
تصور کنید آموزش مدلهایی با کانتکست ۱۰۰ هزار توکن، دیگر به هفتهها مهندسی دستی و کرشهای مداوم حافظه ختم نشود. اگر هنوز برای مدیریت حافظه در مدلهای بلند از روشهای سنتی استفاده میکنید، باید بدانید که بازی تغییر کرده است.
در ۲۹ آوریل ۲۰۲۶، تیم پایتورچ (PyTorch) ابزار AutoSP را معرفی کرد؛ راهکاری مبتنی بر کامپایلر که در اکوسیستم DeepCompile و درون DeepSpeed ادغام شده است. به نقل از گزارش رسمی pytorch.org، این ابزار بهطور خودکار کدهای آموزشی تک-GPU را به کدهای موازیسازی توالی (Sequence Parallelism) برای چندین GPU تبدیل میکند. این یعنی محققان میتوانند طول کانتکست را افزایش دهند بدون اینکه مجبور باشند کل پشتهی سیستم خود را از نو بنویسند.
برای دستیابی به این هدف، AutoSP از سه استراتژی کلیدی استفاده میکند:
- ادغام با DeepSpeed-Ulysses: تبدیل کد به استراتژی Ulysses که سربار ارتباطی ثابتی روی شبکههای NVLink ایجاد میکند، هرچند محدود به تعداد هد (Head) مدل است.
- چکپوینتگیری فعالساز حساس به توالی (Sequence-aware Activation Checkpointing - SAC): یک روش نوین برای جلوگیری از خطاهای کمبود حافظه (OOM) که فرمولبندیهای استاندارد پایتورچ ۲.۰ معمولاً آنها را نادیده میگیرند.
- پیکربندی بدون دردسر: کاربران تنها با فعال کردن پاس «autosp» در تنظیمات DeepSpeed و استفاده از ابزار
prepare_autosp_inputبرای تگگذاری توکنها، سیستم را راهاندازی میکنند.
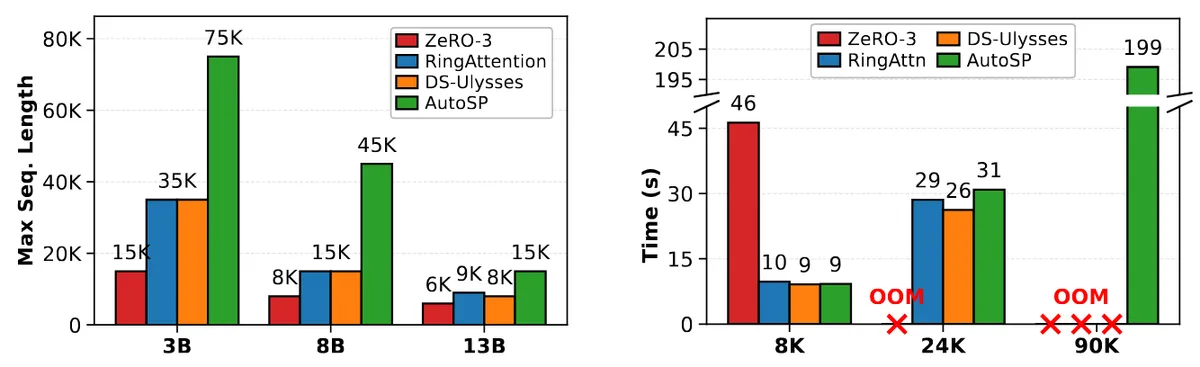
طبق گزارش بنچمارکهای انجام شده روی یک گره ۸ A100-80Gb SXM، این ابزار روی مدلهای Llama 3.1 آزمایش شد. نتایج نشان داد که AutoSP حداکثر طول توالی قابل آموزش را افزایش میدهد و در عین حال، عملکرد زمانی آن با روشهای دستنویس مانند RingFlashAttention و ZeRO-3 برابری میکند.
همانطور که در تحلیل قبلی ما دربارهی قوانین مقیاسپذیری (Scaling Laws) اشاره کردیم، مدیریت بهینه حافظه کلید دستیابی به هوش مصنوعی زاینده (Generative AI) با استدلال عمیق است. با این حال، AutoSP محدودیتهایی دارد؛ مدل باید به عنوان یک آرتیفکت واحد کامپایل شود و در حال حاضر از شکستهای گراف (Graph Breaks) پشتیبانی نمیکند، زیرا کامپایلر برای تکهتکه کردن درست توالیها، باید دید کامل به کل مدل داشته باشد.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.
گام بعدی شما
- اگر روی مدلهای با کانتکست بالای ۱۰۰ هزار توکن کار میکنید، پاس
autospرا در تنظیمات DeepSpeed فعال کنید. - مستندات
prepare_autosp_inputرا برای بهینهسازی تگگذاری توکنها مطالعه کنید. - عملکرد مدل خود را با بیسلاینهای ZeRO-3 مقایسه کنید تا میزان بهرهوری در مصرف حافظه را بسنجید.



گفتگو