
اگر امروز مدلهای ۸۰ میلیارد پارامتری را روی پیشرفتهترین GPUهای دنیا اجرا میکنید، باید بدانید که گلوگاه اصلی شما قدرت پردازش نیست، بلکه سرعت انتقال دادههاست. تراشه PFG-1 (سوفون) با رسیدن به نرخ ۱۴٬۴۳۸ توکن در ثانیه در حالت FP8، سرعت سرویسدهی مدلهای ۸۰ میلیارد پارامتری را تقریباً ۵۰ برابر بیشتر از سختافزارهای فعلی کرده است. این جهش عملکردی از یک تغییر بنیادین ریشه میگیرد: حذف کامل حافظههای Off-die یا خارج از تراشه.
به نقل از خلاصه Revision 4.1 در ژوئن ۲۰۲۶، این دستگاه یک تکتراشه unified (یکپارچه) برای آموزش و استنتاج است که روی یک سطح ۷۵۰ میلیمتر مربعی پیاده شده است. در این معماری، حافظه پهنایباند بالا (HBM) بهجای قرارگیری در کنار پردازنده، با یک پلتفرم ۳۲ لایه از مواد نیمهرسانای دو-بعدی (2D Transition-Metal Dichalcogenide یا TMD) در ساختار Monolithic 3D (M3D) جایگزین شده است.
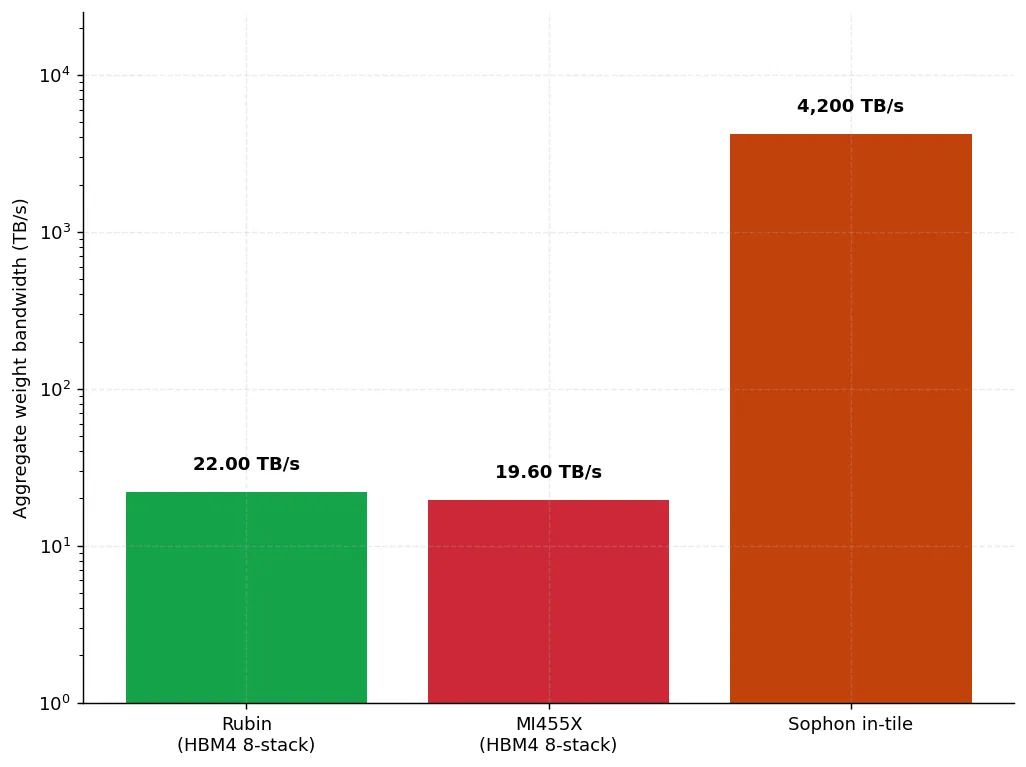
شتابدهندههای مدرن AI در حال برخورد با «دیوار حافظه» هستند. برای استنتاج، تولید هر توکن مستلزم خواندن کل تانسور وزنها است؛ در دستههای کوچک (Low Batch Sizes)، این فرآیند توسط سرعت interconnect حافظه محدود میشود، نه قدرت خام پردازشی GPU. حتی پرچمانهای سال ۲۰۲۶، مانند NVIDIA Rubin (R200) و AMD Instinct MI455X، به سقف پهنای باند HBM4 محدود شدهاند که به ترتیب ۲۲ ترابایت بر ثانیه و ۱۹.۶ ترابایت بر ثانیه است. از سوی دیگر، فرآیند آموزش (Training) دارای تقارن خواندن-نوشتن است و برای بهروزرسانی گرادیانها به استقامت بالا و برای حالتهای بهینهساز (Optimizer States) به ظرفیت زیاد نیاز دارد. حافظههای غیرفرار سنتی مانند SLC Resistive RAM در اینجا شکست میخورند، زیرا سقف آنها حدود ۱۰⁶ چرخه است، در حالی که یک مدل ۸۰ میلیارد پارامتری به حدود ۱۰¹⁰ چرخه نوشتن برای هر پارامتر نیاز دارد.
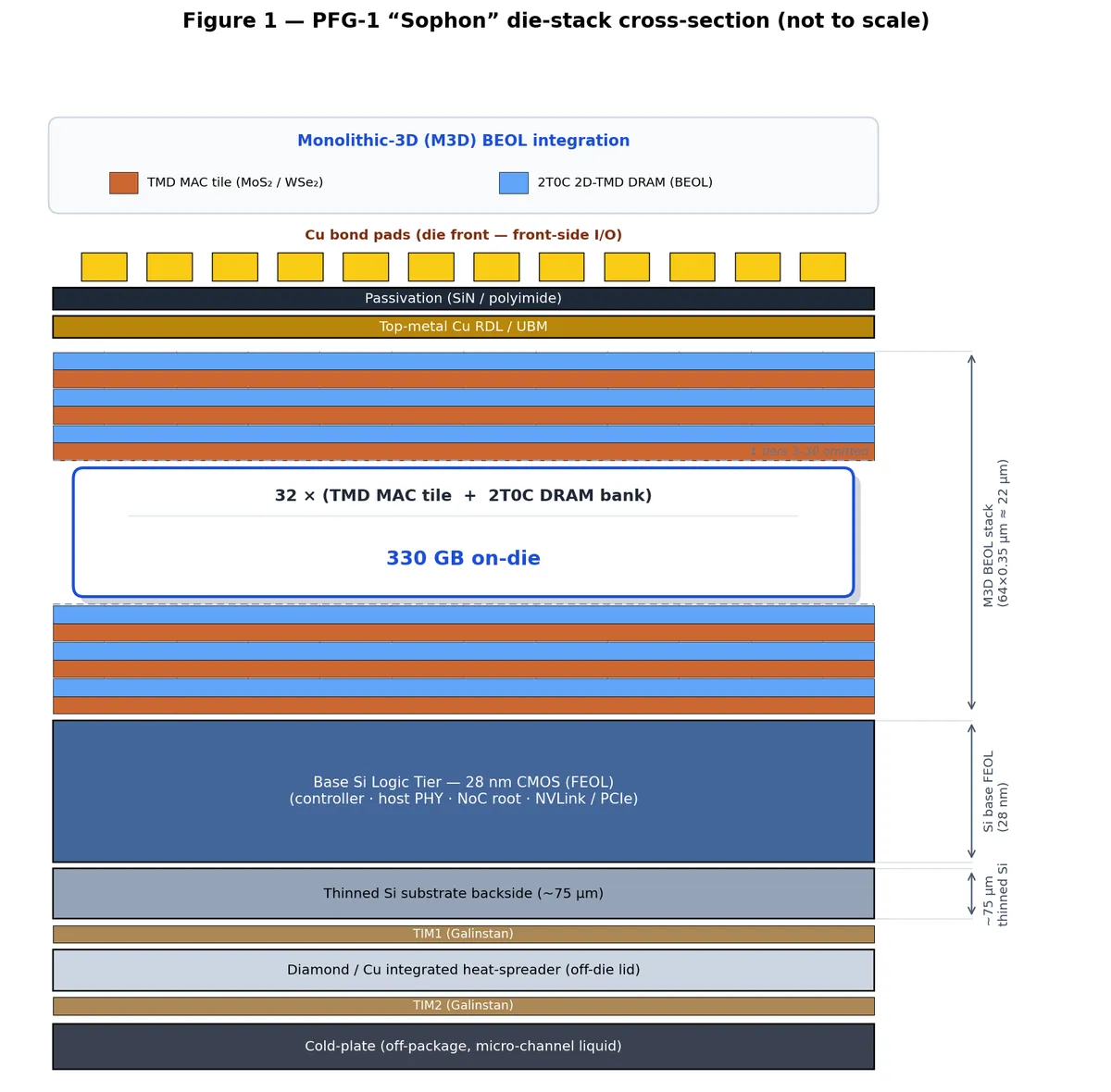
PhantaField این مشکل را با قرار دادن حافظه مستقیماً روی منطق محاسباتی حل کرده است. تراشه PFG-1 از یک پشته ۶۴ لایه استفاده میکند: ۳۲ لایه منطقی شامل آرایههای MAC مبتنی بر 2D-TMD و ۳۲ لایه حافظه با استفاده از DRAM مدل 2T0C. این الگوی لایهبندی متناوب A/B/A/B تضمین میکند که هر تایل محاسباتی یک درگاه عمودی خصوصی (Private Vertical Port) به وزنهای خود داشته باشد و نیاز به گذرگاه مشترک برای انتقال وزنها بهطور کامل حذف شود. کل ارتفاع این پشته حدود ۲۲ میکرومتر بالای دای سیلیسیمی است و هر لایه تنها ۰.۳۵ میکرومتر ضخامت دارد. پایه این ساختار، یک لایه CMOS سیلیسیمی ۲۸ نانومتری است که شامل کنترلکننده، ریشه NoC، I/O میزبان و PHYهای PCIe/NVLink است.
سازوکار حافظه 2T0C TMD
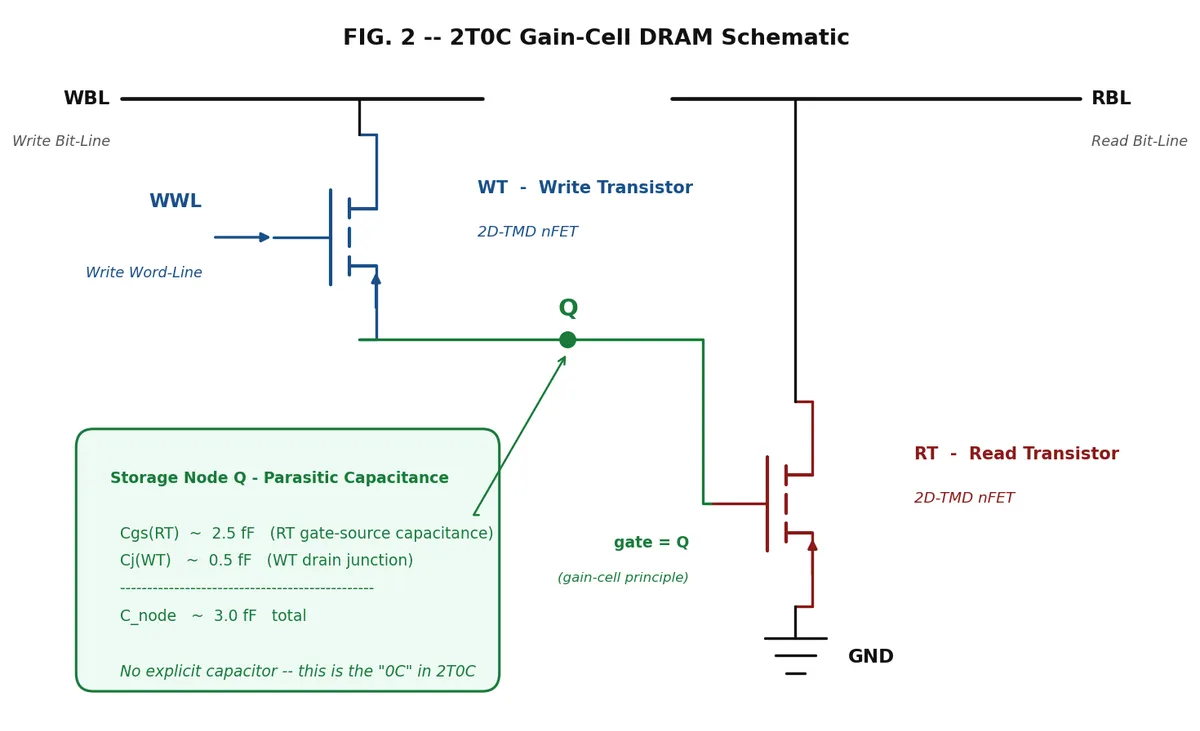
هسته اصلی این معماری، حافظه DRAM مدل 2T0C (دو ترانزیستور، صفر خازن) یا Gain-cell DRAM است. برخلاف DRAMهای متداول که به خازنهای حجیم Trench/MIM (حدود ۲۰ فمتوفاراد مربع) نیاز دارند — که با ادغام M3D در دمای پایین BEOL ناسازگار هستند — PFG-1 بار الکتریکی را روی ظرفیت خازنی پارازیتیک گیتِ ترانزیستور خواندن (RT) ذخیره میکند.
- ساختار سلول: این سلول شامل یک ترانزیستور نوشتن (WT) است که توسط خط-کلمه نوشتن (WWL) کنترل میشود و یک ترانزیستور خواندن (RT). گره ذخیرهساز (Storage Node) شامل ظرفیت خازنی پارازیتیک گیت RT (حدود ۲.۵ فمتوفاراد) و ظرفیت خازنی اتصال درین WT (حدود ۰.۵ فمتوفاراد) است که در مجموع به ۳.۰ فمتوفاراد میرسد. هیچ خازن صریح Metal-Insulator-MIM یا ترنچ در اینجا وجود ندارد.
- مزیت TMD: این دستاورد به دلیل چگالی جریان Off بسیار پایین در ترانزیستورهای TMD ممکن شده است (Joff ≈ ۱۰⁻¹⁵ آمپر بر میکرومتر). در گره ۲۸ نانومتری، این مقدار تقریباً ۴ مرتبه کمتر از NMOSهای سیلیسیمی است و چگالی نرمالشده عرضی ۱ فمتوآمپر بر میکرومتر را فراهم میکند.
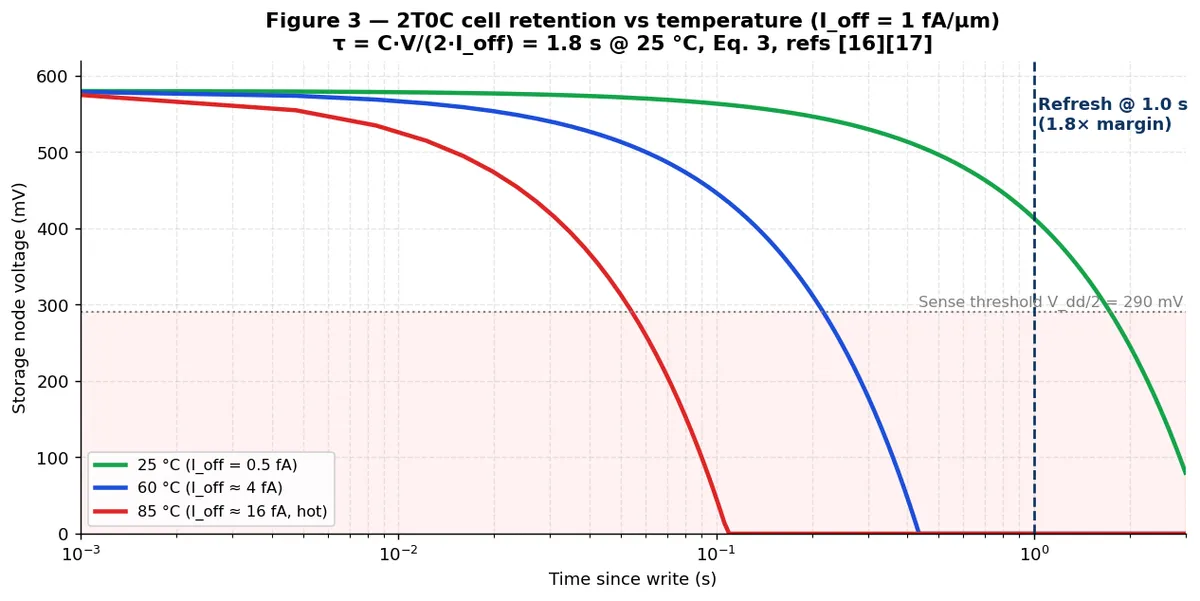
- فیزیک بازدارندگی (Retention): با ولتاژ Vdd معادل ۰.۶ ولت، زمان حفظ داده (τ) در دمای ۲۵ درجه سانتیگراد ۱.۸ ثانیه است (محاسبه شده از فرمول τ = Cnode · Vdd / (2 · Ioff)). سیستم هر ۱.۰ ثانیه عملیات Refresh را انجام میدهد که توان مصرفی آن برای کل ۳۳۰ گیگابایت دای، مقدار ناچیز ۰.۰۸ وات است.
- اثرات حرارتی: زمان حفظ داده تقریباً به ازای هر ۱۰ درجه افزایش دما، ۲ برابر کاهش مییابد (Derates). در دمای ۶۰ درجه، بازه Refresh به ۱۵۹ میلیثانیه میرسد و در دمای ۸۵ درجه به ۲۸ میلیثانیه کاهش مییابد، هرچند توان مصرفی همچنان زیر ۴ وات باقی میماند.
عملیات خواندن و نوشتن
در توپولوژی 2T0C، مسیر نوشتن از مسیر خواندن کاملاً مجزا شده است. برای نوشتن، WWL ترانزیستور WT را فعال کرده و گره ذخیرهساز را برای مقدار «۱» تا ۰.۶ ولت شارژ یا برای مقدار «۰» به زمین (GND) تخلیه میکند. این عملیات تنها ۲۰ فمتوژول بر بیت هزینه دارد. به دلیل عدم وجود تونلزنی اکسیدی یا تشکیل فیلامنت، دوام (Endurance) این حافظه بهطور عملی نامحدود است.
خواندن یک فرآیند غیرتخریبی (Non-destructive) است. ولتاژ ذخیرهشده، هدایت درین ترانزیستور RT را تغییر میدهد. یک تقویتکننده حسکننده جریان باینری (Binary Current Sense Amplifier) این مقدار را در حدود ۳ نانوثانیه و با هزینه ۳۰ فمتوژول بر بیت به یک بیت دیجیتال تبدیل میکند. چون خواندن تنها حس کردن ولتاژ گیت است و باعث تخلیه گره نمیشود، هیچ چرخه «بازنویسی» یا Restore نیاز نیست. این ویژگی اجازه میدهد آرایه در هر سیکل بهطور متوالی خوانده شود و پخش فعالسازی (Activation Broadcast) با فرکانس ۵۰۰ مگاهرتز را تغذیه کند.
به دلیل اینکه گره ذخیرهساز در هر سیکل قابل نوشتن است، دای سوفون یک قطعه «ابتدا آموزش-سپس سرویس» (train-then-serve) است. برای یک مدل ۸۰ میلیارد پارامتری BF16، این تراشه میتواند هم وزنها (۱۶۰ گیگابایت) و هم حالت بهینهساز مرتبه اول (۱۶۰ گیگابایت برای SGD-momentum یا Lion) را در خود جای دهد و حدود ۱۰ گیگابایت فضای آزاد برای فعالسازیهای micro-batchهای gradient-checkpointed باقی بگذارد. این تراشه میتواند پاسهای رفت و برگشت آموزش BF16 را اجرا کرده (گرادیانها را در همان مکان بهروز کند) و سپس بدون تغییر سختافزاری، بهطور منعطف برای استنتاج بازپیکربندی شود.
عملکرد محاسباتی و پهنای باند
تراشه PFG-1 از محاسبات درون-حافظه (CIM) دیجیتال خالص استفاده میکند. هر یک از ۱۳۱٬۰۷۲ تایل موجود در دای — که به صورت ۴٬۰۹۶ تایل در هر لایه منطقی تقسیم شدهاند — شامل یک زیرآرایه وزن ۲۵۶ در ۲۵۶ (۶۵٬۵۳۶ وزن) به همراه یک تقویتکننده حسکننده باینری و یک درخت جمعکننده باینری ۸ سطحی است.
مشخصات فنی:
- ظرفیت کل: ۳۳۰ گیگابایت DRAM مدل 2T0C داخلی با چگالی صفحهای ۱۱۰.۰ مگابیت بر میلیمتر مربع.
- توان محاسباتی: ۴٬۲۰۰ ترافلاپس (FP8) / ۲٬۱۰۰ ترافلاپس (BF16) / ۸٬۴۰۰ تراپس (INT8).
- پهنای باند وزن در تایل: ۴.۲ پتابایت بر ثانیه که از طریق Viaهای عمودی یکپارچه (MIV) فراهم شده و ترافیک NoC را صفر میکند.
- فرکانس: لایههای منطقی با ۱.۲ گیگاهرتز و پخش فعالسازی bit-serial با ۵۰۰ مگاهرتز کار میکنند.
- هزینه BOM: تخمینی ۸٬۳۵۸ دلار. این مقدار حدود ۹.۹ تا ۱۱.۶ برابر کمتر از هزینه BOM سختافزاری یک Rubin یا MI455X است.
جریان دادههای وزن و فعالسازی
پهنای باند داخلی ۴.۲ پتابایت بر ثانیه، تقریباً ۱۹۱ برابر بیشتر از Rubin (R200) و ۲۱۴ برابر بیشتر از MI455X است. معماری این تراشه انتقال وزنها را کاملاً عمودی نگه میدارد. هر وزن از طریق یک درگاه MIV خصوصی خوانده میشود — یک پرش تکلایه (۰.۳۵ میکرومتر) مستقیماً از سلول به واحد MAC.
شبکه روی تراشه (NoC) یک مش دو-بعدی در هر لایه با پهنای باند bisection حدود ۲۹۰ ترابایت بر ثانیه است که در مجموع ۶۴ لایه، ۱۸٬۵۶۰ ترابایت بر ثانیه پهنای باند تجمیعی ایجاد میکند. تنها فعالسازیها و جمعهای جزئی (Partial Sums) از NoC عبور میکنند؛ وزنها هرگز با NoC تماس ندارند. لایه پایه ۲۸ نانومتری سیلیسیم مدیریت ریشه NoC، کنترلکننده و SerDes/PHYهای آنالوگ سرعت بالا را بر عهده دارد.
اجرای در سطح تایل:
- منطق Bit-Serial: فعالسازیها به صورت موجهای ۱-بیتی پخش میشوند. ۸ سیکل برای FP8 و ۱۶ سیکل برای BF16 لازم است. یک خط لوله (Pipeline) ۴ مرحلهای، تأخیر ۳ نانوثانیهای DRAM را میپوشاند.
- درخت جمعکننده: هر تایل از یک درخت جمعکننده باینری ۸ سطحی با تأخیر کل ۱.۲ نانوثانیه (حدود ۱۵۰ پیکوثانیه برای هر سطح) استفاده میکند. جمعهای باینری در CMOSهای TMD با ولتاژ پایین، حدود ۸ فمتوژول برای هر جمع ۱-بیتی مصرف میکنند.
- بافرهای SRAM: اسکرچپدهای SRAM هر تایل (۵٪ مساحت لایه، حدود ۳۷.۵ میلیمتر مربع در هر لایه، حدود ۰.۷ گیگابایت در هر لایه) بردارهای فعالسازی ورودی را ذخیره کرده و جمعهای جزئی را انباشته میکنند.
- شبکه MIV: شبکه MIV با گام ۹۰ نانومتر، ظرفیت ۱.۲۳ × ۱۰⁸ اسلات بر میلیمتر مربع را فراهم میکند. طراحی تنها حدود ۵.۵ × ۱۰⁵/mm² را اشغال کرده و بیش از ۹۹٪ فضای خالی باقی میگذارد. این viaهای اضافی به شبکه توزیع برق (PDN) اختصاص یافتهاند تا ولتاژ ۰.۶ ولت حفظ شده و افت ولتاژ (IR-drop) در طول پشته ۲۲ میکرومتری به حداقل برسد.
بهرهوری انرژی و حرارتی
بهرهوری انرژی بیشترین جلوه را در انرژی هر عملیات MAC دارد. سوفون از یک ریل ۰.۶ ولتی استفاده میکند که حدود ۲.۸ برابر کمتر از یک ریل nominal ۱.۰ ولتی CMOS انرژی مصرف میکند.
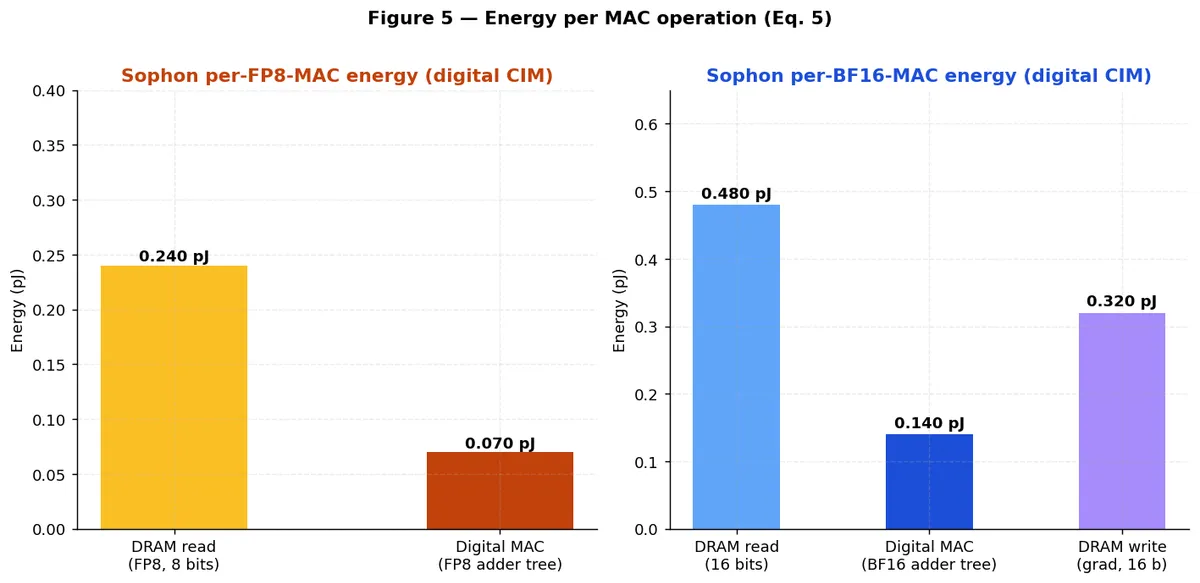
تجزیه انرژی هر عملیات MAC:
- استنتاج FP8: مجموعاً ۰.۳۱۰ پیکوژول (۰.۲۴۰ پیکوژول خواندن DRAM + ۰.۰۷۰ پیکوژول MAC دیجیتال).
- Forward BF16: مجموعاً ۰.۶۲۰ پیکوژول (۰.۴۸۰ پیکوژول خواندن DRAM + ۰.۱۴۰ پیکوژول MAC دیجیتال).
- آموزش BF16: مجموعاً ۰.۹۴۰ پیکوژول (شامل ۰.۶۲۰ پیکوژول رفت + ۰.۳۲۰ پیکوژول برای نوشتن گرادیان در پاس برگشت).
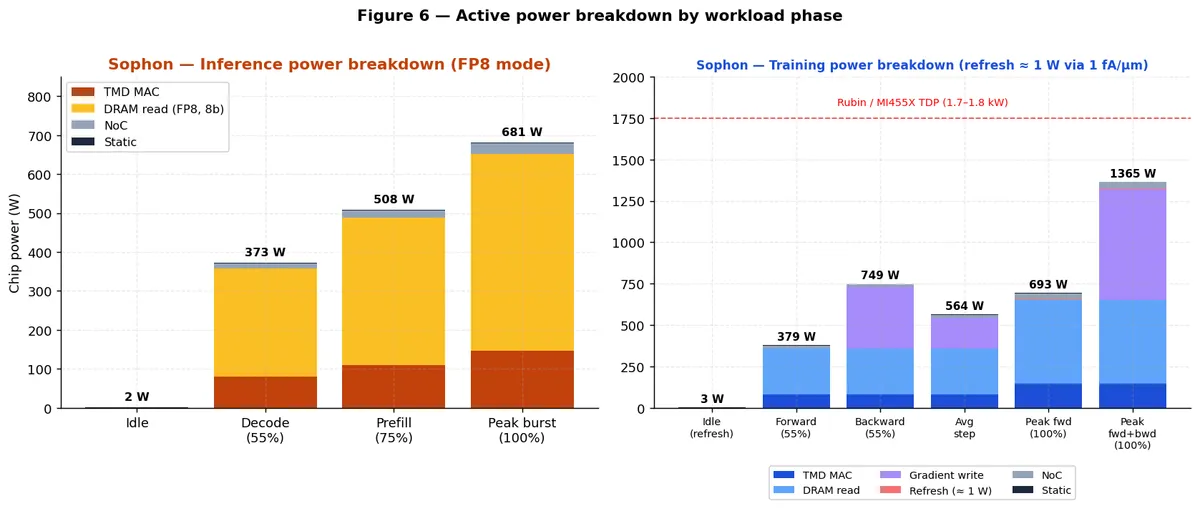
برای یک مدل استاندارد ۸۰ میلیارد پارامتری، سوفون در حالت رمزگشایی FP8 به ۳۸.۷ توکن بر ثانیه به ازای هر وات میرسد (در توان ۳۷۳ وات). این تقریباً ۱۷۴ برابر بهرهوری انرژی بیشتر نسبت به GPUهای HBM4 است، چرا که آن GPUها تنها برای نگه داشتن مدل در حالت self-refresh انرژی بسیار بیشتری مصرف میکنند (۱۰ تا ۱۵ وات در مقابل توان ۳ وات حالت idle سوفون، که در آن refresh تنها ۰.۰۸ وات هزینه دارد).
میانگین توان آموزش حدود ۵۶۴ وات است. بهطور دقیقتر، پاس رفت (Forward) حدود ۳۷۹ وات مصرف میکند و پاس برگشت (Backward) به دلیل هزینه ۳۷۰ وات ترافیک نوشتن گرادیان در بهرهوری ۵۵٪، به پیک ۷۴۹ وات میرسد. حداکثر توان پیک آموزش (۱۰۰٪ رفت و برگشت) به ۱٬۳۶۲ وات میرسد.
تحلیل مقایسهای
در یک مقایسه رودررو، PFG-1 در peak dense FLOPS پیشتاز نیست. روبین و MI455X به دلیل فرآیندهای ۳ نانومتری، ۴ تا ۵ برابر TFLOPS خام بیشتری ارائه میدهند. مقدار BF16 dense سوفون تنها حدود ۰.۲۱ تا ۰.۲۴ برابر پیک آنهاست. با این حال، مقاله سفید (Whitepaper) استدلال میکند که peak FLOPS در اندازههای دسته کوچک (B=1) بیمعنی است، جایی که گلوگاه HBM4، سرعت رمزگشایی GPUها را به حدود ۲۷۰ تا ۳۰۰ توکن بر ثانیه محدود میکند.
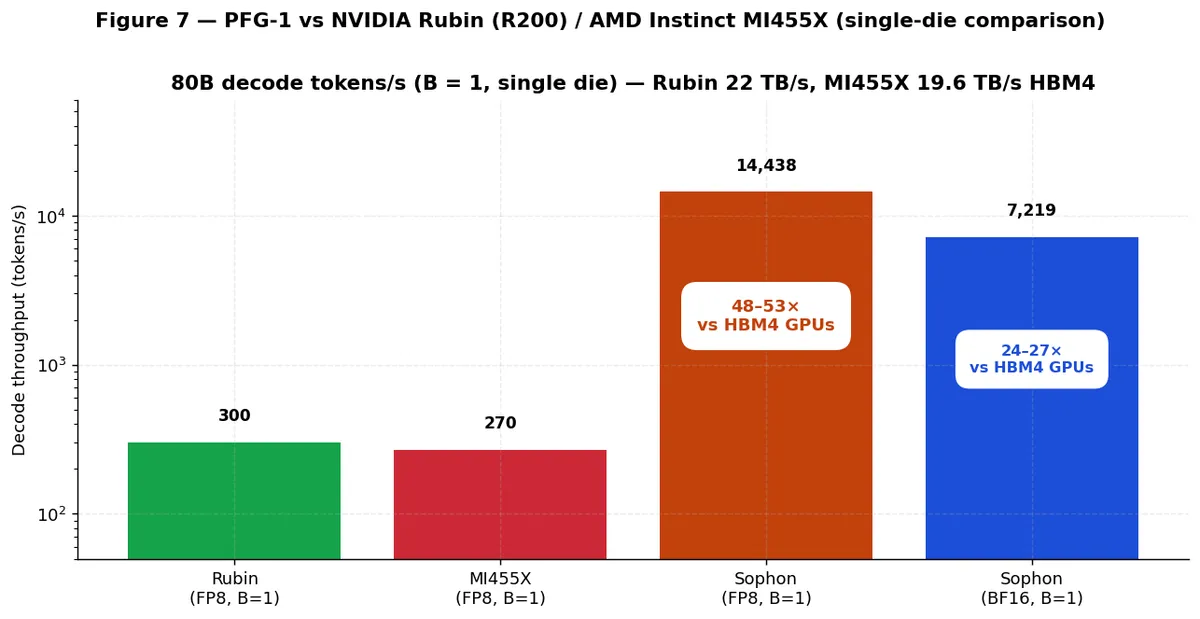
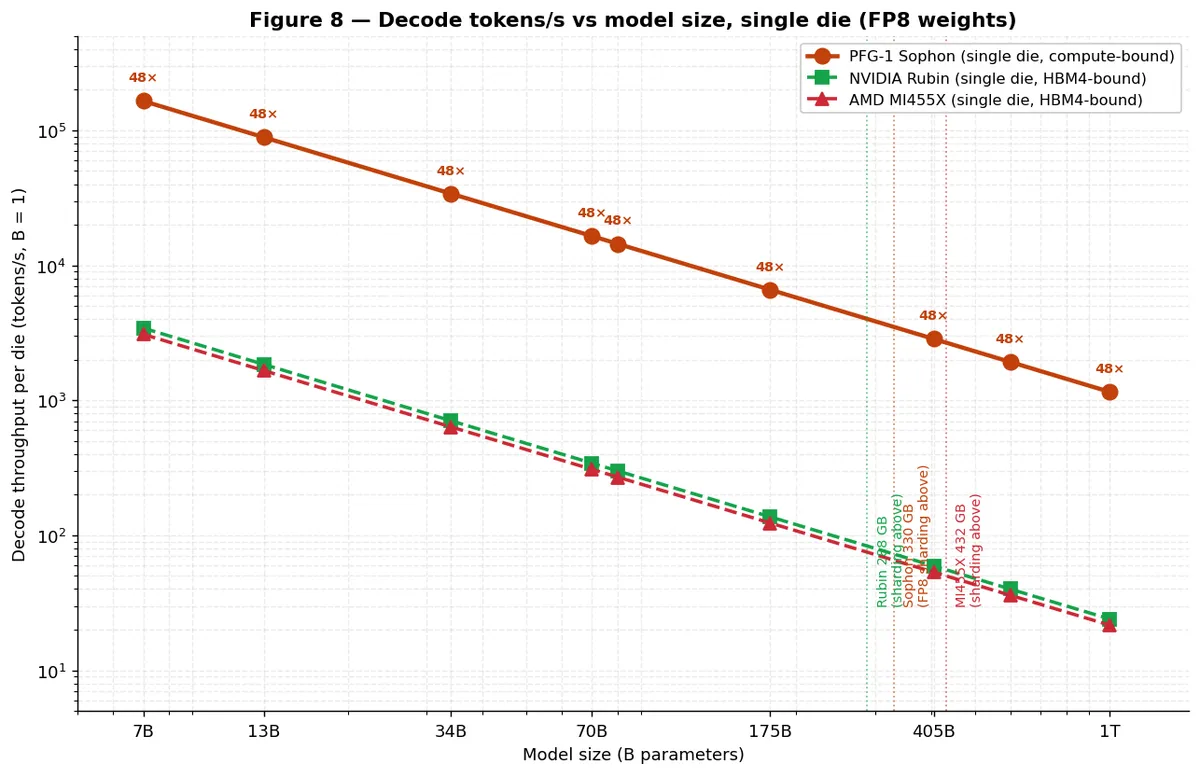
محدودیت سوفون محاسباتی (Compute-bound) است، نه پهنایباندی. این بدان معناست که عملکرد آن با اندازه مدل بهصورت خطی مقیاس مییابد (1/N). برای یک مدل ۸۰ میلیارد پارامتری FP8، سوفون به ۱۴٬۴۳۸ توکن در ثانیه میرسد (مقدار native BF16 برابر ۷٬۲۱۹ توکن بر ثانیه است) — که یک مزیت ۴۸ تا ۵۳ برابری در توان عملیاتی نسبت به جایگزینهای HBM4 است. به دلیل اینکه خواندن DRAM مدل 2T0C غیرتخریبی است، سیستم میتواند بدون نیاز به فاز «بازگردانی» (Restore) که در DRAMهای 1T1C لازم است، در هر سیکل بهطور متوالی خواندن را انجام دهد.
استراتژیهای پیشرفته توان عملیاتی
سوفون برای ارتقای بیشتر توان عملیاتی از چندین استراتژی معماری استفاده میکند:
- رمزگشایی گمانهزنانه (Speculative Decoding): اجرای یک مدل پیشنویس ۱ میلیارد پارامتری (که تنها ۱.۲۵٪ از بودجه MAC را میگیرد)، شتابی مؤثر حدود ۲.۵ برابر ایجاد میکند.
- MoE و کوانتش: ترکیب خبرهها (Mixture-of-Experts) پارامترهای فعال را ۴ تا ۵۰ برابر کاهش میدهد. ترکیب این روش با کوانتش INT4 میتواند منجر به ۵ برابر توان عملیاتی مؤثر نسبت به خط پایه FP8 dense شود.
- عملکرد مؤثر: یک مدل ۸۰ میلیارد پارامتری با استفاده از INT4 و رمزگشایی گمانهزنانه در حالت FP8 به ۷۲٬۱۸۸ توکن در ثانیه میرسد.
- انعطافپذیری مدل: مدلهای مقیاس بزرگ روی یک تکتراشه پشتیبانی میشوند؛ برای مثال، یک مدل ۳۲۰ میلیارد پارامتری INT4 (حدود ۱۶۰ گیگابایت) در ظرفیت ۳۳۰ گیگابایتی جای میگیرد.
این معماری، فرض بنیادی سختافزار AI را از «چگونه سریعتر وزنها را از حافظه به منطق منتقل کنیم» به «چگونه بهینهتر در جایی که وزنها حضور دارند محاسبه کنیم» تغییر میدهد. با حذف هزینه HBM (که مورگان استنلی آن را برای یک رک Rubin NVL72 حدود ۲ میلیون دلار تخمین میزند و ۲۵.۷٪ از هزینه رک است)، PhantaField هدفی را دنبال میکند که BOM سختافزاری آن ۱۰ تا ۱۲ برابر کمتر از پیکربندیهای فعلی GPUهای پرچمدار باشد.
برای توسعهدهندگان و اپراتورها، این به معنای توانایی اجرای مدلهای عظیم (تا ۳۲۰ میلیارد در INT4) روی یک تکتراشه با پروفایل توان idle مشابه یک دستگاه مصرفی است. تبادل (Trade-off) حیاتی، موضوع فراریت (Volatility) است؛ چون DRAM مدل 2T0C فرار است، نقاط بازرسی (Checkpoints) باید هنگام بوت از NVMe بارگذاری شوند. لایههای 2D-TMD CMOS (شامل n-FETهای MoS₂ و p-FETهای WSe₂) در دمای کمتر یا مساوی ۴۵۰ درجه سانتیگراد رشد میکنند که سازگاری BEOL و مقاومت ذاتی در برابر تابش (به دلیل نبود حجم تلههای اکسید مدفون) را تضمین میکند.
گام بعدی شما
- بررسی مقالات مربوط به مواد دو-بعدی (2D-TMD) برای درک نحوه جایگزینی سیلیسیم در حافظهها.
- مطالعه استراتژیهای رمزگشایی گمانهزنانه برای بهینهسازی سرعت استنتاج در مدلهای فعلی.
- تحلیل مقایسهای هزینههای عملیاتی (OPEX) مدلهای تک-تراشه در برابر خوشههای GPU.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو