
اگر روی کدهای حساس یا پروژههایی با قراردادهای محرمانگی (NDA) سختگیرانه کار میکنید، ارسال سورسکد به سرورهای ابری یک ریسک پذیرفتهناپذیر است. اکنون میتوانید با هدایت عاملهای کدنویسی خود به یک سرور محلی Ollama، این ریسک را بهطور کامل حذف کنید تا هیچ دادهای از شبکه شما خارج نشود. این روش برای افزایشدهندههای بهرهوری محبوب مانند Codex CLI، Claude Code، Cursor و Pi کاربرد دارد.
این تغییر مسیر به سمت استنتاج محلی — یعنی لحظهای که مدل واقعاً جواب تولید میکند و شبیه خودِ آشپزی است نه دورهی آموزش آشپز — درست زمانی رخ میدهد که توسعهدهندگان به دنبال فرار از صورتحسابهای توکنمحور و محدودیتهای نرخ درخواست (Rate Limit) در جلسات تمرکز عمیق هستند. مزیت این روش ساده است: خروج صفر داده، هزینه صفر برای هر تعداد تکمیل کد (چه ۱۰ مورد باشد و چه ۱۰,۰۰۰ مورد) و دسترسی کامل در حالت هواپیما، شبکههای محدود یا VPNهای ناپایدار. دیگر خبری از خطاهای ۴۲۹ در ساعت ۲ صبح، درست زمانی که در اوج جریان کاری هستید، نخواهد بود.
همانطور که در تحلیل قبلی ما دربارهی امنیت مدلهای بازمتن اشاره کردیم، کنترل بر لایهی استنتاج، کلید حریم خصوصی در عصر هوش مصنوعی است. اگرچه مدلهای پیشرو مانند Claude Opus 4 یا GPT-5 هنوز در استدلالهای پیچیده چندمرحلهای و وظایفی با پنجرههای متنی بسیار بزرگ پیشرو هستند، اما مدلهای محلی به نقطهٔ اثر رسیدهاند. برای ۸۰٪ کارهای روزمره — از تکمیل خودکار و بازنویسی کد گرفته تا تولید تست و مستندات — یک مدل محلیِ منتخب کاملاً پاسخگو و کافی است.
به نقل از یک راهنمای فنی که در ۷ ژوئن ۲۰۲۶ منتشر شد، مدل qwen3-coder:30b موتور اصلی این پیکربندی است. این مدل از معماری مخلوط خبرگان (MoE) — شبیه تیمی از متخصصان که در هر لحظه فقط فرد مناسب برای پاسخ به سوال فراخوانده میشود — استفاده میکند. به همین دلیل، با وجود اندازه کلی، تنها ۳.۳ میلیارد پارامتر در هر توکن فعال هستند و سرعت استنتاج را بالا نگه میدارند. این مدل در بنچمارک HumanEval از GPT-4o پیشی گرفته و دارای پنجره متنی (Context Window) — یعنی میز کاری که مدل همزمان چند ورق را روی آن نگه میدارد — به اندازه ۲۵۶ هزار توکن است که کل codebase را بدون نیاز به تکهتکه کردن (Chunking) پردازش میکند. برای دریافت آن از دستور ollama pull qwen3-coder:30b استفاده کنید.
سختافزار و انتخاب مدل
اجرای این عاملها به حافظه مشخصی نیاز دارد. در سیستمهای اپل سیلیکون، حافظه یکپارچه اجازه میدهد GPU و CPU از یک مخزن مشترک استفاده کنند که این ویژگی آن را برای مدلهای زبانی بزرگ (LLM) ایدهآل میکند. برای مثال، در یک مک M4 Pro با ۴۸ گیگابایت حافظه یکپارچه، یک مدل ۲۲ گیگابایتی بهراحتی در کنار یک محیط توسعه کامل جای میگیرد.
نیازمندیها به این ترتیب است:
- ۱۶ گیگابایت رم: پشتیبانی از مدلهای ۷ تا ۸ میلیارد پارامتری مثل qwen3:8b یا llama3.2:8b.
- ۳۲ گیگابایت رم: پشتیبانی از مدلهای ۱۴ تا ۲۰ میلیارد پارامتری مثل qwen3:14b یا gpt-oss:20b.
- ۴۸ گیگابایت رم: نقطه بهینه برای qwen3-coder:30b (حدود ۲۲ گیگابایت روی دیسک) یا qwen3.6:35b (حدود ۲۴ گیگابایت روی دیسک).
