
تصور کنید یک دستیار هوشمند تمام ایمیلها، رشتهگفتارهای اسلک و صورتجلسات شما را میخواند تا یک گزارش جامع تهیه کند؛ اما در نهایت، جزئیات حیاتی را فراموش میکند. این واقعیت تلخی است که مدلهای فعلی هنوز از عهدهی کارهای تخصصی در مقیاس واقعی برنمیآیند.
طبق گزارشی که در ۱۹ ژوئن ۲۰۲۶ توسط Artificial Analysis منتشر شد، نتایج محک AA-Briefcase نشان میدهد که حتی برترین مدلها تنها ۳ درصد از وظایف پیچیده دانشبنیان را بهطور کامل حل میکنند. این شکاف عمیق، درست در زمانی رخ میدهد که صنعت بهشدت به سمت جریانهای کاری عاملمحور (Agentic) حرکت میکند. این چالشهای زیرساختی تأیید میکند که تکیه بر یک مدل واحد در معماریهای فعلی میتواند یک ریسک تجاری باشد و نیاز به لایههای مدیریتی پیشرفتهتر را بیش از پیش نمایان میکند.
همانطور که در تحلیل قبلی ما دربارهی محدودیتهای حافظه در مدلهای زبانی اشاره کردیم، اکثر کارهای حرفهای در یک پرامپت واحد خلاصه نمیشوند، بلکه نیازمند ترکیب دادههای پراکنده طی چندین هفته هستند.
شکاف عملکردی
بر اساس مستندات این محک، نتایج در زمینهی استدلال و اجرا تکاندهنده است:
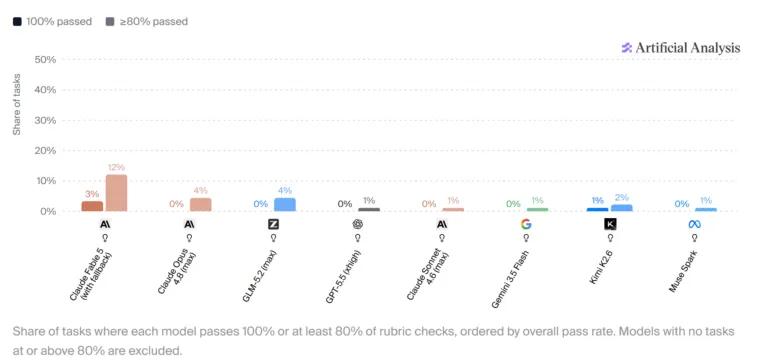
- Claude Fable 5 قویترین عملکرد را دارد، اما تنها در ۳٪ از وظایف توانسته تمام معیارهای ارزیابی را پاس کند.
- در ۳۱ مورد از ۹۱ وظیفهی آزمایش شده، هیچ مدلی نتوانست حتی به امتیاز ۵۰٪ برسد.
- تفاوت هزینه استنتاج بسیار شدید است: هزینه هر وظیفه از ۰.۰۴ دلار برای DeepSeek V4 Flash تا بیش از ۳۱ دلار برای Claude Fable 5 متغیر است (تفاضلی بیش از ۸۰۰ برابر). برای مدیریت این هزینههای سرسامآور در مقیاس صنعتی، راهکارهایی مانند Tokdiet تلاش میکنند تا هزینه استنتاج را بدون کاهش کیفیت کاهش دهند.
تکامل خطاها
به گزارش این تحلیل، ماهیت شکستها با تکامل مدلها تغییر کرده است. در حالی که مدلهای ضعیفتر در اجرای ابتدایی شکست میخورند — مثلاً فایلهای مرتبط را پیدا نمیکنند — مدلهای پیشرفتهتر «ساکتتر» شکست میخورند. این مدلها الزامات بدیهی را رعایت میکنند اما در درک ظرافتهای حیاتی که نیازمند پیوند دادن منابع مجزاست، ناکام میمانند.
برای متخصصان فنی، این یافتهها این فرض را که افزایش پنجره زمینه (Context Window) یا قدرت استدلال خام بهطور خودکار به صلاحیت حرفهای منجر میشود، به چالش میکشد. گلوگاه دیگر فقط حافظه نیست، بلکه توانایی حفظ دقت بالا در مجموعهدادههای پراکنده و چندمنبعی است؛ موضوعی که برتری دادههای اختصاصی بر ساختارهای صرفاً استدلالی را در حوزههای تخصصی به اثبات رسانده است.
گام بعدی شما
- اگر معمار سیستم هستید، بررسی کنید که آیا استراتژی بازیابی دادههای شما برای کاهش نرخ خطای ۹۷ درصدی بهینه است یا خیر.
- به جای تکیه بر قدرت استدلال خام، روی پیادهسازی سازوکارهایی برای اعتبارسنجی خروجی مدلها در پروژههای بلندمدت تمرکز کنید.
- رصد کنید که آیا نسل بعدی مدلهای استدلالی (Reasoning Models) میتوانند این شکاف را پر کنند یا راهکار در تغییر بنیادین متدهای بازیابی داده نهفته است.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell مراجعه کنید.



گفتگو