
تصور کنید یک کابل معیوب، آموزش مدلی را که میلیونها دلار هزینه برداشته، در یک لحظه نابود کند. برای OpenAI، این ریسک غیرقابل قبول است و به همین دلیل معماری ارتباطی پردازندهها را از پایه بازطراحی کردهاند.
در ۵ مه ۲۰۲۶، OpenAI مشخصات فنی پروتکل اتصال قابلاعتماد چندمسیره (Multipath Reliable Connection یا MRC) را از طریق پروژه محاسبات باز (Open Compute Project) منتشر کرد. به نقل از مستندات این شرکت، این پروتکل که با همکاری AMD، Broadcom، Intel، Microsoft و NVIDIA توسعه یافته، برای حذف اثر «تقویتکننده شکست» طراحی شده است؛ وضعیتی که در آن نوسانات کوچک در لینکهای ارتباطی باعث توقف ثانیهای یا کرش کامل فرآیند پیشآموزش میشود.
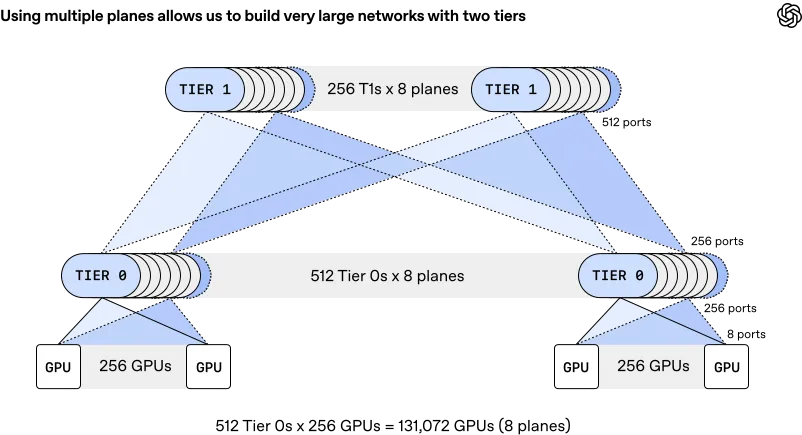
بر اساس مستندات منتشر شده، این پروتکل سه تغییر معماری بنیادین را معرفی میکند:
- توپولوژی چندصفحهای (Multi-plane Topology): به جای استفاده از یک لینک واحد ۸۰۰ گیگابیت بر ثانیه، MRC آن را به هشت صفحه ۱۰۰ گیگابیت تقسیم میکند. این سازوکار اجازه میدهد ۱۳۱,۰۰۰ پردازنده گرافیکی (GPU) تنها با دو لایه سوئیچ متصل شوند، در حالی که طراحیهای سنتی به سه یا چهار لایه نیاز دارند.
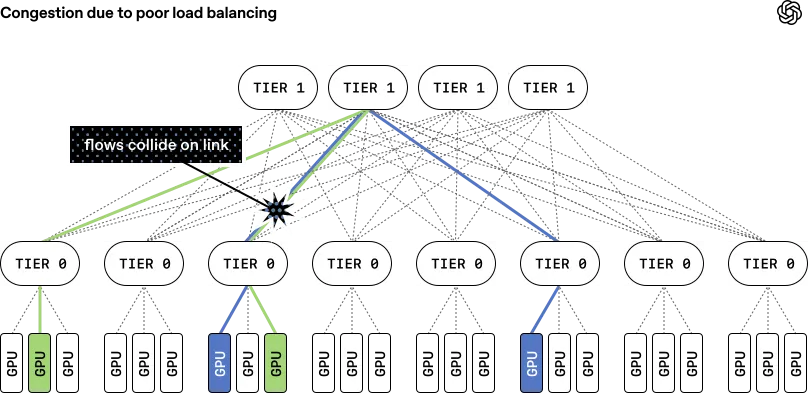
- پاشش تطبیقی بستهها (Adaptive Packet Spraying): به جای اختصاص یک مسیر واحد برای انتقال داده، MRC بستهها را در صدها مسیر پخش میکند. این روش بهطور مجازی تراکم هسته را حذف کرده و از ایجاد «نقاط داغ» که سرعت آموزش همگام را کاهش میدهند، جلوگیری میکند.
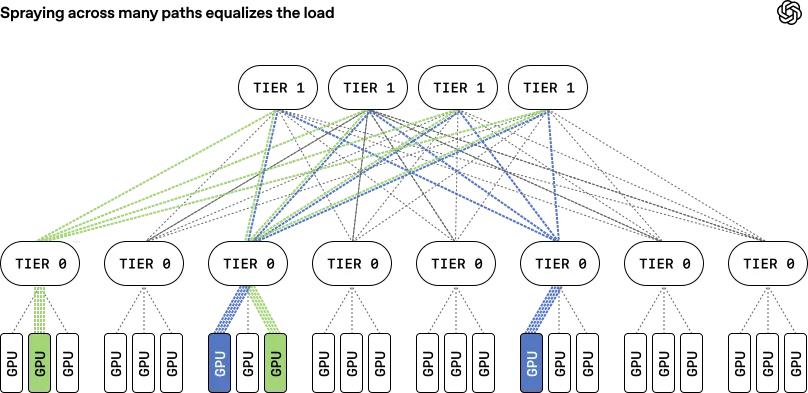
- مسیریابی منبع SRv6 (SRv6 Source Routing): با استفاده از مسیریابی قطعهبندی IPv6 (IPv6 Segment Routing)، فرستنده مسیر دقیق هر بسته را تعیین میکند. این قابلیت اجازه میدهد سیستم در کمتر از یک میکروثانیه لینکهای معیوب را دور بزند و نیاز به پروتکلهای پیچیده مسیریابی پویا مانند BGP را از بین ببرد.


برای مدیریت تراکم در مقصد، MRC از «هرس کردن بستهها» استفاده میکند؛ جایی که سوئیچها تنها سرآیند (Header) بستههای متراکم را ارسال میکنند تا بازگشت سریع داده تحریک شود. این کار مانع از آن میشود که سیستم بهاشتباه یک گلوگاه ساده را به عنوان شکست کامل مسیر شناسایی کند.

همانطور که در تحلیل قبلی ما دربارهی قوانین مقیاسپذیری (Scaling Laws) اشاره کردیم، افزایش تعداد پردازندهها بدون مدیریت دقیق شبکه، منجر به بازدهی معکوس میشود. این معماری در حال حاضر در ابررایانههای NVIDIA GB200، از جمله مراکز داده Oracle Cloud Infrastructure در تگزاس و خوشههای Fairwater متعلق به مایکروسافت پیادهسازی شده است.
OpenAI اشاره کرد که در جریان آموزش یکی از مدلهای پیشرو اخیر، آنها توانستند چهار سوئیچ لایه اول را بدون هماهنگی با تیمهای آموزش ریبوت کنند، زیرا MRC بهطور خودکار مسیرهای جایگزین را فعال کرد.


در حالی که پروژهی Stargate مرزهای قدرت محاسباتی (Compute) را جابهجا میکند، صنعت اکنون باید تصمیم بگیرد که آیا این استاندارد باز جایگزین استکهای شبکه اختصاصی خواهد شد یا خیر. این رویکرد در راستای استراتژی کلی OpenAI برای بازنگری در زیرساختهای ارتباطی است؛ همانطور که در بهینهسازی لایههای شبکه برای کاهش تأخیر مکالمات صوتی مشاهده کردیم، این شرکت بهدنبال حذف گلوگاههای سنتی در تمامی مراحل چرخه حیات مدلهاست.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- بررسی مستندات فنی MRC در وبسایت Open Compute Project برای درک عمیقتر SRv6.
- رصد گزارشهای عملکردی خوشههای GB200 در محیطهای ابری.
- تحلیل اثر کاهش لایههای سوئیچ بر تأخیر (Latency) در مدلهای استدلالی بزرگ.



گفتگو