اگر برای کاهش هزینههای عملیاتی به مدلهای میانرده تکیه کردهاید، باید بدانید که ارزانترین گزینه دیگر لزوماً بهصرفهترین نیست. طبق گزارش ۱ ژوئیه ۲۰۲۶ از Artificial Analysis، هزینه هر تسک در مدل Claude Sonnet 5 به ۲.۲۹ دلار رسیده است؛ عددی که حتی از مدل گرانتر Opus 4.8 با هزینه ۱.۹۷ دلار نیز بیشتر است.
این وضعیت نشان میدهد که قیمتهای اسمی توکنها اغلب هزینهی واقعی اجرای بارهای کاری هوش مصنوعی را میپوشانند. در واقع، ما با یک «خزش هزینههای پنهان» در استراتژی Anthropic روبرو هستیم. همانطور که در تحلیل قبلی ما دربارهی امنیت مدلهای بازمتن و دور زدن دیوارههای آتش توسط Claude Opus 4.7 اشاره کردیم، این شرکت پیش از این نیز با تغییر در توکنسازی (Tokenization) — یعنی تبدیل متن به تکههای کوچکی مثل برشهای یک کیک که مدل آنها را میخورد — تعداد توکنها را ۳۰٪ افزایش داد بدون اینکه قیمت رسمی را تغییر دهد.
بر اساس مستندات این گزارش، قیمت سونت ۵ همچنان ۳ دلار برای هر میلیون توکن ورودی و ۱۵ دلار برای هر میلیون توکن خروجی است. اما هزینه واقعی به دلیل دو عامل جهش کرده است:
- مصرف توکن: در تنظیمات حداکثری عملکرد، سونت ۵ حدود ۴۰٪ توکن خروجی بیشتری نسبت به سونت ۴.۶ مصرف میکند.
- رفتار عاملمحور: در محکهای AA-Briefcase و GDPval-AA، این مدل سه برابر بیشتر از نسل قبلی خود در حلقههای عامل (Agent) — شبیه به کارمندی که برای رسیدن به جواب، چندین بار مراحل مختلف را تکرار میکند — میچرخد. این در حالی است که در بررسیهای پیشین روی بنچمارک AA-Briefcase مشخص شد حتی پیشرفتهترین مدلها تنها در ۳٪ از وظایف پیچیده اداری موفق بودهاند.
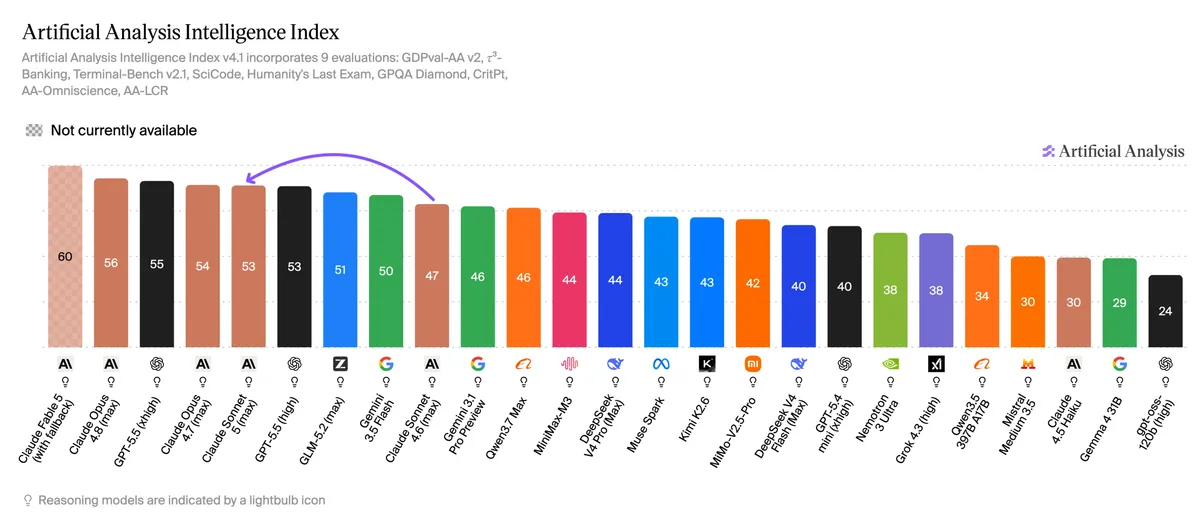
از نظر عملکردی، سونت ۵ در شاخص Intelligence Index v4.1 امتیاز ۵۳ را کسب کرد و با GPT-5.5 (high) در رتبه پنجم مشترک قرار گرفت. به نقل از همین گزارش، این مدل در آزمون Humanity's Last Exam ۱۰ امتیاز و در SciCode ۷ امتیاز رشد داشت. با این حال، در استدلالهای پیچیده هنوز ضعف دارد و در تست فیزیک CritPt تنها ۱۷٪ امتیاز گرفت.
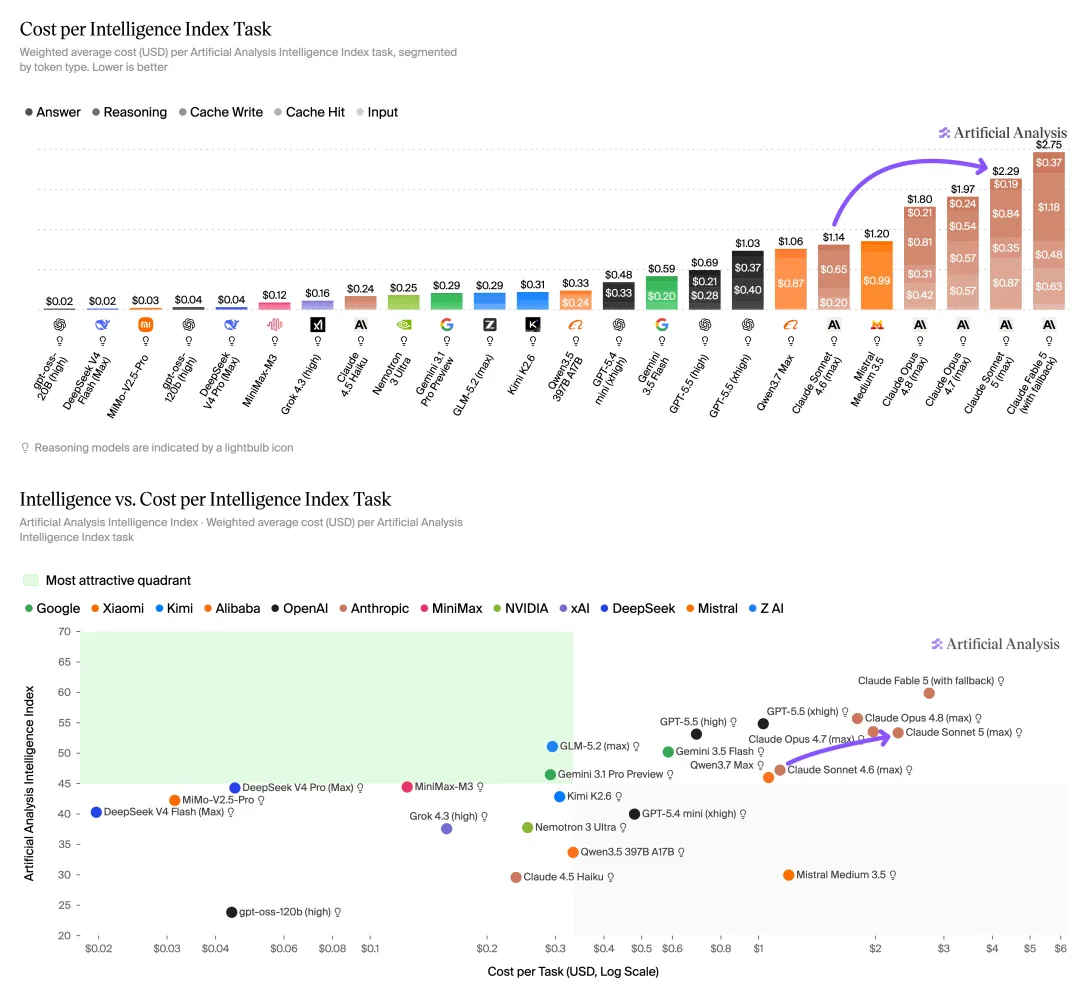
برای کاربران تجاری، این یعنی مدل میانرده دیگر جایگزینی اقتصادی برای کارهای پیچیده و عاملمحور (Agentic) نیست. در حالی که سونت ۵ در برخی تسکها از اپوس ۴.۸ بهتر عمل میکند، هزینه هر تسک نسبت به ۱.۲۰ دلار در سونت ۴.۶، تقریباً دو برابر شده است. این تضاد با ادعاهای اولیه دربارهی قدرت کدنویسی عاملمحور با هزینه کمتر در سونت ۵ که در زمان عرضه مطرح شده بود، بسیار چشمگیر است.
این عدم شفافیت، آنتروپیک را در برابر رقبای چینی تضعیف میکند. مدلهایی مثل Deepseek V4 Pro و GLM-5.2 در همان بخش میانرده، عملکردی رقابتی را با کسری از این هزینه ارائه میدهند. ارائهدهندگان صنعت باید به جای نرخ توکن، به سمت قیمتگذاری شفاف بر اساس «هزینه هر تسک استاندارد» حرکت کنند؛ زیرا در مدلهای خودمختار، تعداد توکنها متغیری ناپایدار است که قیمت واقعی نتیجه را پنهان میکند.
گام بعدی شما
- اگر از API آنتروپیک استفاده میکنید، هزینه واقعی هر تسک را با دادههای ورودی خود محاسبه کنید و به قیمت اسمی توکنها اعتماد نکنید.
- مدلهای رقیب چینی مانند Deepseek را برای تسکهای میانرده تست کنید تا توازن هزینه و کیفیت را بسنجید.
- در تنظیمات مدل، میزان توکنهای خروجی را محدود کنید تا از تورم هزینههای عاملمحور جلوگیری شود.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو