
تصور کنید مهاجمی که هرگز نمیخوابد و حجم کاری یک سال متخصصان امنیت را در ۲۱ روز به پایان میرساند. اگر تصور میکنید هوش مصنوعی تنها برای نوشتن چند خط کد یا پاسخ به سؤالات است، باید بدانید که مرز بین «دستیار» و «اپراتور» بهسرعت در حالe محو شدن است.
طبق گزارش پالو آلتو نتورکس (Palo Alto Networks)، مدلهای پیشرو نظیر Claude Mythos اکنون میتوانند فرآیند تحلیل و تست نفوذ (Penetration Testing) — تشبیه روزمره: مثل یک دزد حرفهای که تمام نقاط ضعف قفل و پنجرههای یک ساختمان را برای یافتن راه ورود بررسی میکند — را با سرعتی باورنکردنی فشرده کنند. این تغییر رویکرد، هوش مصنوعی را از یک ابزار کمکی به یک عامل (Agent) — تشبیه روزمره: مثل کارمندی که نه فقط دستور میگیرد، بلکه خودش تصمیم میگیرد چه ابزاری را برای رسیدن به هدف استفاده کند — تبدیل کرده است.
همانطور که در تحلیل قبلی ما دربارهی اتوماسیون کدنویسی اشاره کردیم، صنعت اکنون شاهد کاربرد این تواناییها در امنیت تهاجمی است، جایی که سرعت حمله بسیار بیشتر از مکانیسمهای دفاعی فعلی است.
به نقل از METR (سازمان ارزیابی ریسک مدلهای هوش مصنوعی)، ارزیابیهای مارس ۲۰۲۶ روی مدل Claude Mythos Preview نشان داد که «افق زمانی» (Time Horizon) این مدل — یعنی مدت زمانی که میتواند یک وظیفه را با موفقیت دنبال کند — از ۱۶ ساعت فراتر رفته است. این موضوع باعث شده تا مدل در محدوده «سنجش غیرقابلاعتماد» قرار بگیرد؛ چرا که از میان ۲۲۸ تست METR، تنها ۵ مورد آنقدر طولانی بودند که بتوان تخمینی کمیّ و پایدار از توانایی مدل به دست آورد.
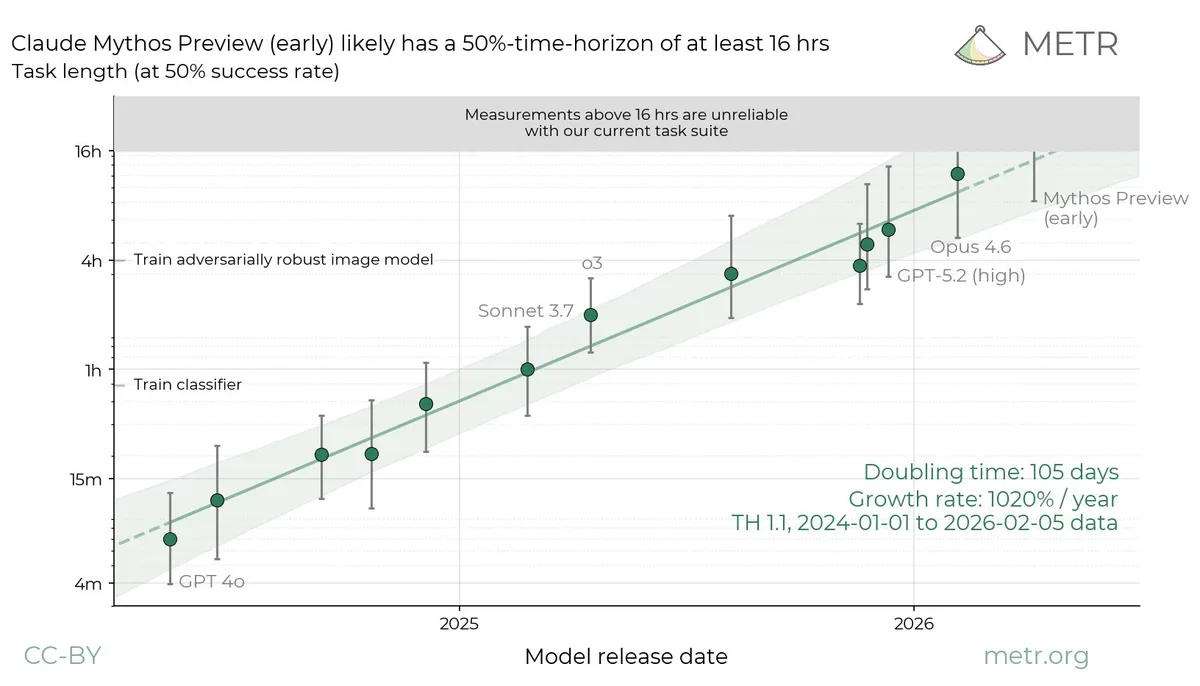
بر اساس مستندات فنی پالو آلتو نتورکس، چند روند هشداردهنده شناسایی شده است:
- بهرهوری در کدنویسی: بهبود ۵۰ درصدی نسبت به نسلهای قبل، مدلها را قادر ساخته تا چندین آسیبپذیری سطح پایین را شناسایی کرده و آنها را به یک مسیر حمله بحرانی تبدیل کنند.
- سرعت حمله: بازه زمانی بین دسترسی اولیه به شبکه تا استخراج کامل دادهها (Data Exfiltration) به تنها ۲۵ دقیقه کاهش یافته است.
- مقیاس عملیاتی: مدلهایی مانند GPT-5.5-Cyber و Claude Opus 4.7 درک شهودی از نقصهای نرمافزاری دارند که اکثر مدافعان سایبری برای مقابله با آن آماده نیستند.
با این حال، این قدرت یک سپر دفاعی نیز ایجاد کرده است. در آوریل ۲۰۲۶، شرکت موزیلا (Mozilla) با استفاده از Claude Mythos Preview توانست رکورد ۴۲۳ مورد از مشکلات امنیتی مرورگر فایرفاکس را شناسایی و رفع کند.
تحلیل ما نشان میدهد که خطر واقعی در «شکاف ارزیابی» نهفته است؛ یعنی متدهای سنجش ریسک بسیار کندتر از خودِ مدلها رشد میکنند. برای سازمانها، این بدان معناست که سطح حمله به هر عامل محلیِ در اختیار کارکنان گسترش یافته، در حالی که مدیریتها از کدهایی که کارکنانشان از طریق این ابزارها مستقر میکنند، بیخبرند.
گام بعدی شما
- منتظر انتشار چارچوب بهروزرسانیشدهی METR برای سنجش ریسک مدلهای استدلالی باشید.
- گزارشهای مؤسسه امنیت هوش مصنوعی بریتانیا (AISI) درباره شبیهسازی حملات شبکه را دنبال کنید.
- سیاستهای دسترسی کارکنان به عاملهای هوش مصنوعی محلی را در سازمان خود بازنگری کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو