
یک مدل ۳ میلیارد پارامتری اکنون میتواند در وظایف استدلالیِ قابلراستیآزمایی، با غولهای هوش مصنوعی که صدها میلیارد پارامتر دارند، رقابت کند. طبق گزارش فنی منتشر شده، مدل VibeThinker-3B که توسط پژوهشگران Sina Weibo Inc در چین توسعه یافته، در محک AIME26 به امتیاز ۹۴.۳ دست یافته است؛ نتیجهای که ادعا میشود با مدل ۶۷۱ میلیاردی DeepSeek V3.2 و مدل ۱ تریلیونی Kimi K2.5 قابل مقایسه است. این دستاورد در راستای رقابتهای اخیر است که طی آن VibeThinker-3B توانست در استدلال با مدلهای پیشرفتهای نظیر Gemini 3 Pro رقابت کند.
در حالی که صنعت هوش مصنوعی برای عبور از آستانههای شناختی، عمدتاً به دنبال افزودن میلیاردها پارامتر بوده است، این انتشار تمرکز را به سمت بهرهوری پس از آموزش (Post-training efficiency) تغییر میدهد. این مدل بر پایه Qwen2.5-Coder-3B ساخته شده و تحت مجوز متنباز MIT منتشر شده است تا روی یک حوزه خاص تمرکز کند: استدلالی که پاسخ آن را بتوان بهصورت ریاضی یا منطقی تایید کرد.
فلسفه طراحی و زمینه
مدل VibeThinker-3B یک مدل متراکم (Dense) کوچک است. نکته مهم این است که این مدل از ابتدا پیشآموزش (Pretraining) ندیده، بلکه یک مدل پسآموزشیافته است تا بسیار فراتر از وزن خود عمل کند. تیم تحقیق صراحتاً آن را یک مدل متخصص مینامد. اگرچه این مدل در زمینههای STEM، کدنویسی و ریاضی میدرخشد، اما تیم توصیه میکند برای وظایف دانش عمومی، از مدلهای بزرگتر استفاده شود.
این انتخاب طراحی نشاندهنده یک تفکیک استراتژیک بین «استدلال قابلراستیآزمایی» — جایی که یک تاییدکننده میتواند صحت پاسخ را بررسی کند — و «بازیابی دانش عمومی» است. همانطور که در تحلیلهای پیشین ما دربارهی مدلهای زبانی کوچک (SLM) اشاره کردیم، این تفکیک یک استراتژی کلیدی است. با تمرکز بر مورد اول، این مدل footprint کوچکی دارد اما عملکردی در سطح مدلهایی دارد که صدها برابر بزرگتر هستند.
خط لوله Spectrum-to-Signal
به نقل از گزارش فنی منتشر شده در arXiv، این مدل از اصل Spectrum-to-Signal (SSP) استفاده میکند که ادامه چارچوب به کار رفته در نسخه ۱.۵ میلیاردی است. این سازوکار در دو فاز اصلی عمل میکند: ابتدا تنظیم نظارتشده (SFT) فضایی گسترده از مسیرهای استدلالی معتبر را میسازد که «طیف» (Spectrum) نامیده میشود. سپس یادگیری تقویتی (RL) مسیرهای درست را تقویت کرده و آن طیف را به یک «سیگنال» (Signal) شفاف تبدیل میکند. این رویکرد یادگیری، شباهتهای ساختاری با چارچوب DiScO دارد که بر ارتقای استدلال ریاضی از طریق متنوعسازی طرحوارههای تفکر تمرکز میکند.
طبق مستندات، خط لوله پسآموزش شامل چهار مرحله مجزا است که هر کدام یک نقطه ضعف خاص در مدلهای استدلالی کوچک را هدف قرار میدهند:
- SFT دو مرحلهای مبتنی بر برنامه درسی: مرحله اول طیف وسیعی از ریاضی، کد، STEM، دیالوگ و پیروی از دستورالعملها را پوشش میدهد. مرحله دوم به نمونههای دشوارتر و با افق بلندتر (Long-horizon) میپردازد که بر اساس طول استدلال و میزان دشواری فیلتر شدهاند. در هر دو مرحله از «تقطیر اکتشاف متنوع» (Diversity-Exploring Distillation) استفاده شده است تا مسیرهای متعدد و معتبر برای رسیدن به پاسخ حفظ شوند.
- یادگیری تقویتی استدلالی چنددامنه: در این مرحله از MaxEnt-Guided Policy Optimization (MGPO) استفاده شده است. این روش پرامپتهایی را وزندهی میکند که نزدیک به مرز توانایی فعلی مدل هستند؛ یعنی جایی که خروجیهای درست و غلط همزیستاند. آموزشها بهصورت متوالی روی حوزههای ریاضی، کد و STEM اجرا شدهاند. نکته قابل توجه این است که تیم از گسترش تدریجی زمینه (progressive context expansion) صرفنظر کرد، زیرا گرمکردن با برش زیاد (High-truncation warm-up) به استدلالهای طولانی در این مقیاس آسیب میزد؛ در عوض، RL از یک پنجره زمینه (Context Window) واحد ۶۴ هزار توکنی در تمام مسیر استفاده میکند. همچنین، بخش RL ریاضی شامل یک مرحله «بلند به کوتاه» (Long2Short) است تا پاداشها را بازتوزیع کند؛ این کار باعث میشود پاسخهای درستِ کوتاهتر ترجیح داده شوند تا توکنهای زائد بدون کاهش دقت کم شوند.
- خود-تقطیر (Self-Distillation) آفلاین: در این مرحله چکپوینتهای حاصل از RL دوباره در یک مدل دانشآموز واحد ادغام میشوند تا دانش کسب شده تثبیت شود.
- RL دستوری: مرحله نهایی برای بهبود پیروی از دستورات است. این مرحله منجر به امتیاز ۹۳.۴ در IFEval و امتیاز ۷۴.۵ در IFBench شد تا اطمینان حاصل شود تنظیمات استدلالی، کنترلپذیری مدل را تخریب نکردهاند.
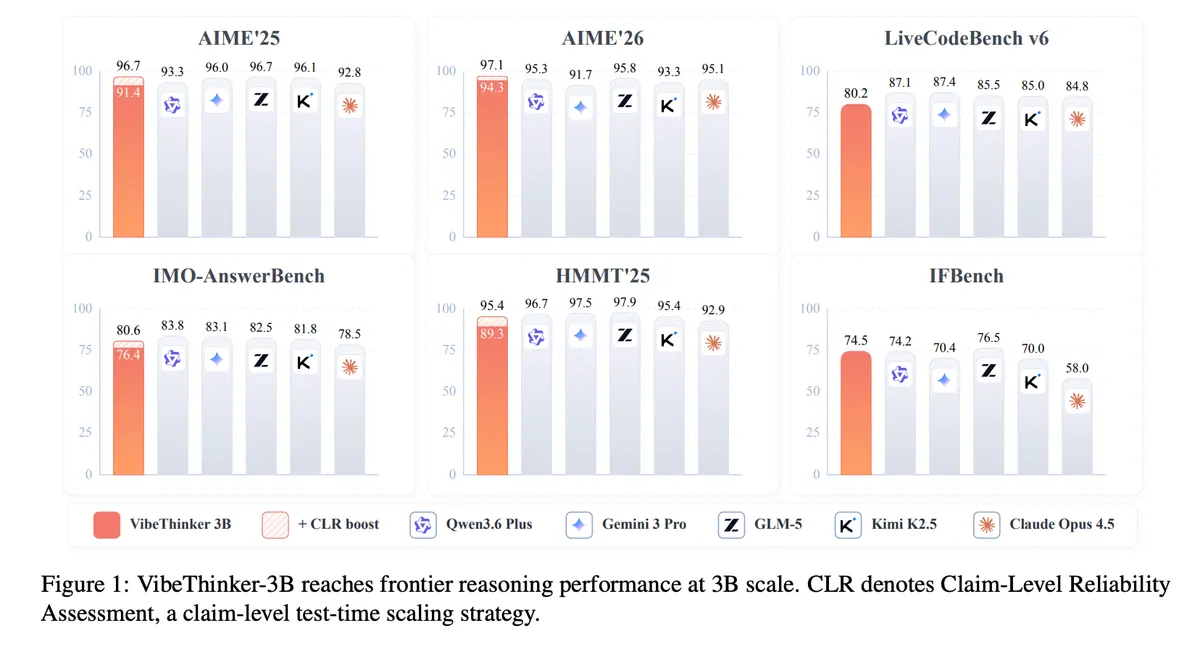
بنچمارکها و عملکرد
در وظایف قابلراستیآزمایی، این مدل بهشدت فراتر از وزن خود عمل میکند. در محک AIME26 امتیاز ۹۴.۳ و در IMO-AnswerBench (مجموعه ۴۰۰ مسئله سطح المپیاد جهانی) به ۷۶.۴ رسید. همچنین در HMMT25 امتیاز ۸۹.۳ و در BruMO25 مقدار ۹۳.۸ را ثبت کرد. در LiveCodeBench v6 به نرخ Pass@1 معادل ۸۰.۲ و در OJBench امتیاز ۳۸.۶ دست یافت.
بر اساس بررسیهای تیم روی تستهای دنیای واقعی و خارج از توزیع (Out-of-distribution) با استفاده از مسابقات هفتگی و دو-هفتگی LeetCode از ۲۵ آوریل تا ۳۱ می ۲۰۲۶، مدل توانست ۱۲۳ مورد از ۱۲۸ ارسال پایتون را در اولین تلاش پاس کند که نرخ پذیرش خیرهکننده ۹۶.۱٪ را نشان میدهد.
با این حال، شکاف عمیقی در وظایف دانش-محور دیده میشود. در محک GPQA-Diamond (GPQA-D)، مدل VibeThinker-3B امتیاز ۷۰.۲ را کسب کرد که بهشدت از غولهایی مانند GLM-5 (۸۶.۰) و Kimi K2.5 (۸۷.۶) عقبتر است. پژوهشگران صراحتاً توصیه میکنند برای وظایف دانش عمومی و باز (Open-domain) از مدلهای بزرگتر استفاده شود و VibeThinker-3B را صرفاً به عنوان یک مدل متخصص معرفی میکنند.
مقیاسپذیری در زمان تست (Test-Time Scaling) via CLR
یکی از حیاتیترین نوآوریها، ارزیابی قابلیت اطمینان در سطح ادعا (Claim-Level Reliability Assessment یا CLR) است. این یک روش مقیاسپذیری در زمان استنتاج (Inference) است که هیچ پارامتری به مدل اضافه نمیکند. فرآیند شامل دو گام است:
۱. مدل برای هر مسئله ۳۲ مسیر (Trajectory) تولید میکند (K=32). از این میان، ۵ ادعای مرتبط با تصمیمگیری (M=5) و یک پاسخ نهایی استخراج میشود.
۲. مدل بهعنوان تاییدکننده خودش عمل کرده و هر ادعا را با حکم دوتایی (درست/غلط) اعتبارسنجی میکند.
CLR این نتایج را به یک امتیاز قابلیت اطمینان غیرخطی تبدیل میکند؛ بهگونهای که وجود حتی یک ادعای ضعیف، وزن کل پاسخ را بهشدت کاهش میدهد. در نهایت پاسخها بر اساس معادل بودن خوشهبندی شده و پاسخی با بالاترین وزن قابلیت اطمینان برنده میشود. این فرآیند که ۸ بار اجرا شد تا میانگین Pass@1 به دست آید، نمره AIME26 را به ۹۷.۱ و BruMO25 را به ۹۹.۲ رساند.
استقرار فنی و موارد کاربرد
برای توسعهدهندگان، این مدل بسیار در دسترس است. وزنهای BF16 تنها به حدود ۶ گیگابایت حافظه ویدیویی (VRAM) نیاز دارند که اجازه میدهد مدل روی یک GPU مصرفی اجرا شود. این بهینه بودن در مصرف منابع، یادآور تلاشهای گوگل برای اجرای مدل Gemma 4 با کمتر از ۱ گیگابایت حافظه روی موبایل است. برای اجرا، نیاز به transformers>=4.54.0 است. برای استنتاج سریعتر، تیم توصیه میکند از vLLM (نسخه 0.10.1) یا SGLang (نسخه 0.4.9.post6 به بالا) استفاده شود.
موارد کاربرد احتمالی عبارتند از:
- آموزش ریاضیات رقابتی: حل مسائل سبک AIME و HMMT با زنجیرههای استدلالی کامل و بررسی محلیِ پاسخها.
- کمک به کدنویسی الگوریتمیک: بهرهگیری از نرخ پذیرش ۹۶.۱٪ در LeetCode برای تولید تکمرحلهای (One-shot) کدهای پایتون در دستیارهای IDE.
- بکاندهای حساس به هزینه: مسیریابی زیر-وظایف قابلراستیآزمایی به سمت یک مدل ۳ میلیاردی بهجای مدلهای ۶۰۰ میلیاردی برای کاهش شدید هزینهها.
- استدلال روی دستگاه (On-Device): استقرار در لبه (Edge) برای کاربردهایی که به یک موتور استدلالی بدون نیاز به فراخوانیهای ابری نیاز دارند.
هنگام استقرار با vLLM یا کتابخانه Transformers، تنظیم مقدار بالای max_new_tokens (مثلاً ۱۰۲۴۰۰) ضروری است. مدل ردپاهای استدلالی طولانی تولید میکند و محدودیتهای کوتاه میتوانند پاسخها را قطع کنند.
این معماری بهطور اساسی این پیشفرض را که استدلال پیچیده نیازمند مقیاس عظیم است، به چالش میکشد. با جداسازی استدلال «قابلراستیآزمایی» از «دانش عمومی»، این تحقیق ثابت میکند که مدلهای تخصصی ۳ میلیاردی میتوانند به عنوان بکاندهای ارزان و کارآمد برای عاملهای RL یا مدرسان ریاضی روی دستگاه عمل کنند.
گام بعدی شما
- اگر توسعهدهنده هستید، برای کاهش هزینههای استنتاج، زیر-وظایف ریاضی و کدنویسی خود را از مدلهای ۶۰۰ میلیاردی به این مدل ۳ میلیاردی منتقل کنید.
- برای اجرای محلی، از نسخه BF16 استفاده کنید که تنها به ۶ گیگابایت حافظه ویدیویی (VRAM) نیاز دارد و روی اکثر GPUهای مصرفی اجرا میشود.
- هنگام استقرار با vLLM، مقدار
max_new_tokensرا روی ۱۰۲۴۰۰ تنظیم کنید تا زنجیرههای استدلالی طولانی مدل قطع نشود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو