تصور کنید داشبورد مدیریتی شما نرخ موفقیت ۹۰ درصدی را برای یک عامل هوش مصنوعی نشان میدهد، اما در واقعیت، کاربران از قطع شدن مداوم سرویس شاکیاند. این شکاف نتیجهای از «سوگیری بقا» (Survivorship Bias) است؛ جایی که معیارهای قابلیت اطمینان، هر اجرای عملیاتی را که هرگز به پایان نرسیده، از محاسبات حذف میکنند. به نقل از تحلیل فنی الکسئی اسپینوف (Aleksei Spinov)، این خطا زمانی رخ میدهد که داشبوردها تنها اجراهایی را میشمارند که وضعیت نهایی آنها «موفق» (Pass) یا «شکستخورده» (Fail) ثبت شده است. وقتی پیروزیها فقط بر اساس این اجراهای تکمیلشده تقسیم شوند، موارد «تایم-اوت» (Timed-out)، متوقفشده (Aborted) و معلق (Hung) بهطور کامل از مخرج کسر حذف میشوند. در نتیجه، هرچه تعداد اجراهای ناپدیدشده بیشتر شود، نرخ موفقیت جذابتر و فریبندهتر به نظر میرسد.
برای درک این سازوکار، بازگشت به یک تجربه تاریخی در سال ۱۹۴۳ میلادی کمک میکند. ارتش آمریکا با بررسی هواپیماهای بازگشته از ماموریتهای اروپا، نقاط آسیبدیده در بالها، بدنه و دم را شناسایی کرد و تصمیم گرفت آن نقاط را زرهپوش کند. اما آبراهام والد، یک آمارشناس در گروه تحقیقات آماری، استدلالی متضاد آورد: باید موتورها را زرهپوش کرد؛ چون دقیقاً همان جایی است که در هواپیماهای بازگشته تقریباً هیچ سوراخی دیده نمیشد. دلیلش ساده بود: هواپیماهایی که موتورشان هدف قرار گرفته بود، هرگز به خانه بازنگشتند تا اندازهگیری شوند. در واقع، آسیبی که نمیبینید، همان آسیبی است که باعث مرگ میشود. در لاگهای عامل (Agent) — سیستمهای هوشمندی که میتوانند بهطور مستقل ابزارها را برای رسیدن به یک هدف به کار بگیرند — دقیقاً همین اتفاق میافتد. اگر یک اجرا بهطور نامحدود معلق بماند یا توسط سیستم کشته شود، هرگز «شکست» گزارش نمیکند؛ بلکه صرفاً از ریاضیاتِ داشبورد محو میشود.
همانطور که در تحلیلهای پیشین ما دربارهی پایداری زیرساختهای مدلهای زبانی اشاره کردیم، تفاوت میان «خروجی درست» و «سیستم پایدار» در همین جزئیات نهفته است. این عدم پایداری در مقیاس عملیاتی میتواند منجر به نتایج فاجعهباری شود، مشابه آنچه در شکست ۹۰ درصدی پروژههای هوش مصنوعی سازمانی به دلیل رکود در فرآیندهای کسبوکار مشاهده شد.
تلهی مخرج کسر
بیشتر توسعهدهندگان نرخ موفقیت را با فرمول سادهای محاسبه میکنند: تعداد موفقها تقسیم بر مجموع موفقها و شکستها. این رویکرد، چرخه حیات یک عامل را به یک خروجی دوتایی (Binary) تقلیل میدهد، اما اجرای واقعی در محیط تولید بسیار پیچیدهتر است. مشکل اصلی در بخش «به اضافهی شکستها» نهفته است، چرا که این بخش کل مخرج کسر را تشکیل میدهد. شما در واقع پیروزیها را فقط بر تعداد اجراهایی تقسیم میکنید که با یک «بله» یا «نه» صریح بازگشتهاند.
در واقعیت، بسیاری از اجراها هرگز حکمی صادر نمیکنند. به عنوان مثال، یک کارگر (Worker) در حین یک عملیات استخراج طولانی ممکن است در ردیف ۹۰۰۰ام از شبکه قطع شود و هرگز گزارشی نفرستد. یا ممکن است یک اجرا به دلیل رسیدن به محدودیت زمانی ساعت-دیوار (Wall-clock limit) توسط پلتفرم به عنوان TIMED_OUT علامتگذاری شود. حتی ممکن است کسی یک شغل گیر کرده را بهصورت دستی بکشد (Kill). بدترین حالت، اجرای معلقی است که هیچ کد خروجی، هیچ وضعیت نهایی و هیچ خط لاگی پس از یک زمان مشخص (مثلاً ساعت ۱۴:۰۲) ندارد. این اجراها برای روزها در وضعیت RUNNING باقی میمانند، چون هیچ چیزی پایان آنها را ننوشته است.
اسپینوف بر اساس مستندات پلتفرم Apify — که برای رصد ۲۱۹۰ اجرای عملیاتی در ۳۲ اکتور مختلف از آن استفاده کرده — سه دسته وضعیت را تعریف میکند:
- اولیه (Initial): وضعیتهایی مثل READY، زمانی که اجرا شروع شده اما هنوز به هیچ کارگری (Worker) تخصی and-allocate نشده است.
- انتقالی (Transitional): وضعیتهایی مثل RUNNING، TIMING-OUT یا ABORTING که اجرا در حال حاضر در جریان است.
- نهایی (Terminal): وضعیتهای پایانی شامل SUCCEEDED، FAILED، TIMED_OUT و ABORTED که نشاندهنده پایان کار است.
طبق مستندات Apify، یک اجرا در حالت اولیه شروع شده، از یک یا چند فاز انتقالی میگذرد و در یکی از حالات نهایی به پایان میرسد. این کل چرخه حیات است. یک نرخ موفقیت ساده، تمام اجراهای انتقالی و برخی نهاییها را حذف میکند. با نادیده گرفتن وضعیتهای TIMED_OUT و ABORTED و RUNNINGهای گیر کرده، مخرج کسر کوچک شده و درصد موفقیت بهطور مصنوعی بالا میرود. این یعنی سیستم دقیقاً همان حالتهای شکست را پاداش میدهد که برای پایداری تولید خطرناکترین هستند.
این موضوع بهویژه برای وظایف طولانیمدت بحرانی است. اسپینوف اشاره میکند که اسکرپرهای بررسی نظرات Trustpilot به تنهایی ۹۶۲ اجرا در جدول خود دارند. اجراهای طولانی — همانهایی که یک ساعت در حال پردازش هستند — دقیقاً همانهایی هستند که با سقف حافظه و تایم-اوت بازی میکنند. این موارد بیشترین احتمال را دارند که به TIMED_OUT ختم شوند یا در یک وضعیت انتقالی گیر کنند. در نتیجه، نرخهای ساده دقیقاً همان اجراهایی را حذف میکنند که زنده نگه داشتنشان سختترین بوده است. متریک دقیقاً در جایی که حجم کار سختترین است، کور میشود.

ریاضیات شکستهای نامرئی
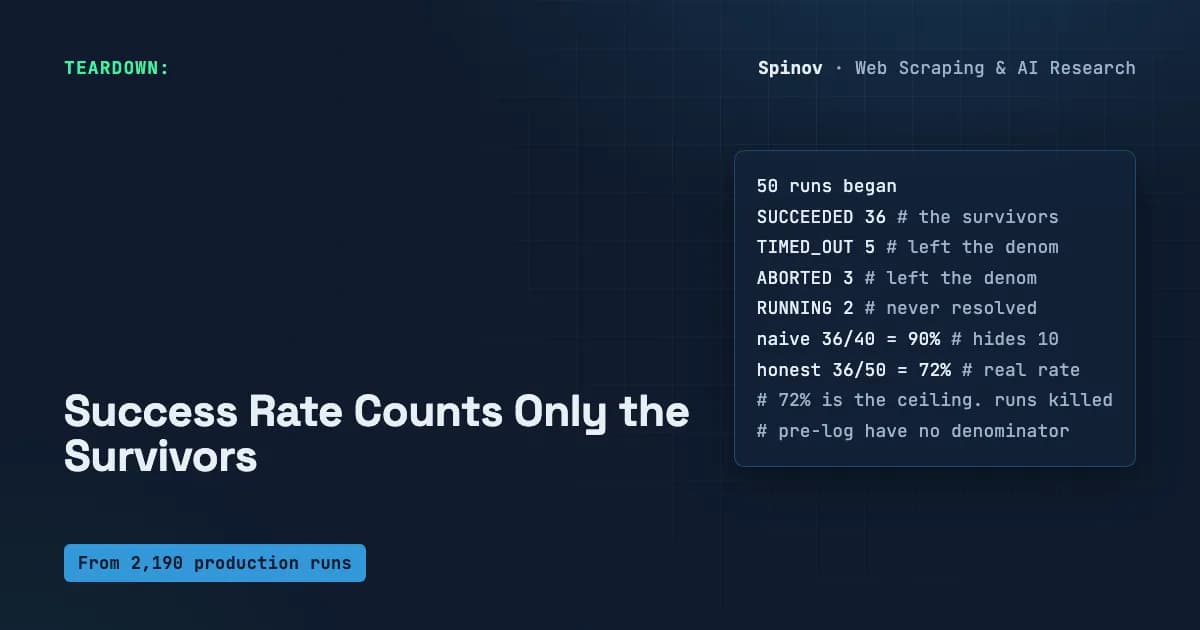
برای روشن شدن این مکانیزم، اسپینوف یک دفتر کل مصنوعی (Synthetic Ledger) شامل ۵۰ اجرای آزمایشی ارائه میدهد تا اثر ریاضی را ایزوله کند. این دفتر کل بهصورت دستی ساخته شده تا مکانیسم را نشان دهد، نه اینکه عملکرد یک اکتور خاص را بسنجد. در این سناریو دادهها چنین است:
- موفق (SUCCEEDED): ۳۶ مورد (نهایی)
- شکستخورده (FAILED): ۴ مورد (نهایی)
- تایم-اوت (TIMED_OUT): ۵ مورد (نهایی)
- متوقفشده (ABORTED): ۳ مورد (نهایی)
- در حال اجرا (RUNNING): ۲ مورد (انتقالی - هرگز حل نشد)
بسته به اینکه از کدام مخرج استفاده شود، نرخ موفقیت با وجود ثابت ماندن تعداد موفقها (۳۶ مورد)، بهشدت تغییر میکند:
- نرخ ساده (موفق / موفق + شکست): ۳۶ تقسیم بر ۴۰ = ۹۰.۰٪. این عددی است که اکثر داشبوردها در صفحه نمایش بزرگ قرار میدهند. این عدد ۱۰ مورد (۵ تایم-اوت، ۳ متوقفشده، ۲ حلنشده) را پنهان میکند.
- نرخ نهایی (موفق / تمام حالات نهایی): ۳۶ تقسیم بر ۴۸ = ۷۵.۰٪. این اتفاق زمانی میافتد که دیگر وانمود نکنیم تایم-اوتها و توقفها رخ ندادهاند. ۱۵ درصد فقط با شمردن تمام اجراهایی که بد تمام شدهاند (نه فقط خطاهای تمیز)، ناپدید میشود.
- نرخ صادقانه (موفق / تمام اجراهای شروعشده): ۳۶ تقسیم بر ۵۰ = ۷۲.۰٪. این عدد حتی آن دو اجرای معلق در وضعیت RUNNING را هم میشمارد.
این شکاف ۱۸ درصدی همان «مالیات بقا» است. سه درصد آخر مربوط به اجراهایی است که هیچ رکورد نهایی ندارند و بیشترین اضطراب را ایجاد میکنند، زیرا اجرای بدون پایان، اجرای بدون نظارت است.
چرا مدیریت خطا راه حل نیست؟
بسیاری از مهندسان سعی میکنند با تقویت بلوکهای try/except یا پیادهسازی استراتژیهای بازپرسی (Retry) با عقبنشینی زمانی (Backoff)، یا ایجاد رکوردهای FAILED تمیزتر، این مشکل را حل کنند. اسپینوف چندین روز روی این موضوع کار کرد اما هیچکدام از این اقدامات عدد واقعی را تغییر نداد. دلیل آن ساده است: مشکل هرگز وضعیت FAILED نبود.
دلایل دقیق عدم موفقیت مدیریت خطا عبارتند از:
- ماهیت اجراهای FAILED: یک اجرای شکستخورده، «شهروند honest» دفتر کل است؛ یعنی استثنائی پرتاب کرده که قابل شکار بوده و همین حالا در لاگها، هشدارها و مخرج کسر حضور دارد.
- شکاف نامرئی: صیقل دادن مدیریت خطا فقط اجراهایی را بهبود میبخشد که خودشان را گزارش میدهند؛ کاری برای اجراهایی که هیچ حکم نهایی ندارند نمیکند.
- ناپدید شدن سیستمی: شما نمیتوانید برای گرهی (Node) که در میانه اجرا میمیرد و هیچ وضعیت نهایی نمینویسد،
try/exceptبنویسید. برای اجرای معلق، هیچ Stack Trace وجود ندارد، چون از دید کد، پروسه صرفاً از هستی ساقط شده است.
بنابراین باگ در مدیریت خطا نیست، بلکه در مخرج کسر است.
پیادهسازی و نردههای ایمنی
راه حل فنی یک تغییر تکخطی است: مخرج کسر را از «اجراهای تمامشده» به «اجراهای شروعشده» تغییر دهید. اگر جدول شما لحظه ایجاد اجرا یک ردیف میگیرد، مخرج کسر باید کل تعداد ردیفها باشد، بدون استثنا، شامل هر چیزی که هنوز RUNNING است.
با این حال، اسپینوف هشدار میدهد که برای جلوگیری از سوگیری بدبینانه، به یک «پنجره تثبیت» (Settled Window) نیاز دارید. اجرای شروع شده در ۹۰ ثانیه پیش که هنوز RUNNING است، شکست نیست؛ بلکه فقط «راست-سانور» (Right-censored) است، نه گمشده. شمردن آن به عنوان شکست در یک اسنپشات زنده، کارهای سالم در جریان را با موارد مرده یکی میکند. برای حل این موضوع:
- نرخها را روی بازههای زمانی محاسبه کنید که کاملاً تخلیه شدهاند.
- برای اجراهای انتقالی «گیت سنی» (Age-gate) بگذارید: هر اجرای جوانتر از یک آستانه خاص، بهجای شکست، «در انتظار» (Pending) تلقی شود.
برای جلوگیری از نقاط کور آینده، دو استراتژی نظارتی پیشنهاد میشود:
- هشدار بر اساس سن انتقالی: هرگاه یک اجرا سه برابر میانگین زمان معمول خود در وضعیت RUNNING ماند، هشدار دهید. چنین اجرای در واقع «مرده است و دروغ میگوید». این هشدار اغلب مشکلات واقعی بیشتری را نسبت به نرخ موفقیت پیدا میکند، زیرا مستقیماً به اجراهای پنهان اشاره میکند.
- نمایش هر دو مخرج: هر دو عدد «تعداد نهایی» و «تعداد شروعشده» را در داشبورد نمایش دهید. تباین بین «۹۴٪ از ۳۱۲ نهایی» و «۹۴٪ از ۱۰۴۰ شروعشده» دو جمله بسیار متفاوت هستند. وقتی این اعداد از هم فاصله میگیرند، این فاصله همان مالیات بقا است که با اعداد ساده نوشته شده است.
محدودیتها و تمایزها
باید توجه داشت که نرخ صادقانه همچنان یک «حد بالا» است و حقیقت مطلق نیست. اجرای کشته شده پیش از اولین خط لاگ — مانند خطای کمبود حافظه (OOM) در لحظه spawn یا سقوط زیرساختی — اصلاً ردیفی در جدول ندارد. بنابراین نرخ واقعی احتمالاً حتی از ۷۲.۰٪ هم کمتر است، زیرا نمیتوان چیزی را که هرگز نوشته نشده بشمارد.
ثانیاً، وضعیت SUCCEEDED بر اساس اعتماد پذیرفته شده است. اجرای بازگشتی با کد صفر که آرایهای خالی یا دادهای ناقص برمیگرداند، همچنان یک «برد» شمرده میشود. اصلاح مخرج کسر، تعریف موفقیت را اصلاح نمیکند. این یک دروازه جداگانه است؛ یک اجرا میتواند پاس شود اما دادههای زباله یا ردیفی که بهطور خاموش اشتباه است را تحویل دهد.
سوم، این موضوع اساساً با باگهای کیفیت داده متفاوت است. باگ کیفیت داده درباره «مقدار» داخل یک اجراست (مثل رتبه ۷ ستاره در سایتی که ۵ ستاره است)، اما این یک باگ در سطح جمعیت (Population-level) است درباره اینکه اجراها در کل ناوگان چگونه شمرده میشوند. یک اجرا میتواند با دادههای بینقص موفق شود، اما اگر همسایهاش در سکوت معلق بماند، نرخ کلی شما همچنان اشتباه است.
همچنین این مسئله با «مشکل ارزیابی» (Eval problem) متفاوت است. وقتی شما یک گیت رگرسیون برای پاسخ نهایی یک عامل مینویسید، کیفیت یک پاسخ را بر اساس یک روب ریک میسنجید. نرخ موفقیت میشمارد که اجراها چگونه تمام شدند، نه اینکه چه تولید کردند. شما میتوانید یک مجموعه ارزیابی بینقص داشته باشید، اما نرخ موفقیتتان همچنان توسط سوگیری بقا متورم باشد، زیرا ارزیابی فقط اجراهایی را میبیند که چیزی برای نمره دادن برگرداندهاند. این همان نقطه کور است، فقط یک طبقه بالاتر.
تحلیلها نشان میدهد با انتقال عاملها از چتهای ساده به اسکرپرهای پیچیده و طولانی، پایداری وضعیتهای «انتقالی» به اندازه دقت مدل اهمیت مییابد. برای توسعهدهندگان، این به معنای چرخش تمرکز از مهندسی پرامپت به مشاهدهپذیری زیرساخت (Infrastructure Observability) است. این رویکرد به ما کمک میکند تا هزینههای پنهانی مانند شاخص PDR و رانش تولید در کدهای تولید شده با هوش مصنوعی را نیز بهتر رصد کنیم. هر چیزی که شروع شده را بشمارید، نه فقط آنچه تمام شده است.
گام بعدی شما
- مخرج کسر داشبورد خود را از
completed_runsبهtotal_started_runsتغییر دهید. - برای تمام اجراهای RUNNING یک هشدار زمانی (SLA) تعریف کنید تا موارد معلق سریعاً شناسایی شوند.
- تفاوت میان نرخ موفقیت «نهایی» و «شروعشده» را به عنوان شاخص پایداری زیرساخت مانیتور کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو