
تصور کنید ترجمه حرفهای در ۳۳ زبان را بدون نیاز به حتی یک کیلوبایت اینترنت داشته باشید. اگر هنوز فکر میکنید برای دقت بالا حتماً به مدلهای ابری نیاز دارید، باید بدانید که قواعد بازی تغییر کرده است.
تنسنت (Tencent) در ۳۰ آوریل ۲۰۲۶ مدلی را عرضه کرد که ثابت میکند تعداد پارامترهای زیاد، دیگر تنها راه رسیدن به دقت نیست. به نقل از the-decoder.com، مدل Hy-MT1.5-1.8B-1.25bit با اشغال تنها ۴۴۰ مگابایت حافظه، عملکردی مشابه سرویسهای تجاری و مدل بسیار حجیمتر Qwen3-32B ارائه میدهد.
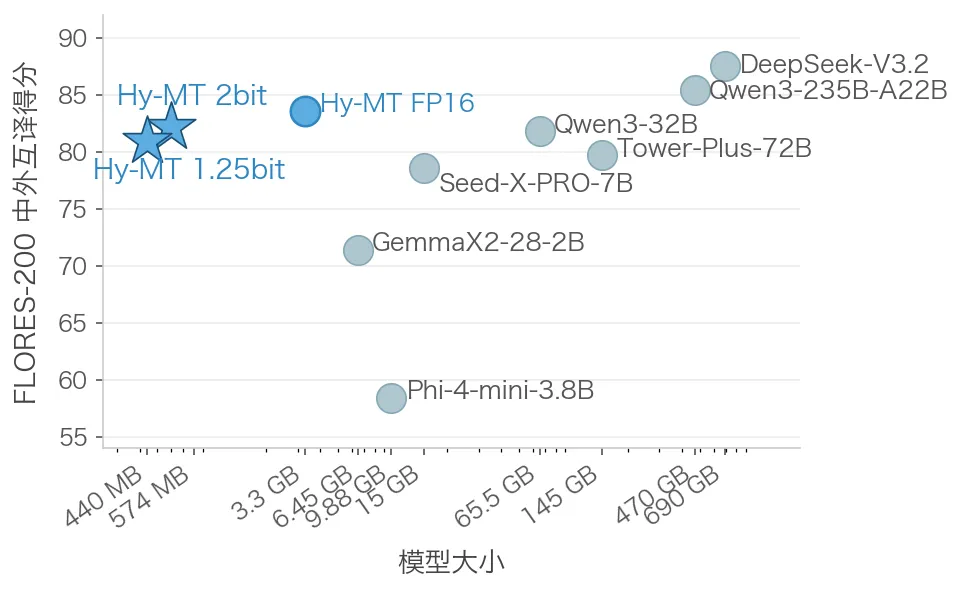
طبق اعلام تنسنت، این کارایی خیرهکننده از طریق کوانتایزیشن (Quantization) تهاجمی به دست آمده است. آنها با استفاده از ۱.۲۵ بیت برای هر پارامتر، توانستند حجم مدل را از ۳.۳ گیگابایت به ۴۴۰ مگابایت کاهش دهند. این معماری خاص، ۲۵٪ کوچکتر و ۱۰٪ سریعتر از روشهای قبلی ۱.۶۷ بیتی است، بدون اینکه کیفیت ترجمه افت کند.
ویژگیهای کلیدی این مدل عبارتند از:
- پشتیبانی از ۳۳ زبان، از جمله تبت، مغولی، آلمانی و ژاپنی.
- پوشش ۵ گویش مختلف و ۱۰۵۶ مسیر ترجمه.
- ارائه یک اپلیکیشن دمو برای اندروید (APK) جهت ترجمه آفلاین در محیطهای مختلف.
همانطور که در تحلیلهای پیشین ما دربارهی مدلهای زبانی کوچک (Small Language Models) اشاره کردیم، روند بهینهسازی برای سختافزارهای لبه در حال شتاب گرفتن است. این مدل با کسب ۳۰ مقام اول در مسابقات بینالمللی ترجمه ماشینی، اعتبار خود را ثابت کرده است.
این تحول، تنسنت را در رقابتی مستقیم با گوگل قرار میدهد که با Gemma 4 استراتژی مشابهی را در رایانش لبه (Edge Computing) دنبال میکند. اما این تنها شروع ماجراست؛ آیا این تکنیک فشردهسازی به مدلهای استدلالی پیچیده هم میرسد؟
گام بعدی شما
- نصب و تست اپلیکیشن اندرویدی (APK) برای بررسی سرعت استنتاج (Inference) در محیط واقعی.
- بررسی مقایسهای کیفیت ترجمه این مدل با Gemma 4 در حالت آفلاین.
- مطالعه مستندات تنسنت برای درک نحوه پیادهسازی کوانتایزیشن ۱.۲۵ بیتی.



گفتگو