ذخیره، لاگ یا برای بهبود محصولاتش بر اساس سیاست حریمی که کاربر کنترلی روی آن ندارد، استفاده کند. در مقابل، Off Grid AI Desktop هیچ چیز دریافت نمیکند زیرا سروری وجود ندارد. بهدلیل متنباز بودن تحت AGPL-3.0، کاربران میتوانند تأیید کنند که صدا روی دستگاه پردازش شده و سپس دور ریخته میشود. هیچ تلمتری (Telemetry)، هیچ حسابی و هیچ آپلودی وجود ندارد. اگر کابل شبکه را بکشید، دیکته همچنان کار میکند.
برای کاربر عادی، این یعنی پایان «مالیات اشتراکی» برای تبدیل سادهی صدا به متن. توانایی دیکته کردن ایدههای خام و پالایش آنها بهصورت محلی، سد روانی «ضبط کردن» چیزی که ممکن است توسط یک ارائهدهنده لاگ شود را از بین میبرد.
نقشه راه و پرسشهای متداول
انتظار میرود بهروزرسانیهای آینده برای این پلتفرم شامل موارد زیر باشد:
- قابلیت Push-to-talk و کلیدهای میانبر برای استفاده در خارج از ترکیبکننده (Composer).
- یکپارچگی تنگتر با ضبطکننده جلسات برای زیرنویسهای زنده.
- همگامسازی میاندستگاهی تا یک عبارت دیکته شده در یک ماشین به ماشین دیگر برسد.
- زبانهای تبدیل بیشتر و اندازههای مدل متنوعتر در داخل برنامه.
پاسخ به سوالات متداول تایید میکند که این ابزار کاملاً رایگان است و هیچ پرداخت یا دوره آزمایشی ندارد. ۸ گیگابایت رم برای مدلهای کوچک کافی است، در حالی که ۱۶ گیگابایت اجازه میدهد مدلهای بزرگتر در کنار یک Chat LLM محلی اجرا شوند.
برای شروع، کاربران میتوانند آخرین نسخه را از GitHub دانلود کرده، اپلیکیشن را نصب نموده و مدل 'small' ویسپر را به عنوان نقطه شروع انتخاب کنند. یک چت را باز کنید، روی میکروفون کلیک کنید، دسترسی به میکروفون را تایید کنید و صحبت کنید. متن فوراً برای ویرایش و ارسال ظاهر میشود، بدون هیچ دیوارهی ثبتنام و بدون نیازی به چسباندن کلید API.
گام بعدی شما
- اگر با دادههای حساس (پزشکی یا مالی) سروکار دارید، همین امروز جایگزین ابزارهای ابری را با مدل 'Small' آزمایش کنید.
- برای افزایش سرعت در سختافزارهای قدیمی، مدل 'Tiny' را امتحان کنید تا توازن سرعت و دقت را بسنجید.
- در صورت استفاده از ویندوز، مطمئن شوید درایورهای CUDA بهروز هستند تا از شتاب گرافیکی بهره ببرید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو