اگر در حال استقرار مدلهای زبانی با پنجرههای متنی میلیونی هستید، متوجه شدهاید که مشکل دیگر فضای ذخیرهسازی وزنهای مدل نیست، بلکه حافظه موقتی است که با هر توکن جدید متورم میشود. این گلوگاه حافظه اکنون به میدان جنگی برای غولهایی چون گوگل، نیویورک (NYU)، Together AI و اپل تبدیل شده است تا استنتاج را از حالت «محدود به پهنای باند» خارج کنند. طبق گزارشهای پژوهشی منتشر شده تا اوایل سال ۲۰۲۶، سه استراتژی متمایز برای حل این بحران معرفی شده است.
گلوگاه حافظه KV Cache
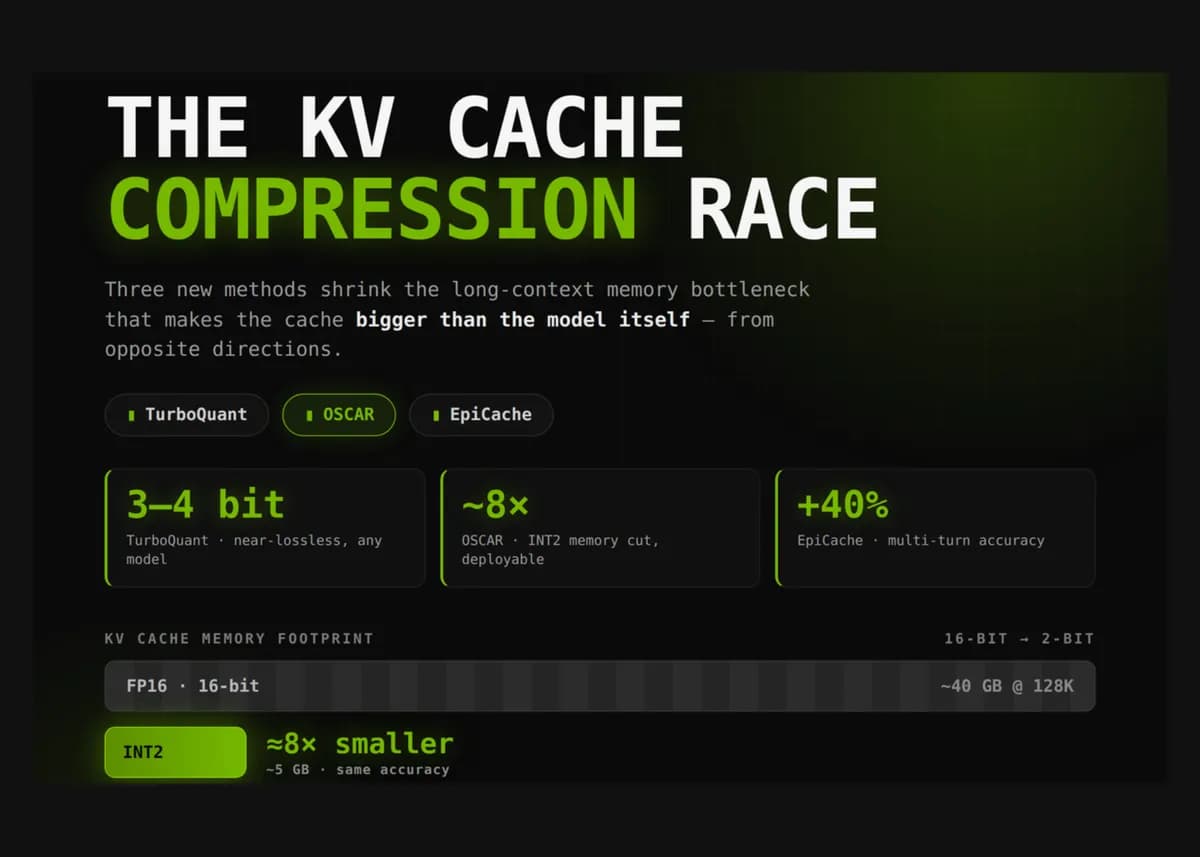
در طول فرآیند رمزگشایی (Decoding)، ترنسفورمرها برای جلوگیری از محاسبه مجدد توجه (Attention)، بردارهای کلید و مقدار (KV) را برای هر توکن در هر لایه ذخیره میکنند. این حافظه میتواند به سرعت از حجم خودِ مدل پیشی بگیرد. برای نمونه، مدل Llama-3.1-70B در حالت BF16 برای هر توکن حدود ۰.۳۱ مگابایت حافظه میطلبد (محاسبه شده بر اساس ۸۰ لایه × ۸ سر KV × ۱۲۸ بُعد سر × ۲ تنسور × ۲ بایت).
در کانتکست ۱۲۸ هزار توکنی، این مقدار به حدود ۴۰ گیگابایت میرسد و در یک میلیون توکن، از ۳۰۰ گیگابایت فراتر میرود؛ یعنی بیش از دو برابر حجم ۱۴۰ گیگابایتی مورد نیاز برای خودِ وزنهای مدل. این وضعیت باعث میشود رمزگشایی به جای «محدود به محاسبات» (Compute-bound)، به «محدود به پهنای باند حافظه» (Memory-bandwidth-bound) تبدیل شود، زیرا هر توکن جدید مستلزم استریم کردن کل حافظه کش از حافظههای با پهنای باند بالا (HBM) است. برای مقابله با این موضوع، پژوهشگران از حذف ساده توکنها فراتر رفته و به سمت کوانتیزاسیون با بیتهای بسیار پایین و مدیریت اپیزودیک حرکت میکنند.
مرزهای کوانتیزاسیون: TurboQuant و OSCAR
استراتژیهای فعلی برای کاهش KV Cache به پنج خانواده کلی تقسیم میشوند: حذف توکن (مانند H2O و SnapKV)، کوانتیزاسیون (مانند KIVI و GEAR)، تصویرسازی کم-رتبه (Palu)، ادغام (KVMerger) و اشتراکگذاری معماری (MLA).
bیشتر کوانتیزهکنندهها با «کانالهای پرت» (Outlier Channels) دست و پنجه نرم میکنند؛ تعداد کمی از کانالها با مقادیر بسیار بزرگ که محدوده کوانتیزاسیون را تسلط میکنند و سیگنالهای باقیمانده را در چند سطح قابل نمایش میفشارند. به همین دلیل، کوانتیزاسیون ساده INT2 (با چهار سطح) معمولاً منجر به سقوط شدید دقت میشود. پروژه KIVI در این زمینه یک خط مبنا ایجاد کرد و نشان داد که بردارهای کلید دارای کانالهای پرت ثابت در تمام توکنها هستند، در حالی که بردارهای مقدار چنین نیستند. KIVI با کوانتیزه کردن کلیدها به ازای هر کانال و مقادیر به ازای هر توکن، حافظه پیک کل سیستم (شامل وزنها) را حدود ۲.۶ برابر کاهش داد.
در ادامه این مسیر، TurboQuant (ارائه شده در ICLR ۲۰۲۶) رویکردی داده-ناآگاه (Data-oblivious) را اتخاذ کرده است. این متد بدون نیاز به مشاهده دادهها و از طریق یک فرآیند دو مرحلهای با پرتها مقابله میکند:
- مرحله اول: هر بردار بهصورت تصادفی چرخانده میشود تا مختصات آن تقریباً مستقل و با توزیع گاوسی شوند. این کار اجازه میدهد یک کوانتیزهکننده اسکالر پیشمحاسبه شده بهینه (Lloyd–Max) روی هر مختصه اعمال شود.
- مرحله دوم: یک تبدیل جانسون-لیندنستراس کوانتیزه شده ۱-بیتی (QJL) روی باقیماندهها اعمال میشود که تخمینی بدون سوگیری از لوگیتهای توجه را بدون هزینه ثابت نرمالسازی فراهم میکند.
ثابت شده است که اعوجاج (Distortion) در TurboQuant در یک فاکتور ثابت کوچک (حدود ۲.۷ برابر) از حد پایین نظری اطلاعات قرار دارد. به نقل از وبلاگ پژوهشی گوگل، این روش در آزمونهای Needle-in-a-Haystack با فشردهسازی ۴ برابری، بازیابی تقریباً بدون خطا (Near-lossless) را ثبت کرده است. این متد در ۳.۵ بیت خنثی است و در ۲.۵ بیت افت کیفی اندکی دارد. از آنجا که به کالیبراسیون نیاز ندارد، روی هر مدلی بدون تغییر قابل اعمال است و به عنوان یک کوانتیزهکننده سریع برای پایگاه دادههای برداری نیز عمل میکند. یک نکته مهم: ادعای «۸ برابر سرعت بیشتر در H100» مربوط به یک میکرو-بنچمارک خاص برای لوگیتهای توجه است و نه سرعت کلی سیستم.
در مقابل، OSCAR از شرکت Together AI استدلال میکند که چرخشهای داده-ناآگاه در حد شدید INT2 (چهار سطح) شکست میخورند. OSCAR از یک مرحله کالیبراسیون آفلاین یکباره استفاده میکند تا کلیدها را به پایه ویژه (Eigenbasis) کوواریانس پرسوجو و مقادیر را به کوواریانس مقدار وزندار با امتیاز منتقل کند. سپس یک تبدیل هادامارد (Hadamard) به همراه جایگشت معکوس-بیت، اهمیت کانالها را بهطور یکنواخت در گروههای کوانتیزاسیون پخش میکند.
OSCAR به عنوان یک سیستم استقرار کامل طراحی شده که شامل موارد زیر است:
- حافظه صفحهبندی شده با دقت ترکیبی: توکنهای Sink و توکنهای اخیر در حالت BF16 باقی میمانند، در حالی که تاریخچه به INT2 فشرده میشود. در کانتکست ۱۲۸ هزار توکنی، تنها ۰.۲۴٪ توکنها در BF16 میمانند.
- کرنلهای Triton ادغام شده: یکپارچگی کامل با SGLang که سازگاری با Paged-attention و Prefix-cache را تضمین میکند.
- RotationZoo: چرخشهای پیشمحاسبه شده برای مدلهای Qwen3-4B/8B/32B، GLM-4.7-FP8 و MiniMax-M2.7 که نیاز کاربر به کالیبراسیون مجدد را از بین میبرد.
در مدل Qwen3-32B، دقت موثر ۲.۲۸ بیتی OSCAR تنها ۰.۰۲ امتیاز اختلاف با BF16 دارد. در مدل GLM-4.7-FP8 — جایی که INT2 ساده شکست میخورد و روشهای داده-ناآگاه دقت بسیار پایینی دارند — OSCAR با BF16 برابری کرده یا حتی کمی از آن پیشی میگیرد. Together AI گزارش داده است که در کانتکست ۱۰۰ هزار توکنی، این روش تا ۷.۸۳ برابر افزایش توان عملیاتی (Throughput) در سطح Job و ۸ برابر کاهش حافظه KV Cache ایجاد کرده و سرعت رمزگشایی را تقریباً ۳ برابر افزایش داده است.
مدیریت حافظه چند-مرحلهای: EpiCache
در حالی که TurboQuant و OSCAR یک کانتکست طولانی واحد را بهینه میکنند، EpiCache از شرکت اپل به انباشت تاریخچه در گفتگوهای چند-مرحلهای (Multi-turn) میپردازد، جایی که تاریخچه در طول تبادلات متعدد روی هم انباشته میشود.
EpiCache سه مکانیسم اصلی برای مدیریت کش پیاده میکند:
- پیش-پر کردن بلوکی (Block-wise prefill): پردازش تاریخچه در بلوکهای مجزا برای محدود نگه داشتن پیک حافظه.
- خوشهبندی اپیزودیک (Episodic clustering): تقسیم گفتگو به «اپیزودهای» معنایی منسجم که هر کدام کش فشرده مخصوص به خود را دارند.
- بازیابی تطبیقیافته با اپیزود: هدایت هر پرسوجو به مرتبطترین اپیزود در زمان استنتاج.
- تخصیص بودجه لایهای تطبیقی: اندازهگیری حساسیت هر لایه به حذف توکن و توزیع بودجه حافظه بر اساس آن.
در بنچمارکهای LongMemEval، RealTalk و LoCoMo، سیستم EpiCache تا ۴۰٪ دقت بالاتر نسبت به متدهای حذف توکن استاندارد گزارش کرده است. این سیستم در فشردهسازی ۴ تا ۶ برابری، دقتی نزدیک به حالت کش کامل داشته و پیک حافظه را ۳.۵ برابر (و تأخیر را ۲.۴ برابر) کاهش میدهد. نکته حیاتی این است که چون EpiCache تصمیم میگیرد «کدام» توکنها نگه داشته شوند (نه اینکه «چگونه» ذخیره شوند)، میتواند با OSCAR یا TurboQuant ترکیب شود تا صرفهجویی در حافظه به صورت ترکیبی (Compounding) افزایش یابد.
تحلیل فنی: مکمل، نه رقیب
این سه رویکرد نشاندهنده تغییر به سمت یک استراتژی لایهای هستند. TurboQuant بهترین انتخاب برای فشردهسازی ۳-۴ بیتی تقریباً بدون خطا و مستقل از مدل است. OSCAR تنها مسیر عملی برای دقت INT2 در مدلهای پشتیبانی شده بدون سقوط کامل دقت است. اگرچه مقاله OSCAR ادعا میکند که TurboQuant در بودجههای مشابه ۴۰ امتیاز افت میکند، اما این ارزیابی با یک Seed تصادفی واحد و در عرض-بیت پایینتر از مقدار هدف TurboQuant انجام شده و مبنای ضعیفی برای قضاوت رودررو است.
EpiCache در یک محور کاملاً متفاوت عمل میکند و مشکل زمانیِ «انحراف گفتگو» (Conversational Drift) را حل میکند. بزرگترین فرصت فعلی در تلاقی این روشها نهفته است. ترکیب چرخشهای آگاه به کالیبراسیون OSCAR با کوانتیزهکننده اسکالر بهینه TurboQuant — ایدهای که هر دو تیم راضی به پذیرش آن بودهاند — میتواند مرزهای کارایی LLMها را بیش از هر روش تکنفرهای جابهجا کند.
توسعهدهندگان اکنون باید محدودیتهای خود را ارزیابی کنند: اگر اولویت قابلیت انتقال مدل (Portability) است، TurboQuant برنده است؛ برای حداکثر توان عملیاتی در مدلهای خاص، OSCAR پیشتاز است؛ و برای حافظه بلندمدت عاملهای هوشمند (Agentic Memory)، لایه EpiCache ضروری است.
گام بعدی شما
- اگر اولویت شما قابلیت انتقال مدل (Portability) است، از TurboQuant برای فشردهسازی ۳-۴ بیتی استفاده کنید.
- برای استقرار مدلهای Qwen یا GLM با هدف حداکثر Throughput، پیادهسازی OSCAR و کرنلهای Triton آن را بررسی کنید.
- برای توسعه عاملهایی که نیاز به یادآوری دقیق تاریخچه گفتگوهای طولانی دارند، معماری اپیزودیک EpiCache را مطالعه کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما درباره تراشههای Blackwell و مدیریت حافظه HBM مراجعه کنید.



گفتگو