- ۶۴ گیگابایت رم و بیشتر: لازم برای مدلهای ۷۰ میلیارد پارامتری مثل deepseek-r1:70b (حدود ۴۵ گیگابایت روی دیسک) یا llama3.3:70b.
برای کسانی که از سیستمهای اینتل یا AMD با گرافیک مجزا استفاده میکنند، حافظه VRAM گلوگاه اصلی است. مدلهایی که از VRAM موجود بیشتر شوند، باعث فعال شدن مکانیسم کندِ انتقال داده به CPU (Offloading) شده و تجربه توسعهدهنده را بهشدت تخریب میکنند.
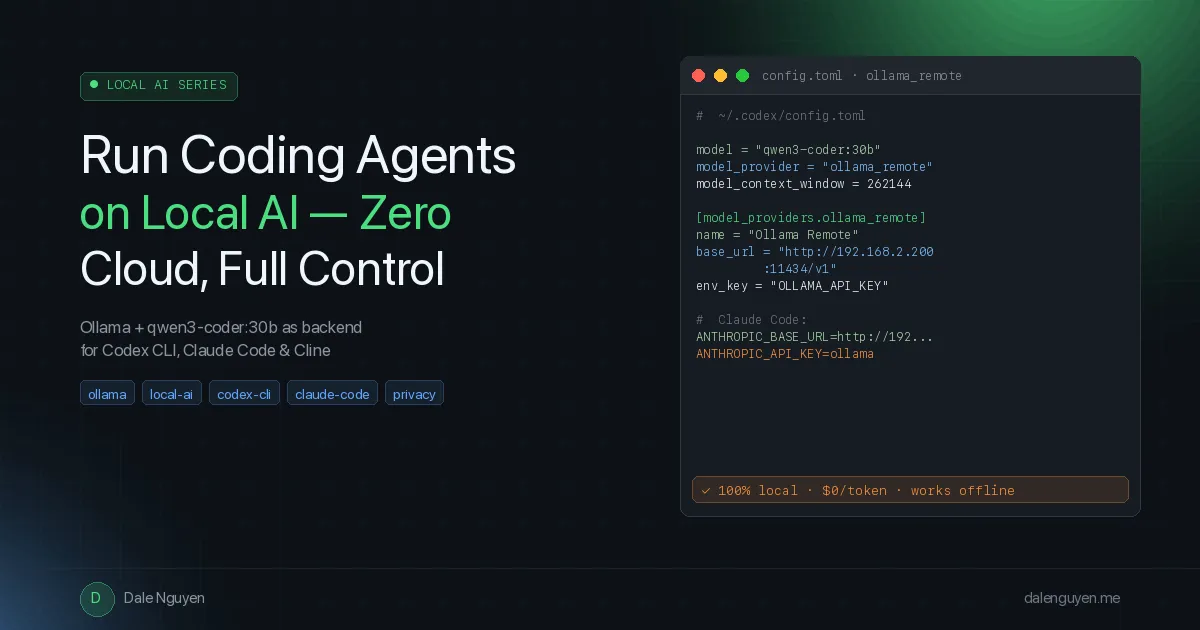
پیکربندی بکاند محلی
بهطور پیشفرض، Ollama فقط روی localhost گوش میدهد. برای دسترسی ابزارهای خارجی یا سایر ماشینهای شبکه محلی (LAN)، باید آن را با تنظیم متغیر محیطی OLLAMA_HOST=0.0.0.0 و اجرای دستور ollama serve به تمام رابطهای شبکه متصل کنید.
در macOS، برای دائمی کردن این تنظیم، باید launch agent مربوط به Ollama را ویرایش کنید یا متغیر محیطی را در پروفایل شل (Shell Profile) خود قرار دهید. پس از پیکربندی، سرور از طریق IP شبکه محلی شما (مثلاً http://192.168.2.200:11434) در دسترس خواهد بود. میتوانید اتصال را با اجرای دستور curl http://192.168.2.200:11434/api/tags | jq '.models[].name' بررسی کنید.
از آنجا که Ollama یک نقطه اتصال (Endpoint) سازگار با OpenAI در مسیر /v1 فراهم میکند، میتوان آن را با کمترین تغییر در پیکربندی، به اکثر چارچوبهای مدرن عاملهای هوش مصنوعی تزریق کرد.
ادغام با ابزارهای اصلی کدنویسی
Codex CLI ابزار ترمینالی OpenAI است. برای نصب از دستور npm install -g @openai/codex استفاده کنید. این ابزار به یک فایل پیکربندی TOML سفارشی در مسیر ~/.codex/config.toml و یک فایل JSON کاتالوگ مدلهای خاص نیاز دارد تا از خطاهای متادیتا جلوگیری کند.
در فایل config.toml باید مقدار model_context_window را صراحتاً روی ۲۶۲,۱۴۴ تنظیم کنید و از یک شناسهی ارائهدهنده سفارشی مثل ollama_remote استفاده کنید. توجه داشته باشید که استفاده از خط تیره (ollama-remote) باعث خطای تجزیه (Parse Error) میشود و حتماً باید از زیرخط (Underscore) استفاده کنید. همچنین فیلد name در بلوک [model_providers.*] الزامی است، در غیر این صورت ابزار خطای «provider name must not be empty» را میدهد. از آنجا که شناسههای ollama ،openai و lmstudio رزرو شده و داخلی هستند، باید حتماً نامی مثل ollama_remote را به کار ببرید.
برای جلوگیری از رد درخواست توسط API، مقدار supported_reasoning_levels باید یک آرایه خالی [] و supports_reasoning_summaries روی false در کاتالوگ تنظیم شود. بدون این تنظیمات، Codex پارامتر «thinking» را میفرستد که Ollama آن را با خطای «does not support thinking» رد میکند. اگرچه qwen3-coder:30b از استدلال داخلی با تگهای <think> پشتیبانی میکند، اما غیرفعال کردن این پارامتر در سطح API، مانع از درخواست Codex به فرمت خاص OpenAI میشود.
برای تولید کاتالوگ مدلها از متادیتای bundled، از این دستور استفاده کنید:codex debug models --bundled | python3 -c " import json, sys d = json.load(sys.stdin) m = d['models'][0].copy() m['slug'] = 'qwen3-coder:30b' m['display_name'] = 'Qwen3-Coder 30B' m['description'] = 'Coding-specialized MoE model with 256K context.' m['context_window'] = 262144 m['max_context_window'] = 262144 m['availability_nux'] = None m['upgrade'] = None m['supported_reasoning_levels'] = [] m['default_reasoning_level'] = 'low' m['supports_reasoning_summaries'] = False m['default_reasoning_summary'] = 'none' print(json.dumps({'models': [m]}, indent=2)) " > ~/.codex/model_catalog.json
از آنجا که Ollama نیاز به احراز هویت ندارد، باز هم باید یک متغیر محیطی صوری export OLLAMA_API_KEY=ollama در فایل ~/.zshrc تعریف کنید تا Codex اجازه شروع به کار داشته باشد. سپس میتوانید صرفاً با تایپ codex در هر پوشه پروژه، عامل را فعال کنید.
Claude Code، ابزار رسمی Anthropic، بهطور پیشفرض به API خود این شرکت متصل است اما اجازه تغییر Base URL را میدهد. با خروجی گرفتن از ANTHROPIC_BASE_URL=http://192.168.2.200:11434 و ANTHROPIC_API_KEY=ollama و انتخاب روش «Anthropic Console» هنگام ورود، میتوانید آن را به سرور محلی منتقل کنید. با اینکه پرامپتهای سیستم برای مدلهای Claude بهینه شدهاند، qwen3-coder:30b آنها را با خطاهای جزئی در فرمت که تأثیری در عملکرد ندارد، بهخوبی پردازش میکند.
کاربران Cursor میتوانند از مسیر Settings (Cmd+,) → Models، گزینه «Override OpenAI Base URL» را فعال کرده و آدرس http://192.168.2.200:11434/v1 را وارد کنند. با قرار دادن ollama به عنوان API Key و انتخاب یا تایپ مدل qwen3-coder:30b در لیست، وابستگی به زیرساخت ابری Cursor برای تکمیل و بازنویسی کدها حذف میشود.
Pi (pi.dev) یک چارچوب مینیمال است که از طریق فایل models.json در مسیر ~/.pi/agent/ از نقاط اتصال محلی پشتیبانی میکند. برای نصب از npm install -g @pi-ag/coding-agent استفاده کنید. یک نکته حیاتی در پیکربندی این ابزار، بلوک compat است؛ تنظیم supportsDeveloperRole و supportsReasoningEffort روی false مانع از ارسال پارامترهایی میشود که Ollama قادر به پردازش آنها نیست. شما میتوانید در طول یک جلسه با دستور /model مدلها را سریعاً عوض کنید، زیرا فایل models.json بین جلسات بهطور خودکار بازخوانی (Hot-reload) میشود.
توازن عملکرد و محدودیتها
طبق گزارش نویسنده راهنما، استقرار محلی جایگزینی کامل برای ابری در هر سناریویی نیست. مدل qwen3-coder:30b در موارد زیر میدرخشد:
- بازنویسی و اصلاح تکفایلها.
- تولید تستهای واحد (Unit Tests) از روی کد موجود.
- نوشتن کوئریهای SQL، اسکریپتهای شل و فایلهای پیکربندی.
- تولید کدهای اولیه (Boilerplate) و مستندات.
- بررسی کد (Code Review) و توضیح منطقهای موجود.
اما مدلهای پیشرو همچنان در موارد زیر برتری دارند:
- تغییرات معماری چندفایله که نیاز به استدلال عمیق بین فایلها دارد.
- وظایفی که نیاز به نگه داشتن حجم عظیمی از متن در لحظه دارند (علیرغم پنجره ۲۵۶ هزار توکنی).
- طراحی الگوریتمهای نو در دامنههای پیچیده.
- شناسایی آسیبهای امنیتی بسیار ظریف در الگوهای ناآشنا.
از نظر عملیاتی، باید با تأخیر «استارت سرد» (Cold Start) در اولین استنتاج که چند ثانیه طول میکشد تا مدل بارگذاری شود، کنار بیایید. همچنین در مک، برای جلوگیری از تعلیق Ollama در هنگام خواب سیستم، گزینه «Prevent computer from sleeping» را فعال کنید. در نهایت، چون سرور Ollama بهطور پیشفرض احراز هویت ندارد، هرگز آن را از طریق پورت ۱۱۴۳۴ در اینترنت باز نگذارید و فقط در شبکه محلی (LAN) نگه دارید.
مدلهای محلی جایگزین
بسته به نیاز، میتوانید مدلها را با ollama pull تغییر داده و پیکربندی خود را بهروز کنید:
- وظایف بصری: برای پردازش اسکرینشاتها و دیاگرامها از qwen3.6:35b (حدود ۲۴ گیگابایت روی دیسک) به دلیل پشتیبانی چندوجهی و استدلال عمومی استفاده کنید.
- فراخوانی ابزار (Tool Calling): مدل gpt-oss:20b (حدود ۱۴ گیگابایت روی دیسک) خروجیهای ساختاریافتهتری برای گردشهای کاری عاملمحور و فراخوانی توابع میدهد.
- استدلال رسمی: برای کارهای ریاضیمحور و خروجیهای ساختاریافته، gemma4:27b (حدود ۱۸ گیگابایت روی دیسک) توصیه میشود.
- زنجیره تفکر (Chain-of-Thought): اگر بیش از ۴۵ گیگابایت رم آزاد دارید، deepseek-r1:70b (حدود ۴۵ گیگابایت روی دیسک) بهترین گزینه برای ردیابیهای استدلالی پیچیده است.
این پیکربندی، تجربه کدنویسی با هوش مصنوعی را از یک سرویس اشتراکی ابری به یک زیرساخت مالکانه تبدیل میکند. با تبدیل کردن ابر به یک گزینه «انتخابی» برای استدلالهای فوقسنگین به جای یک پیشفرض، توسعهدهندگان کنترل کامل مالکیت معنوی خود را بازپس میگیرند. ابزارها همیشه آماده اتصال به هر نقطه اتصال سازگاری بودند؛ حالا شما نقطهای دارید که مالک آن هستید.
گام بعدی شما
- اگر از Cursor یا Claude Code استفاده میکنید، همین امروز یک سرور Ollama روی ماشین محلی یا یک سرور داخلی راه اندازید.
- مدل
qwen3-coder:30bرا تست کنید و سرعت آن را در بازنویسی تکفایلها با مدلهای ابری مقایسه کنید. - برای کارهای پیچیدهتر، مدل
deepseek-r1:70bرا در صورت داشتن رم کافی امتحان کنید تا تفاوت در زنجیره تفکر را ببینید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو