تصور کنید تیمی هستید که میخواهد قدرتمندترین مدل زبانی جهان را بسازد، اما متوجه میشوید که نبوغ برنامهنویسی شما در برابر نبودِ هزاران پردازندهی گرافیکی (GPU) هیچ است. امروز رقابت برای برتری در هوش مصنوعی دیگر در لایهی مدلها رقم نمیخورد، بلکه جنگی بر سر زیرساختهاست. در حالی که اکثر کاربران روی رابط کاربری ChatGPT، Claude، Gemini یا DeepSeek متمرکز هستند، گلوگاه واقعی در خوشههای عظیم پردازشی و شبکههای برق است که این سامانهها را زنده نگه میدارند.
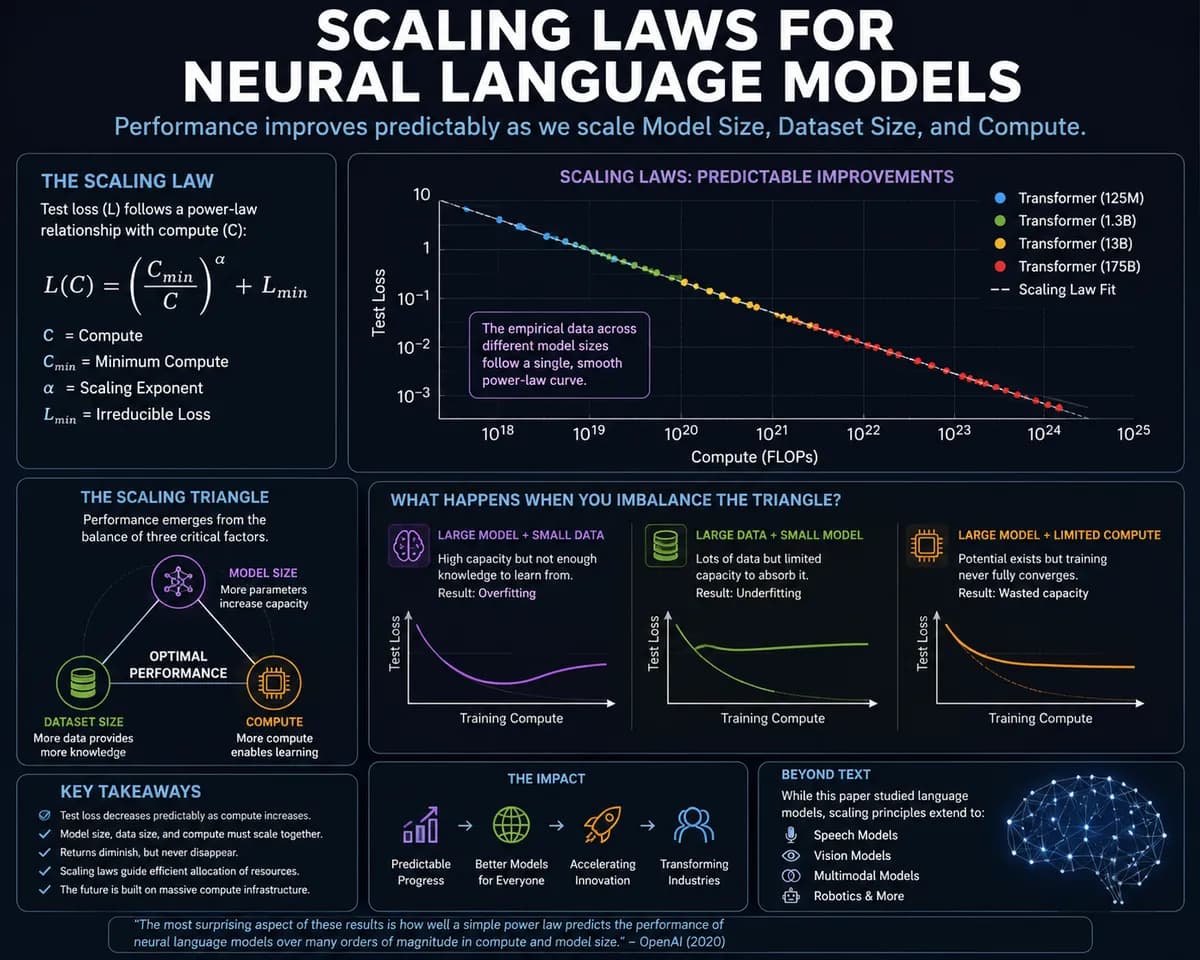
این واقعیت از ریاضیات بنیادی هوش مصنوعی نشأت میگیرد. در یک مقاله جریانساز در سال ۲۰۲۰، OpenAI «قوانین مقیاسپذیری برای مدلهای زبانی عصبی» (Scaling Laws for Neural Language Models) را ترسیم کرد. این پژوهش ثابت کرد که بهبود هوش مصنوعی تصادفی نیست، بلکه از روابط پیشبینیپذیر «قانون توان» پیروی میکند. این بدان معناست که عملکرد مدل تنها زمانی بهطور قابل اعتمادی ارتقا مییابد که سه متغیر خاص بهطور همزمان رشد کنند: اندازه مدل، حجم مجموعهدادهها و قدرت محاسباتی. در همین راستا، سم آلتمن معتقد است تردید در پذیرش این قوانین مقیاسپذیری میتوانست سرعت پیشرفت این صنعت را کاهش دهد.
درک دینامیکهای مقیاسپذیری
برای کسانی که در زمینههای هوش مصنوعی گفتار، پردازش زبان طبیعی (NLP) و زبانهای کممنبع (low-resource) فعالیت میکنند، مقاله سال ۲۰۲۰ به پرسشهای حیاتی پاسخ میدهد که چرا هوش مصنوعی در حوزههای متنوع بهطور چشمگیری بهبود مییابد. این حوزهها عبارتند از:
- تولید متن و دستیاران برنامهنویسی
- تشخیص گفتار و سنتز گفتار
- بینایی ماشین و سیستمهای چندوجهی (Multimodal)
- کاربردهای تخصصی هوش مصنوعی در دامنههای خاص
این تحقیقات روشن میکند که هوش مصنوعی صرفاً به دلیل تغییرات مهندسی یا «ترفندهای کوچک» بهتر نمیشود. در عوض، پیشرفت آن ناشی از رابطه متقابل بین پارامترها، دادهها و محاسبات است. یک مدل بزرگتر میتواند الگوهای پیچیدهتری را بیاموزد، اما این تنها در صورتی ممکن است که به دادهها و قدرت پردازشی کافی دسترسی داشته باشد تا بتواند از تمام ظرفیت خود استفاده کند.
برای درک این سازوکار، یک «مثلث مقیاس» را تصور کنید. هر گوشه بر گوشههای دیگر تأثیر میگذارد و اگر یک ضلع تبدیل به گلوگاه شود، عملکرد کلی سیستم آسیب میبیند:
- مدل بزرگ + مجموعهداده کوچک: منجر به ظرفیت بالا اما دانش کم میشود که نتیجهاش «بیشبرازش» (Overfitting) و تعمیمناپذیری مدل است.
- مجموعهداده بزرگ + مدل کوچک: منجر به دانش گسترده اما ظرفیت محدود میشود که باعث بهرهبرداری ناکارآمد از دادهها و نادیده گرفتن الگوهای پیچیده میگردد.
- مدل بزرگ + مجموعهداده بزرگ + محاسبات محدود: پتانسیل رشد وجود دارد، اما آموزش مدل هرگز بهطور کامل همگرا نمیشود و در نتیجه ظرفیت مدل هدر میرود.
ستونهای مقیاسپذیری
طبق تحقیقات OpenAI، عملکرد بهینه تنها زمانی ظاهر میشود که این سه عامل در تعادل باشند. مدلهای پیشرو مدرن دقیقاً از این نقشه راه پیروی میکنند:
- ظرفیت مدل: افزایش تعداد پارامترها اجازه میدهد تا شناسایی الگوهای پیچیدهتر ممکن شود.
- حجم داده: مجموعههای داده بزرگتر و باکیفیتتر از این جلوگیری میکنند که مدل صرفاً ورودیها را حفظ کند.
- بودجه محاسباتی: قدرت پردازشی خام مورد نیاز برای بهینهسازی میلیاردها پارامتر در میان تریلیونها توکن (Token) — که مانند برشهای کوچک یک کیک هستند و مدل متن را تکهتکه میبلعد.

امروزه این منطق در عرضه خانوادههای مدل با وزنهای باز (Open Weights) — یعنی مدلهایی که «دستور پخت» آنها علناً منتشر شده — دیده میشود. نمونههایی مثل DeepSeek-V3، خانوادهی Qwen 3، NVIDIA Nemotron، مدلهای GLM، MiniMax و مدلهای Kimi، نتیجهی یک «جادوی نرمافزاری» یا تکتغییر نیستند؛ بلکه حاصل افزایش تجمعی ظرفیت مدل، دادههای آموزشی بیشتر، بودجههای محاسباتی عظیمتر، معماریهای بهتر، بهبودهای پس از آموزش (post-training) و یادگیری تقویتشده و همسوسازی پیشرفته هستند.
ظهور کدبستهای مبهم زیرساختی
با این حال، از سال ۲۰۲۰ یک روند نگرانکننده شکل گرفته است. در نسلهای اولیه پژوهشهای هوش مصنوعی، دانستن تعداد دقیق پارامترها، حجم مجموعهدادهها، بودجه محاسباتی و روشهای آموزش امری رایج بود. امروز، این شفافیت تا حد زیادی ناپدید شده است.
سازمانهایی مانند OpenAI، Anthropic و Google DeepMind بهطور فزایندهای این جزئیات را به دلایل مالکیت معنوی و تجاری مخفی نگه میدارند. ما اکنون خروجیهای سیستمهای پیشرو را مشاهده میکنیم، بدون اینکه بدانیم چه ورودیهایی آنها را خلق کرده است. این ابهام، هزینه واقعی ورود به این رقابت را میپوشاند؛ هزینهای که اکنون شامل دهها میلیارد دلار سرمایهگذاری در سختافزار است.
پشته پنهان هوش مصنوعی
زمانی که عموم مردم با یک مدل تعامل دارند، تنها سطح رویی را میبینند. اما در زیر این رابط کاربری، یک پشته زیرساختی پیچیده و سرمایهبر نهفته است:
- سختافزار: خوشههای عظیم GPU و دسترسی به سختافزارهای پیشرو.
- شبکه: شبکههای انتقال داده با سرعت بسیار بالا و چارچوبهای آموزش توزیعشده.
- تأسیسات: مراکز داده تخصصی و سیستمهای خنککننده پیشرفته.
- انرژی: زیرساختهای برق فشار قوی و صنعتی.
- ذخیرهسازی: سیستمهای ذخیرهسازی با ظرفیت و سرعت بسیار بالا.
به همین دلیل است که میبینیم Google مراکز داده متمرکز بر هوش مصنوعی میسازد، Meta دهها میلیارد دلار روی زیرساختها سرمایهگذاری میکند، NVIDIA به یکی از ارزشمندترین شرکتهای جهان تبدیل شده و xAI با سرعت در حال ساخت خوشههای عظیم GPU است. رقابت واقعی هوش مصنوعی در این لایه زیرساختی در حال برگزاری است، جایی که گلوگاههای سختافزاری میتوانند مانع پنهانی در مسیر مقیاسبندی تولید مدلها باشند.
نقش استراتژیک هوش مصنوعی وزنباز
این سد سرمایهبر باعث میشود که مدلهای وزنباز شرکتهایی مثل Meta (Llama)، DeepSeek، Alibaba (Qwen) و Mistral AI برای عدالت جهانی بنیادی باشند. بدون آنها، بسیاری از استارتاپها، پژوهشگران و توسعهدهندگان مستقل در بازارهای نوظهور، هیچ دسترسی عملی به قابلیتهای سطح اول (state-of-the-art) نخواهند داشت.
برای مناطقی مانند آفریقا، استراتژی تغییر کرده است. هدف دیگر ساخت یک مدل پیشرو با تریلیونها پارامتر از صفر نیست — کاری که نیازمند سطوح غیرممکنی از محاسبات و سرمایههای مخاطرهپذیر در مقیاس جهانی است. در عوض، فرصت واقعی در تطبیق قابلیتهای موجود پیشرو با نیازهای محلی نهفته است.
زمینه آفریقا و چالشهای ساختاری
آفریقا دارای استعدادهای استثنایی، تنوع زبانی غنی، جمعیت زیاد و مسائل حیاتی است که ارزش حل شدن دارند. با این حال، در رقابت هوش مصنوعی با چالشهای ساختاری روبروست:
- فقدان زیرساختهای محاسباتی در مقاس بزرگ.
- دسترسی محدود به سختافزارهای پیشرو.
- بودجههای پژوهشی ناکافی.
- شکاف در سرمایهگذاریهای مخاطرهپذیر در مقایسه با رقبای جهانی.
با وجود این چالشها، ظهور هوش مصنوعی وزنباز بهطور بنیادی امکانات را تغییر داده است. پژوهشگران دیگر نیازی ندارند همه چیز را از صفر بسازند؛ آنها میتوانند بر تطبیق سیستمهای هوش مصنوعی با زبانهای محلی، فرهنگهای بومی، کسبوکارهای منطقهای، صنایع تخصصی و مودالیتههای نوظهور تمرکز کنند، بدون اینکه نیازی به میلیاردها دلار هزینه آموزش داشته باشند.
مقیاسپذیری برای زبانهای کممنبع
بهکارگیری این قوانین برای زبانهای کممنبع، مانند زبان «یوروبا» (Yorùbá)، نقشه راه جدیدی را آشکار میکند. از آنجا که معماریهای بنیادی، دستورالعملهای آموزش و مدلها از قبل وجود دارند، کمبود فعلی دیگر یک نقص فنی نیست. قطعات گمشده عبارتند از:
- مجموعهدادههای محلی با کیفیت بالا.
- محکهای ارزیابی (Benchmarks) دقیق برای گویشهای منطقهای.
- تطبیق بهینه با دامنه (Domain Adaptation) و تنظیم دقیق کارآمد.
- زیرساختهای استقرار (Deployment) قابل دسترس.
با بهرهگیری از مدلهای وزنباز، پژوهشگران میتوانند سیستمهای معناداری برای بهداشت، کشاورزی، آموزش، امور مالی، خدمات دولتی و حفظ دانش بومی بسازند، بدون اینکه به بودجههای محاسباتی یک شرکت تریلیون دلاری نیاز داشته باشند. سد ورود پایین آمده است، اما شکاف زیرساختی همچنان عامل تعیینکننده این است که چه کسی میتواند در عصر هوش مصنوعی مشارکت کند.
این تغییر، هوش مصنوعی را از یک چالش صرفاً ریاضی به یک مسئله ژئوپلیتیک و اقتصادی تبدیل میکند. سؤال دیگر این نیست که «آیا میتوانیم مدل 똑똑تری بسازیم؟»، بلکه این است که «چه کسی مالک برق و سیلیکون مورد نیاز برای اجرای آن است؟»
تطبیق عملی در میدان عمل
برای مشاهده این روند در عمل، میتوان به پژوهشهای فناوری گفتار و زبان یوروبا نگاه کرد. پروژههایی مانند Yorùbá OmniTTS از مدلهای بنیادی موجود بهره میبرند و آنها را برای زمینه زبانهای کممنبع تطبیق میدهند. این پروژهها، با استفاده از مخازن پژوهشی دانشگاهی برای ردیابی پیشرفتها، ثابت میکنند که فرصت فوری برای پژوهشگران هوش مصنوعی در آفریقا، تطبیق قابلیتهای پیشرو با مسائل محلی است.
خواندن مقاله «قوانین مقیاسپذیری برای مدلهای زبانی عصبی» کمک میکند تا بفهمیم چرا سیستمها بهطور مداوم بهبود مییابند، اما در عین حال برجسته میکند که آینده توسط سرمایه، دسترسی و اکوسیستمهای پژوهشی شکل میگیرد. سؤال این است که آیا هوش مصنوعی وزنباز میتواند سد ورود را به اندازه کافی پایین بیاورد تا هوش مصنوعی پیشرفته واقعاً جهانی شود؟
گام بعدی شما
- اگر توسعهدهنده هستید، به جای تلاش برای آموزش مدلهای بزرگ، روی استراتژیهای تولید بازیابیافزا (RAG) — مثل دانشآموزی که قبل از جواب دادن، کتاب را باز میکند — تمرکز کنید تا نیاز به محاسبات سنگین کاهش یابد.
- مدلهای وزنباز جدید مثل DeepSeek-V3 را برای تسکهای تخصصی خود آزمایش کنید تا هزینه استنتاج را بهینه کنید.
- روند سرمایهگذاریهای سختافزاری NVIDIA را دنبال کنید؛ چون چشمانداز قدرت AI در سال ۲۰۲۶ در ترازنامه این شرکت نهفته است.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو