
تصور کنید یک برنامهنویس ارشد است که همزمان چهار تیکت پیچیده را مدیریت میکند بدون اینکه هر بار برای درک موقعیت کد، زمان زیادی را تلف کند. تفاوت او با یک مدل هوش مصنوعی در میزان «هوش» نیست، بلکه در داشتن یک نقشه ذهنی از کل پروژه است. این توانایی به او اجازه میدهد بدون پرداخت «مالیات شروع سرد» (Cold-start tax)، چندین جریان کاری را بهطور موازی پیش ببرد.
به نقل از تجربات عملی یک مهندس ارشد، گلوگاه اصلی استفاده از هوش مصنوعی در محیطهای عملیاتی، نبود نقشهای از پایگاه کد (Codebase) است. اکثر توسعهدهندگان با هوش مصنوعی مانند موجودی دانای کل رفتار میکنند که میتواند معماری را از روی کدهای خام حدس بزند. در واقعیت، یک برنامهنویس خبره «گرم» وارد تیکت میشود؛ زیرا او پیش از آن میداند منطق برنامه کجاست. برای یک متخصص، تیکت ارسال میشود و پیش از آنکه حتی خواندن عنوان تیکت تمام شود، مغزش فعال میشود: او میداند کدام سرویس مالک منطق است، کدام کنترلر به متد جدیدی نیاز دارد و کدام DAO در انتهای زنجیره باید تغییر کند. این مهارت حاصل هوش خارقالعاده نیست، بلکه نتیجه داشتن نقشهای از کد در ذهن است. این چالش با موضوع مخازن کد نامنظم و تأثیر آن بر شکست عاملها که پیشتر بررسی کردیم، پیوندی مستقیم دارد.
در مقابل، یک عامل (Agent) — سیستمی که میتواند بهجای کاربر تصمیم بگیرد و ابزارها را اجرا کند — «سرد» وارد میشود. او با دیواری از فایلهای خام روبروست. او کدها را میبیند اما نقشه را ندارد. او نمیداند لایههای خاص چیست، قراردادهای نامگذاری چگونه است یا اینکه یک ویژگی تقریباً یکسان همین هفته پیش پیادهسازی شده است. تیکت یکسان و مخزن یکسان، اما یکی گرم شروع میکند و دیگری سرد. همین شکاف باعث ایجاد برنامههای «با اطمینان غلط» (Confidently wrong) میشود که عاملهای هوش مصنوعی را در پروژههای پیچیده شکست میدهد. همین موضوع باعث میشود مدلها با اعتماد به نفس کامل، مسیرهای اشتباهی برای پیادهسازی پیشنهاد دهند که در نهایت منجر به اتلاف زمان میشود.
همانطور که در تحلیلهای قبلی ما دربارهی محدودیتهای پنجره متنی اشاره کردیم، دسترسی به حجم زیادی از داده به معنای درک ساختاری از آنها نیست.
شکست در ادغام سادهلوحانه
در ابتدا، این فرآیند دستی و خستهکننده بود. برای هفتهها، جریان کاری شامل گرفتن اسکرینشات از یک تیکت جیرا (Jira)، چسباندن آن در کلود (Claude) و انتظار برای مدل بود تا میان کدها جستوجو کند و بفهمد هر چیز کجاست. در این حالت، توسعهدهنده به عنوان یک لایه ادغام دستی عمل میکرد: کپی از جیرا، پیست در کلود، انتظار و تکرار. در نهایت، این کار دیگر شبیه استفاده از هوش مصنوعی نبود، بلکه شبیه به انجام یک کار اجباری برای هوش مصنوعی بود. این چرخه چنان ابتدایی و کند بود که مشخص شد باید چیزی جایگزین این فرآیند دستی شود تا توسعهدهنده از نقش یک «منشی» برای مدل خارج شود.
برای حل این مشکل، یک جریان خودکار ساخته شد. منطق ساده بود: تیکت اختصاص مییابد، یک شاخه (Branch) بهطور خودکار برای آن بریده میشود و یک عامل، برنامه پیادهسازی را در پوشهای که مخصوص این منظور است مینویسد. تیم پوشههای اختصاصی برای برنامهها، یادداشتهای ویژگیها (Feature notes) و متریالهای مرجعی که مدام به آنها بازمیگردند، نگه میدارد. عامل تیکت را میخواند، در کد جستوجو میکند و برنامهای را مینویسد که شامل موارد زیر است:
- ماهیت دقیق تسک و هدف آن چیست.
- کدام فایلها احتمالاً تغییر خواهند کرد.
- روش پیادهسازی و گامهای اجرایی چگونه است.
- کدام بخشهای تسک هنوز مبهم هستند و نیاز به شفافسازی دارند.
سپس این برنامه به تیکت جیرا لینک میشود تا برای هر کسی که کار را برمیدارد، آماده باشد. روی کاغذ، این فرآیند دقیقاً مشابه همان فرآیند دستی قبلی بود و به نظر میرسید که اتوماسیون مشکل را حل کرده است.
اصطکاک معماری و شروعهای سرد
اما در عمل، این برنامههای خودکار فاجعهبار بودند. آنها از نظر زبان انگلیسی «بد» نبودند، بلکه بد بودند چون «با اطمینان غلط» بودند. چون عامل به کل مخزن دسترسی داشت و ابزار جستوجو در اختیارش بود، هر جای پروژه را میکاوید، روی فایلی که مرتبط به نظر میرسید متوقف میشد و کل برنامه را بر اساس آن میساخت، بدون اینکه بداند آن فایل لزوماً الگوی صحیح برای پیادهسازی نیست.
این برنامهها بهطور مداوم معماری اصلی تیم را نقض میکردند. در این پایگاه کد خاص، اعتبارسنجی (Validation) متعلق به لایه میانافزار (Middleware) است و هر فراخوانی دیتابیس باید در لایه DAO باشد و هرگز نباید در لایه سرویس قرار گیرد. در عوض، هوش مصنوعی منطق اعتبارسنجی را در کنترلر و کوئریهای دیتابیس را مستقیماً در لایه سرویس قرار میداد. این دقیقاً برعکس روش ساخت تیم بود و نشان میداد مدل هیچ درکی از «قوانین نانوشته» یا استانداردهای معماری پروژه ندارد.
چنین برنامهای یک توسعهدهنده را مستقیماً به سمت یک Pull Request (PR) رد شده میبرد. توسعهدهنده اشاره کرد که این وضعیت برای کارکنان جونیور بسیار خطرناک است: یک جونیور ممکن است به برنامه هوش مصنوعی اعتماد کند، کد را طبق توصیف آن بنویسد، PR را باز کند، در بازبینی به شدت مورد نقد قرار گیرد و گیج شود که چرا «برنامه هوش مصنوعی» او را به مسیر اشتباه فرستاده است. این موضوع باعث ایجاد سرخوردگی در نیروهای تازهوارد میشود زیرا آنها فکر میکنند طبق دستورالعمل پیش رفتهاند اما نتیجه فاجعهبار بوده است. این ریسک دقیقاً با تجربیات پروژه Loupe در زمینه شناسایی باگهای خاموش همسو است، جایی که کدهای تولید شده ممکن است در ظاهر درست به نظر برسند اما در عمل معیارهای کیفی را نقض کنند.
علاوه بر این، فرآیند کند بود. هر بار اجرا نیاز داشت که عامل تصویر خود از معماری را از هیچ بازسازی کند، چون هیچ نقطهای برای شروع نداشت. این موضوع دوباره مشکل «راهاندازی سرد» را تکرار کرد: اتوماسیون کارهای تکراری، فقدان زمینه (Context) زیربنایی را حل نکرده بود. توسعهنده کار سخت دستی را واگذار کرده بود اما تنها چیزی که نسخه دستی را ارزشمند میکرد — یعنی دانش ذاتی از شکل کد — را دور انداخته بود. مدل هر بار باید دوباره کشف میکرد که لایهها چگونه با هم تعامل دارند.
چارچوب «کارمند تازهاستخدام»
اولین واکنش توسعهدهنده، همان اشتباه رایجی بود که اکثر افراد میکنند: تصور اینکه مدل بهتر، مشکل را حل میکند. با این حال، یک مدل بهتر باز هم نمیداند که در این مخزن خاص، DAO تنها جایی است که اجازه دسترسی به دیتابیس را دارد. این دانش را نمیتوان از صفحه قیمتگذاری یک شرکت خرید؛ این موضوع مربوط به «هوش» نیست، بلکه مربوط به «زمینه» یا کانتکست است. هوش مصنوعی هر چقدر هم پیشرفته باشد، بدون دسترسی به قراردادهای داخلی تیم، نمیتواند حدس بزند که چرا تراکنشها باید در لایه خاصی مدیریت شوند.
با درک این مطلب که یک نیروی تازهاستخدام نیز در روز اول دقیقاً با همین دیوار برخورد میکند، توسعهدهنده از تلاش برای «باهوشتر کردن» عامل دست کشید و در عوض شروع به «آنبوردینگ» (Onboarding) آن کرد. از آنجایی که نیروهای جدید «مغز بزرگتر» دریافت نمیکنند بلکه مستندات و قراردادها را میگیرند، یک سیستم آنبوردینگ سهلایه پیادهسازی شد. این سیستم اجازه میدهد مدل بدون اینکه تمام مستندات را در هر بار پردازش کند، به طور هدفمند اطلاعات را دریافت کند:
۱. نقطه ورود (Entry Point): لایهای نازک شامل مبانی پروژه و اشارهگرها. این اشارهگرها به عامل میگویند: «برای این نوع کار، برو فلان مستند عمیق را بخوان» و او را به سمت مستندات تخصصی هدایت میکنند تا مدل در انبوه فایلها گم نشود.
۲. سند قراردادهای اصلی (Core Conventions Doc): جایی که معماری بهطور صریح و تخت تعریف شده است. در اینجا صراحتاً ذکر شده که کنترلرها سرویسها را صدا میزنند، سرویسها DAOها را صدا میزنند و DAOها مالک دیتابیس هستند. همچنین اعتبارسنجی در میانافزار اجباری شده، قوانین نامگذاری تعیین شده و الگوهایی که تیم نباید بشکند، لیست شدهاند تا هیچ ابهامی برای مدل باقی نماند.
۳. فایلهای دانش تخصصی: مستنداتی دامنه-محور (Domain-specific) که عامل فقط در صورت نیاز واقعی باز میکند. این کار مانع از آن میشود که مدل در هر بار اجرا، دادههای نامرتبط را بخواند و پنجره متنیاش را با اطلاعات غیرضروری پر کند. این فایلها شامل موارد زیر هستند:
* دستورالعملهای کارهای دیتابیس در حالت On-call برای مدیریت بحرانها.
* مستندات دقیق مدل دادهها (Data Model) برای درک روابط جداول.
* منطق و الگوهای ترجمه برای مدیریت زبانهای مختلف.
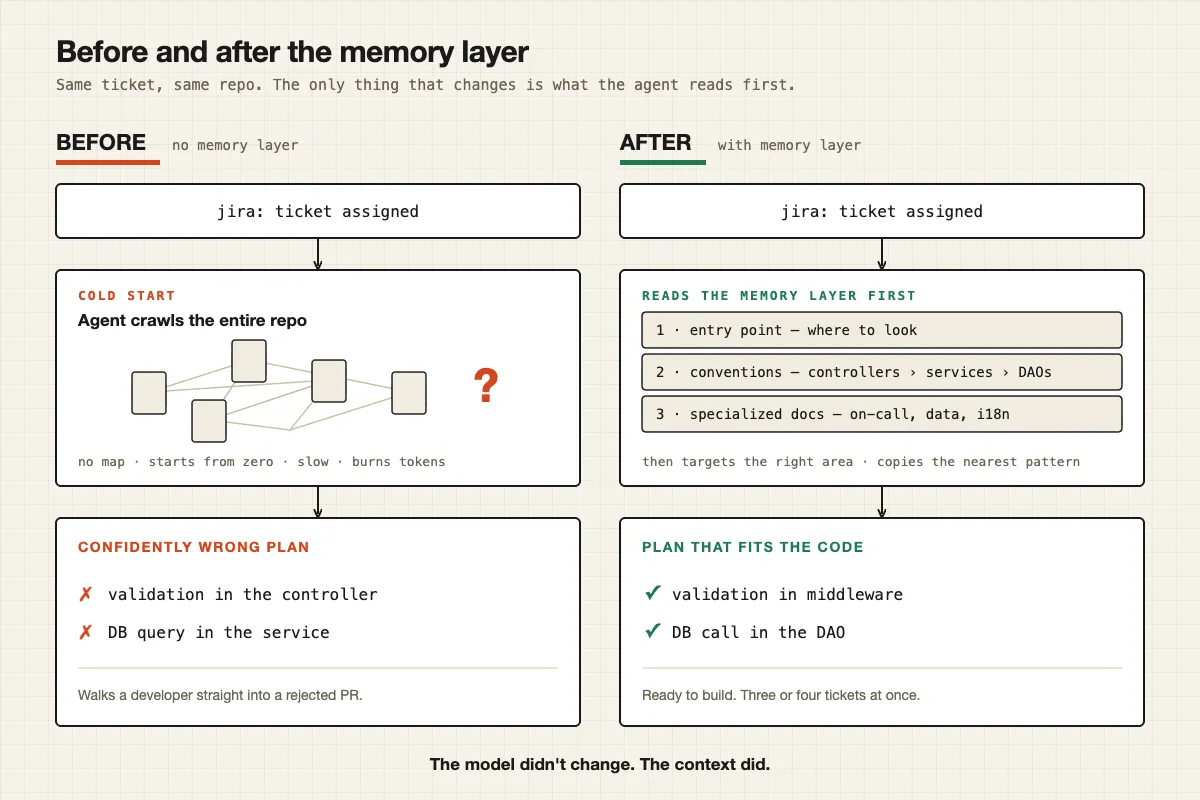
دستورات عامل بازنویسی شد تا توالی سختگیرانهای را طی کند: پیش از هر جستوجویی، باید نقطه ورود و سند اصلی را بخواند تا جهتگیری کلی از ساختار پیدا کند. او نباید مستقیماً به سراغ کد برود. تنها پس از آن است که میتواند به سراغ بخش خاصی که تیکت به آن مربوط است برود. این توالی تضمین میکند که مدل ابتدا «قوانین بازی» را میبیند و سپس سعی میکند آنها را در کد پیاده کند.
اثرگذارترین دستور، سادهترین آنها بود: «نزدیکترین پیادهسازی موجود را پیدا کن و الگوی آن را کپی کن». این دقیقاً همان جملهای است که یک مهندس ارشد به یک جونیور در روز اول میگوید. دستور این است که روش جدید ابداع نکند، بلکه چیزی را که قبلاً ساخته شده و نزدیک به هدف است پیدا کرده و از آن پیروی کند. این کار باعث میشود کد تولید شده با بقیه پروژه همراستا (Consistent) باشد و از تغییرات ساختاری غیرضروری جلوگیری شود.
بستن حلقه بازخورد و پوسیدگی حافظه
پس از اجرای این سیستم، کیفیت برنامهها تقریباً بلافاصله تغییر کرد. اعتبارسنجی در میانافزار ظاهر شد و کوئریها به لایه DAO بازگشتند. مدل بین سهشنبه و چهارشنبه باهوشتر نشده بود؛ بلکه توسعهدهنده صرفاً قوانینی را که در ذهنش داشت مکتوب کرد و هوش مصنوعی را مجبور کرد ابتدا آنها را بخواند. این نشان داد که مشکل هرگز قدرت پردازش مدل نبوده، بلکه فقدان دسترسی به استانداردهای تیم بوده است.
برای جلوگیری از «پوسیدگی مستندات» (Documentation Rot)، تیم نگهداری از مستندات را در جریان کاری گنجاند. لایه حافظهای که یک بار نوشته شود و فراموش شود، با تغییر کد و تغییر قراردادها بهسرعت میپوساند. اگر مستندات قدیمی شوند، عامل قوانینی را دنبال میکند که ماهها پیش دیگر درست نبودهاند و دوباره به تولید کدهای اشتباه منجر میشود. برای مقابله با این موضوع، بهروزرسانی حافظه — هرگاه عامل چیز جدیدی بیاموزد یا یک ویژگی تغییر کند — به جای یک اقدام جانبی، به بخشی اجباری از شغل تبدیل شد. این یعنی هر بار که یک PR ادغام میشود، اگر تغییری در قراردادها رخ داده باشد، مستندات متناظر نیز باید آپدیت شوند. این تضمین میکند که مدل ذهنی عامل همزمان با بهروزرسانی مستندات مخزن، آپدیت شود، درست مانند زمانی که مدل ذهنی یک انسان در حین کار بهروز میشود.
گفتگوی اجباری در مورد طراحی
زمانی که برنامهها قابل اعتماد شدند، یک مزیت غیرمنتظره ظاهر شد: عامل شروع به استدلال و بحث کرد. توسعهدهنده مرحلهای را اضافه کرد که در آن عامل، برنامه خودش را «به چالش میکشد» (Grill)، یعنی منطق را همانطور که یک مهندس ارشد در یک جلسه بازبینی طراحی (Design Review) انجام میدهد، بازبینی میکند. در این مرحله، عامل نقش یک منتقد سختگیر را بازی میکند و سعی میکند حفرههای برنامه را پیدا کند. اکنون عامل موارد زیر را شناسایی میکند:
- کجا در نیازمندیها ابهام وجود دارد و چه بخشهایی از تیکت جیرا نیاز به توضیح بیشتر دارد.
- کدام لبههای فراموششده (Edge cases) در برنامه غایب هستند و ممکن است باعث کرش کردن سیستم شوند.
- کدام پیشفرضها نیاز به پاسخ واقعی دارند پیش از آنکه حتی یک خط کد نوشته شود تا از بازنویسی مجدد جلوگیری شود.
عامل این سوالات را همراه با یک پاسخ پیشنهادی برای هر مورد مینویسد. نکته حیاتی این است که او اکنون «خط قرمز» را نگه میدارد. وقتی توسعهدهنده میخواهد تیکت را بسازد، عامل از نوشتن کد خودداری میکند تا زمانی که آن سوالات پاسخ داده شوند، حتی اگر به او گفته شود که «فقط ادامه بده و کد بزن». این لجاجت سازنده، توسعهدهنده را مجبور میکند به جنبههایی فکر کند که شاید در شلوغی کار فراموش کرده بود.
این تغییر، ارزش را از «پاسخ» به «سوالات» منتقل میکند. این کار گفتگوی حیاتی طراحی را به ابتدای فرآیند میکشد؛ گفتگویی که توسعهدهنده معمولاً از آن عبور میکند و بعداً بهای آن را در قالب یک ویژگی نیمهکاره و یک PR زشت میپردازد. خروجی از «یک برنامه» به «یک گفتگوی طراحی اجباری پیش از وجود حتی یک خط کد» تکامل یافت، که منجر به کاهش چشمگیر تعداد اصلاحات در مرحله بازبینی کد شد.
چسب تولیدی و QA
این سیستم فراتر از کدنویسی و به شکاف استقرار (Deployment) گسترش یافت. یک تیکت بهندرت در اولین تلاش بهطور پاکیزه ارسال میشود؛ معمولاً ارسال میشود، QA مشکلی پیدا میکند، تیکت باز میگرداند، وصله میزند و دوباره ارسال میشود. بعد از چندین دور از این چرخه، هیچکس دقیقاً مطمئن نیست چه چیزی واقعاً ارسال شده است و چه بخشی از کد در محیط تست است و چه بخشی در محیط عملیاتی.
تیم QA اغلب تیکتی باز میکند اما نمیتواند تشخیص دهد کدام موارد در یک ریلیز خاص هندل شدهاند و کدامها هنوز باز هستند. این منجر به ناکارآمدی میشود؛ یا QA مجبور است کل ویژگی را دوباره تست کند یا بخش اشتباهی را تست کرده و تغییر واقعی را از دست بدهد. برای حل این مشکل، اکنون یک عامل میخواند چه چیزی در یک Deploy بوده است (با بررسی کامیتها و لاگهای استقرار) و خلاصهای را روی تیکتهای affected میگذارد که شامل موارد زیر است:
- دقیقاً چه چیزی ship شده است و کدام ورژن کد اکنون فعال است.
- کدام موارد از تیکت اکنون تکمیل شدهاند و تست شدهاند.
- کدام موارد هنوز تمام نشدهاند و باید در ریلیز بعدی باشند.
این کار به عنوان «چسبی» عمل میکند که منبع تکراری سردرگمی را از بین میبرد و نیاز به خلاصههای دستی در هر ریلیز را حذف میکند. موضوع دیگر نوشتن کد توسط AI نیست، بلکه قرار گرفتن AI در شکافهای بین تیکت، پایگاه کد، استقرار و تست QA است تا کانتکستی را حمل کند که قبلاً توسعهدهنده بهطور دستی حمل میکرد. این باعث شد تا ارتباط بین تیم توسعه و تیم تست بسیار شفافتر شود.
تأثیرات واقعی و محدودیتها
این یک دموی استاتیک نیست، بلکه یک جریان کاری زنده است. تغییر اصلی در سرعت توسعه (Velocity) است. با حذف «مالیات شروع سرد» — یعنی زمانی که صرف فکر کردن به اینکه تیکت چیست، کجا قرار دارد و چگونه باید انجام شود میشد — توسعهدهنده اکنون میتواند همزمان سه یا چهار تیکت را پیش ببرد. پیش از این، بار شناختی (Cognitive load) مربوط به یادآوری معماری هر تیکت، او را به یک تیکت در هر لحظه محدود میکرد، زیرا جابجویی بین تیکتها نیاز به زمان برای «گرم شدن» دوباره داشت.
با این حال، سیستم مرزهای مشخص و چند لبه زبر و زمخت دارد که نشان میدهد هوش مصنوعی هنوز کامل نیست:
- تیکتهای کوچک: برای کارهای جزئی مانند تغییر یک متن ساده یا اصلاح یک غلط املایی، توسعهدهنده برنامه را نادیده میگیرد و مستقیماً کار را انجام میدهد. رد کردن هر تیکت ریز از این خط لوله، خودش نوعی اتلاف وقت است زیرا زمان تولید برنامه بیشتر از زمان اجرای کد است.
- اختلالات فنی: سیستم در ابتدا از توکنی استفاده میکرد که منقضی میشد و کل فرآیند را متوقف میکرد تا زمانی که یک Secret دستی دوباره وارد شود. این مشکل با سوئیچ به یک کلید (Key) مناسب و مدیریتشده حل شد تا جریان اتوماسیون قطع نشود.
- محدودیتهای جستوجو: عامل فایلها را عمدتاً بر اساس نام پیدا میکند. این برای کوئریهای خاص مانند «addInvoice کجاست» موثر است اما برای کوئریهای مفهومی مانند «پرداختهای آفلاین را کجا مدیریت میکنیم» بیفایده است، زیرا ممکن است نام فایلها به این مفهوم اشاره نکند. یک گام جستوجوی هوشمندتر (مانند Vector Search یا Semantic Search)، حرکت منطقی بعدی است.
- شکاف متریک: موفقیت در حال حاضر یک «حس» است نه یک عدد. توسعهدهنده اشاره میکند که به یک متریک کمی نیاز دارد تا بتواند دقت سیستم را اندازه بگیرد؛ مثلاً مقایسه فایلهایی که یک PR ادغامشده واقعاً تغییر داده است در مقابل فایلهایی که برنامه پیشبینی کرده بود تغییر کنند تا نرخ خطای پیشبینی سنجیده شود.
نتیجهگیری
مدل هرگز گلوگاه نبود؛ زمینه (Context) گلوگاه بود. بهبود خروجی نیازی به مدل بزرگتر نداشت، بلکه نیازی به مستند کردن چیزهایی داشت که یک انسان به نیروی تازهاستخدام میگوید: اعتبارسنجی کجا میرود، فراخوانیهای دیتابیس کجا قرار دارند و دستور کپی کردن الگوهای موجود. با مجبور کردن عامل به خواندن این یادداشتها و زنده نگه داشتن آنها همزمان با تکامل کد، راهکار «خستهکننده» و ساختاری بر راهکار «هیجانانگیز» (مثل ارتقای مدل) پیروز شد.
وقتی هوش مصنوعی «گرم» شروع به کار کند، برنامه دیگر هدف نیست؛ هدف، کانتکست بارگذاری شدهای است که بهرهوری موازی واقعی را ممکن میسازد. برای کسانی که این سیستم را در جای دیگر پیاده میکنند، توصیه این است: با مدل شروع نکنید. با زمینهای شروع کنید که مغز شما بدون درخواست بارگذاری میکند — چیزهایی که هرگز نیاز نبود بنویسید چون از قبل میدانستید و برایتان بدیهی بود. این همان بخشی است که هوش مصنوعی گم کرده است. بقیه چیزها فقط لولهکشی (Plumbing) است.
گام بعدی شما
- بهجای تکیه بر مدلهای گرانتر، یک فایل
conventions.mdبرای پروژه خود بسازید و قوانین معماری را صریح بنویسید. - پرامپتی طراحی کنید که مدل را مجبور کند قبل از کدنویسی، «الگوی نزدیکترین پیادهسازی موجود» را در پروژه پیدا کند تا از اختلال در یکپارچگی کد جلوگیری شود.
- مرحله «نقد برنامه» (Self-Critique) را به جریان کاری عاملهای خود اضافه کنید تا ابهامات طراحی قبل از پیادهسازی مشخص شوند و از بازنویسی کدها در مراحل نهایی جلوگیری شود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو