
تصور کنید یک برنامهنویس بخواهد کل محیط توسعه و دیسک بوت خود را روی یک باکت S3 اجرا کند، بدون اینکه با تأخیرهای خردکننده مواجه شود. این اتفاق اکنون با ZeroFS ممکن شده است؛ ابزاری که مرز بین ذخیرهسازی «سرد» و دیسکهای «داغ» عملیاتی را میکشد.
طبق یک تحلیل فنی که در ۲ ژوئیه ۲۰۲۶ منتشر شد، یک درخواست رفتوبرگشتی معمولی در S3 بین ۵۰ تا ۳۰۰ میلیثانیه زمان میبرد. این تأخیر بالا باعث میشد ذخیرهسازی اشیاء (Object Storage) برای استفاده به عنوان درایو بوت اصلی یا محیط توسعه فعال عملاً بیاستفاده باشد. ZeroFS با ارائه باکتهای سازگار با S3 در قالب فایلسیستمهای POSIX (استاندارد متنی برای تعامل سیستمعامل با فایلها) از طریق پروتکلهای NFS و 9P، یا به صورت دستگاههای بلوکی خام (Block Devices) از طریق NBD، این مشکل را حل کرده است.
bسیاری از کاربران ابری با S3 مانند یک بایگانی رفتار میکنند؛ جایی برای راندن فایلها با این امید که هرگز نیاز نباشد آنها را فوراً بازخوانی کنند. در حالی که فایلسیستمهای سنتی به بلوکهایی با تأخیر کم نیاز دارند، S3 اشیایی با تأخیر زیاد ارائه میدهد. ZeroFS مانند یک لایه ترجمه پیشرفته عمل میکند و باکت را به عنوان یک پسزمینه با ساختار لاگی (Log-structured) مدیریت میکند.
ذخیرهساز ابری شما در این سیستم دیگر یک پوشه ساده از فایلها نیست، بلکه شبیه به یک دفتر کل عظیم و تغییرناپذیر است. به جای بازنویسی دادهها در جای خود، ZeroFS اطلاعات جدید را به عنوان اشیای تغییرناپذیر مینویسد. سپس یک فرآیند فشردهسازی در پسزمینه، فضای فایلهای حذفشده را بازپس میگیرد تا کارایی ذخیرهسازی بدون کاهش سرعت حفظ شود. همانطور که در تحلیل قبلی ما دربارهی بهینهسازی لایههای ذخیرهسازی توزیعشده اشاره کردیم، حذف بازنویسیهای مستقیم (In-place) کلید دستیابی به مقیاسپذیری در محیطهای ابری است.
معماری فنی و عملکرد
به نقل از مستندات فنی این پروژه، ZeroFS سازوکارهای متعددی را برای دور زدن کندی ذاتی ابر پیاده کرده است. بنچمارکهای عملکردی تفاوت شدیدی را بین S3 خام و ZeroFS نشان میدهند: خواندن تصادفی از یک کش گرم تنها ۱.۶ میکروثانیه زمان میبرد، در حالی که میانگین تأخیر نوشتنهای کوچک روی ۰.۸۳ میلیثانیه است.
- کش محلی (Local Caching): حافظه و کش دیسک قابل تنظیم، تأخیر خواندن را به میکروثانیهها میرساند و جریمه ۳۰۰ میلیثانیهای S3 را کاملاً دور میزند.
- قطعات تغییرناپذیر (Immutable Segments): دادهها در قطعات ۳۲ کیلوبایتی (extents) بستهبندی میشوند که درون اشیای تغییرناپذیر قرار میگیرند و توسط یک شاخص متادیتای مجزا آدرسدهی میشوند. هیچ دادهای در جای خود بازنویسی نمیشود، که این امر اجازه میدهد نسخههای خواندنی و نقاط بازرسی (Checkpoints) نمای ثابتی از باکت داشته باشند.
- رمزنگاری و فشردهسازی: هر بلوک پیش از آپلود با الگوریتم XChaCha20-Poly1305 رمزنگاری میشود. کلید داده با استفاده از یک کلید مشتق شده از رمز عبور کاربر توسط Argon2id بسته میشود. هیچ حالت بدون رمزنگاری در این سیستم وجود ندارد. دادهها با zstd یا lz4 فشرده میشوند؛ کدک در هنگام خواندن شناسایی میشود، بنابراین میتوان آن را بدون نیاز به مهاجرت دادهها تغییر داد.
- مقیاس: این سیستم به گونهای طراحی شده است که از نظر آدرسدهی بسیار گسترده باشد و با استفاده از فیلدهای ۶۴ بیتی inode و اندازه، از حداکثر حجم ۱۶ اگزابایت (EiB) پشتیبانی کند.
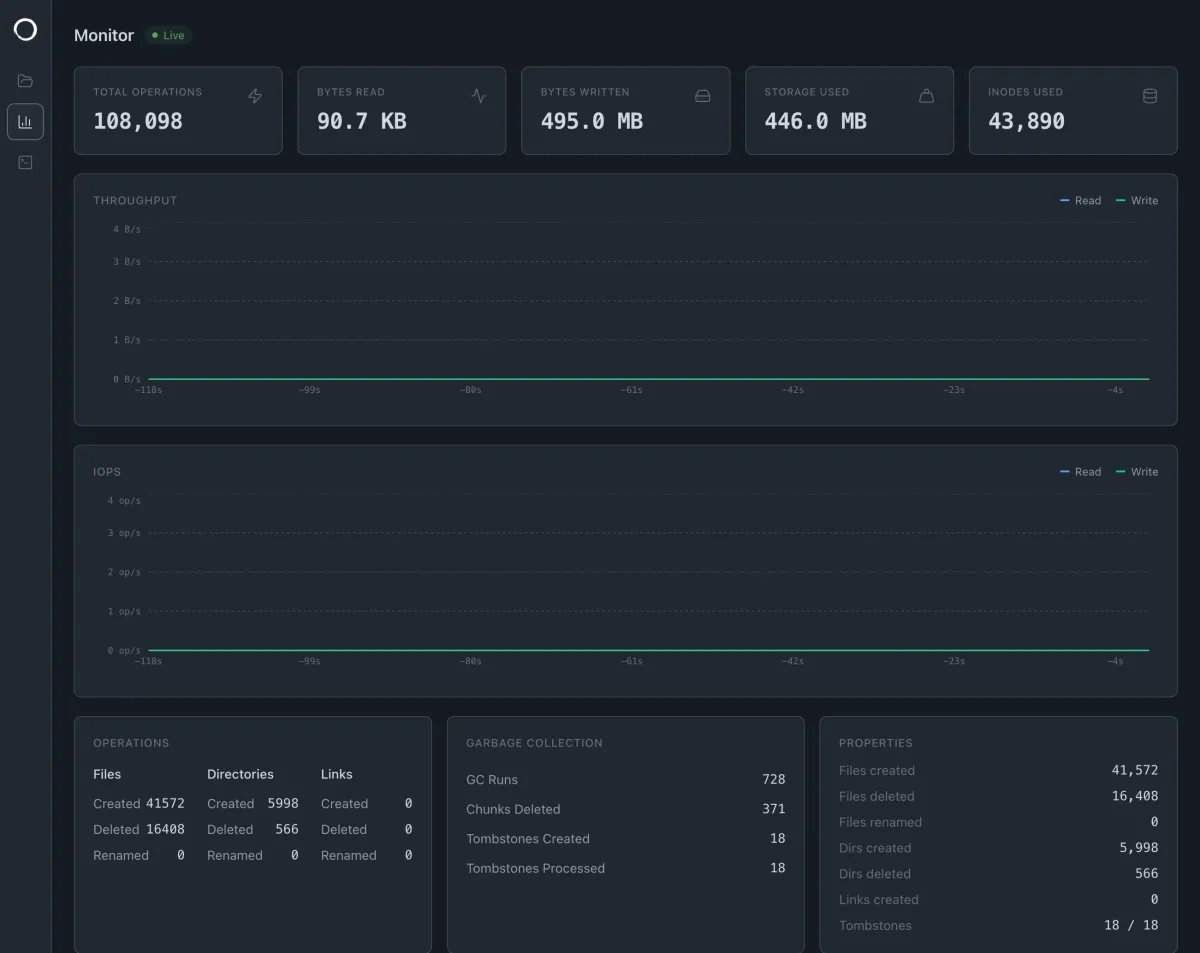
مجموعه تأییدیههای سختگیرانه
برای اثبات قابلیت اطمینان، ZeroFS یک خط لوله CI گسترده را روی هر تغییر اجرا میکند. این تستها در محیطهای CI عمومی اجرا شده و طیف وسیعی از حالتهای لبهای (edge cases) و حالتهای شکست را پوشش میدهند.
- تستهای POSIX و کرنل: مجموعه
pjdfstestدر هر تغییر برای هر پروتکل اجرا میشود تا دسترسیها، مالکیتها، لینکها و رفتار تغییر نام (rename) تأیید شود. پس از آن،xfstestsاجرا میگردد که همان مجموعهای است که برای تأیید فایلسیستمهای ext4 و XFS استفاده میشود. - تست فشار (Stress Testing): در این مرحله، CI کرنل لینوکس را روی نقاط اتصال NFS، 9P و FUSE با استفاده از دستور
make -j$(nproc)کامپایل میکند. این کار باعث میشود تعداد زیادی پردازش بهطور همزمان روی یک درخت فایل بنویسند. همچنین ازstress-ngبرای فشار آوردن به مانتهای زنده با مجموعهای کامل از عملیات مدیریت فایل شاملaccess،chdir،chmodوchownاستفاده میشود. - اعتبارسنجی سراسری: در گردشکار ZFS-test، سیستم CI یک استخر ZFS روی دستگاههای بلوکی ZeroFS میسازد و سورس کرنل لینوکس را روی آن استخراج میکند. در نهایت، یک عملیات ZFS scrub کامل انجام میشود که هیچ خطای چکسام (Checksum) گزارش نمیکند.
- بررسی مدلمحور: مجموعه
local-fsاز Jepsen، یک مانت 9P را با تاریخچهای از عملیات تصادفی هدایت میکند. یک «حالت کرش» سرور را در میانهی اجرا میکشد تا تأیید شود وضعیت بازیابی شده با آخرین دستورfsyncمطابقت دارد.
پشتیبانی از پروتکلهای متنوع
کاربران میتوانند از طریق سه رابط اصلی با ZeroFS تعامل داشته باشند. نکته مهم این است که هر سه سرور در یک پردازش واحد در فضای کاربر (Userspace) و روی یک باکت مشابه اجرا میشوند.
۱. NFS: سازگار با macOS، لینوکس، ویندوز و BSDها. این پروتکل از پشتیبانی داخلی سیستمعامل استفاده میکند، به این معنی که هیچ نرمافزار اضافهای در کلاینت نصب نمیشود. مثال: mount -t nfs 127.0.0.1:/ /mnt/zerofs.
۲. 9P: تطابق دقیقتری با POSIX نسبت به NFS دارد. در اینجا fsync تنها زمانی بازمیگردد که دادهها واقعاً به فضای ذخیرهسازی پایدار رسیده باشند. یک کلاینت FUSE bundled اجازه مانت کردن بدون دسترسی روت را میدهد: zerofs mount 127.0.0.1:5564 /mnt/zerofs.
۳. NBD (Network Block Device): اجازه میدهد باکت حاوی فایلسیستمهای ext4، استخرهای ZFS یا دیسکهای بوت ماشین مجازی (VM) باشد. دستگاههای جدید در زمان اجرا و بدون نیاز به ریاستارت سرور شناسایی میشوند. مثال: nbd-client 127.0.0.1 10809 /dev/nbd0 -N vol1.
ZeroFS با Amazon S3، Google Cloud Storage، Azure Blob، هر فضای ذخیرهسازی سازگار با S3 و حتی دیسکهای محلی سازگار است.
توزیع جغرافیایی و در دسترس بودن بالا
بر اساس بررسی منابع متعدد، ZeroFS رویکرد منحصربهفردی برای افزونگی جهانی ارائه میدهد. با استفاده از یک Mirror ZFS در سه منطقه مختلف S3 (مثلاً us-east با IP 10.0.1.5، eu-west با IP 10.0.2.5 و ap-southeast با IP 10.0.3.5)، کاربر میتواند استخری ایجاد کند که در تمام قارهها گسترده شده است.
از دید ZFS، اینها دیسکهای معمولی هستند. اگر یک منطقه از دسترس خارج شود، استخر ZFS تضعیف (Degrade) میشود اما دادهها از طریق دو منطقه دیگر در دسترس میمانند. این یعنی امکان پیکربندی zpool create global-pool mirror /dev/nbd0 /dev/nbd1 /dev/nbd2 برای دادههای حساس.
برای بارهای کاری حیاتی، ZeroFS قابلیتهای زیر را فراهم میکند:
- در دسترس بودن بالا (HA): یک Standby اختیاری، لیدر را روی همان باکت ردیابی میکند و نوشتنهایی را که لیدر تأیید کرده اما هنوز Flush نشدهاند نگه میدارد تا در هنگام Failover تمامی نوشتنهای تأیید شده حفظ شوند.
- fsync صادقانه: یک
fsyncموفق یعنی هر نوشتن در S3 بادوام (Durable) شده است. اگر در زمان Failover دادههای Flush نشده از دست بروند،fsyncبعدی به جای موفقیت کاذب، خطا برمیگرداند. - نسخههای خواندنی (Read Replicas): یک نمونه مینویسد و نسخههای Read-only تغییرات را بهطور خودکار اعمال کرده و در صورت تلاش برای نوشتن، خطای
EROFSمیدهند. - پشتیبانی از TRIM: شناسایی بخشهای آزاد در فایلسیستم یا zpool و حذف قطعات مربوطه. سپس فرآیند Compaction دادههای زنده را بازپایبندی کرده و قطعات خالی را از S3 حذف میکند تا هزینهها کاهش یابد.
- نقاط بازرسی (Checkpoints): ثبت وضعیت فایلسیستم در یک زمان خاص که میتواند در هنگام استارت-آپ بهصورت Read-only باز شود.
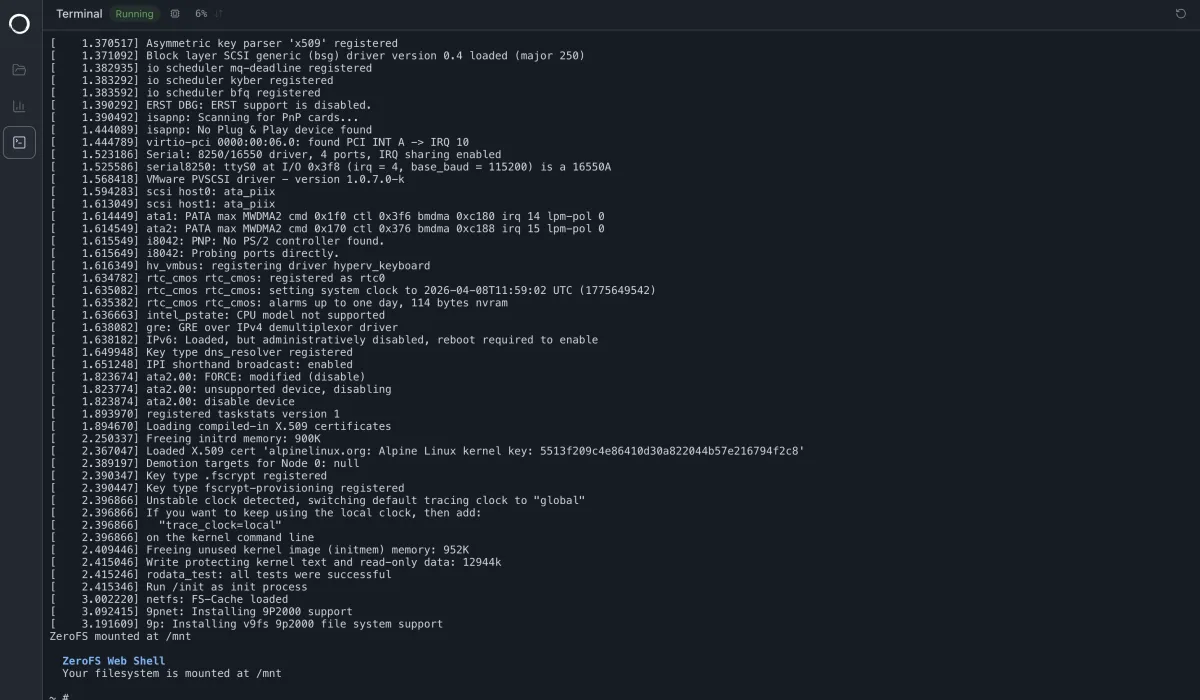
مدیریت یکپارچه
این سیستم شامل یک کنسول وب اختیاری است که از طریق بخش [servers.webui] فعال میشود. این پردازش واحد، یک مدیریت فایل (که 9P را روی WebSocket اجرا میکند)، یک داشبورد آماری (که دادهها را روی gRPC-web استریم میکند) و ترمینالی را فراهم میکند که یک ماشین مجازی لینوکسی را با روت روی مانت بوت میکند. این کنسول حتی از Drag-and-drop برای آپلود مستقیم فایلها و پوشهها به باکت از طریق 9P پشتیبانی میکند.
از منظر فنی، ZeroFS این پیشفرض را که S3 تنها یک فضای ذخیرهسازی «سرد» است، تغییر میدهد. با پیادهسازی موتور Log-structured و معنایی صادقانه برای fsync، یک ذخیرهساز ابری با تأخیر بالا را به یک دیسک اصلی بادوام، رمزنگاریشده و پرسرعت تبدیل میکند. کاربرد واقعی این سیستم در اینجا است: ابزار Rust میتواند ZeroFS را روی فایلسیستمی که خودِ ZeroFS سرویس میدهد کامپایل کند و کرنل لینوکس در ۱۶ ثانیه روی یک Volume NBD تحت ZFS کامپایل میشود.
گام بعدی شما
- اگر با دادههای حجیم در مناطق مختلف جغرافیایی سروکار دارید، مخزن گیتهاب ZeroFS را برای بررسی لیستهای استثنای عمومی برای معناییهای NFS/9P بررسی کنید.
- برای کاهش هزینههای S3 در پروژههای ذخیرهسازی، مکانیزم TRIM و Compaction این ابزار را روی محیطهای تست ارزیابی کنید.
- قابلیت ایجاد Mirror ZFS بین مناطق مختلف ابری را برای تست تابآوری دادهها در برابر قطعی منطقهای امتحان کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو