
باور شما به توانایی «استدلال» در هوش مصنوعی احتمالاً یک توهم آماری است. تصور کنید پیشرفتهترین مدلهای جهان در برابر معماهایی که یک کودک به راحتی حل میکند، کاملاً فلج شوند.
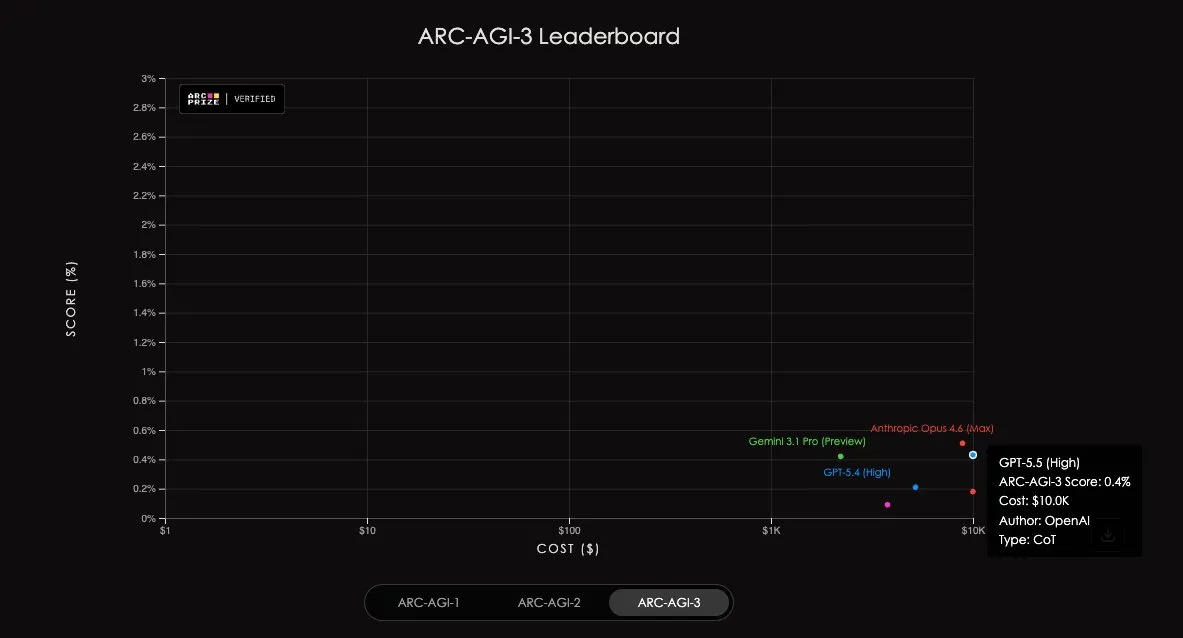
به نقل از تحلیل ۲ مه ۲۰۲۶ بنیاد ARC Prize، حتی پیشرفتهترین مدلهای لبه (Frontier Models) نمیتوانند وظایف انتزاعی سادهای را که برای انسانها بدیهی است، به سرانجام برسانند. پژوهشگران ۱۶۰ مورد از زنجیره تفکر (Chain-of-Thought) مدلهای GPT-5.5 متعلق به OpenAI و Opus 4.7 متعلق به Anthropic را در بنچمارک ARC-AGI-3 (که در اواخر مارس ۲۰۲۶ منتشر شد) بررسی کردند.
نتایج تکاندهنده است: هیچکدام از این مدلها نتوانستند از مرز ۱ درصد عبور کنند.
- GPT-5.5: امتیاز ۰.۴۳ درصد با هزینه تقریبی ۱۰,۰۰۰ دلار برای هر اجرا.
- Opus 4.7: امتیاز ۰.۱۸ درصد.
این بنیاد سه الگوی خطای سیستماتیک را شناسایی کرده است که دلیل این شکستهاست:
۱. درک محلی در برابر جهانی: مدلها اقدامات تکبهتک را میشناسند اما نمیتوانند یک مدل جهانی منسجم بسازند. برای مثال، Opus 4.7 تشخیص داد که در بازی cd82 باید رنگها را بچرخاند، اما هرگز این کار را به هدف نهایی متصل نکرد.

۲. قیاسهای نادرست: مدلها محیطهای ناشناخته را با دادههای آموزشی قدیمی اشتباه میگیرند. GPT-5.5 محیط ls20 را با بازی کلاسیک Breakout اشتباه گرفت و منابع خود را صرف فرضیاتی کرد که هیچ انسانی هرگز به آنها فکر نمیکند.

۳. موفقیت بدون درک: مدلها گاهی یک مرحله را تصادفی حل میکنند و سپس آن اتفاق تصادفی را به عنوان تایید یک نظریه غلط میپذیرند. در بازی ka59، مدل Opus 4.7 مرحله اول را با یک نظریه غلط درباره «تلهپورت» حل کرد و همین باور غلط را در مرحله دوم نیز تکرار کرد.

همانطور که در تحلیلهای پیشین ما دربارهی تفاوت مدلهای استدلالی و احتمالی اشاره کردیم، این نتایج نشان میدهد که تفاوت بنیادینی در نحوه شکست این دو مدل وجود دارد. Opus 4.7 به شدت روی یک نظریه (غالباً غلط) قفل میکند، در حالی که GPT-5.5 فرضیات گستردهتری میسازد اما در اجرای یک برنامه عملیاتی دقیق شکست میخورد.
این یافتهها با گزارشهای دیگر نیز همسو است. طبق گزارش پژوهشگران اپل، مدل استدلالی (Reasoning Model) با افزایش پیچیدگی مسئله، بهطور متناقضی کمتر استدلال میکند. همچنین یک مطالعه پزشکی نشان داد که مدلهای DeepSeek-R1 و o3-mini تنها با تغییر اندک در کلمات سوال، دچار خطا میشوند. این یعنی هوش مصنوعی زاینده (Generative AI) به جای ساخت مدلهای علی (Causal Models)، صرفاً به دنبال همبستگیهای آماری است.
اما این شکستها تنها بخشی از یک بحران عمیقتر در معماری ترنسفورمرهاست — در گزارش بعدی، اثر این بنبست بر آیندهی تراشههای استدلالی را بررسی میکنیم.
گام بعدی شما
- اگر توسعهدهنده هستید، به جای تکیه بر استدلال داخلی مدل، از روشهای مبنیسازی (Grounding) خارجی استفاده کنید.
- بنچمارک ARC-AGI را برای تست واقعی تواناییهای انتزاعی مدلهای خود به کار ببرید.
- منتظر معرفی معماریهای غیر-ترنسفورمری باشید که ادعای استدلال علی دارند.



گفتگو