
تصور کنید بتوانید عملکرد یکی از پیشرفتهترین مدلهای جهان را با تنها ۶ درصد از هزینههای معمول به دست آورید. اگر فکر میکنید برای رسیدن به سطح GPT-5.5 حتماً به هزاران پردازنده گرافیکی و بودجههای نجومی نیاز است، باید نگاهی به استراتژی جدید بایدو بیندازید.
طبق اعلام بایدو (Baidu)، مدل جدید Ernie 5.1 در تاریخ ۹ مه ۲۰۲۶، با کسب ۱۲۲۳ امتیاز، رتبه چهارم جهانی را در جدول Arena Search به دست آورده است. این دستاورد در حالی رخ داده که هزینههای پیشآموزش (Pre-training) این مدل ۹۴ درصد کاهش یافته است. این خبر در زمانی منتشر میشود که صنعت هوش مصنوعی زاینده (Generative AI) — تشبیه روزمره: مثل کتابخانهداری که میلیاردها صفحه را خوانده و حالا با همان لحن کتابها جواب میدهد — از تمرکز بر مقیاس خام به سمت بهرهوری پایدار حرکت میکند.
همانطور که در تحلیلهای پیشین ما دربارهی قوانین مقیاسپذیری (Scaling Laws) اشاره کردیم، پیش از این تصور میشد افزایش قدرت مدلها مستقیماً با افزایش اندازه و هزینه گره خورده است. اما بایدو با تکیه بر مدل ۲.۴ تریلیون پارامتری Ernie 5.0 که در ژانویه ۲۰۲۶ عرضه شد، ثابت کرد که «کمحجمتر» بودن لزوماً به معنای «ضعیفتر» بودن نیست.
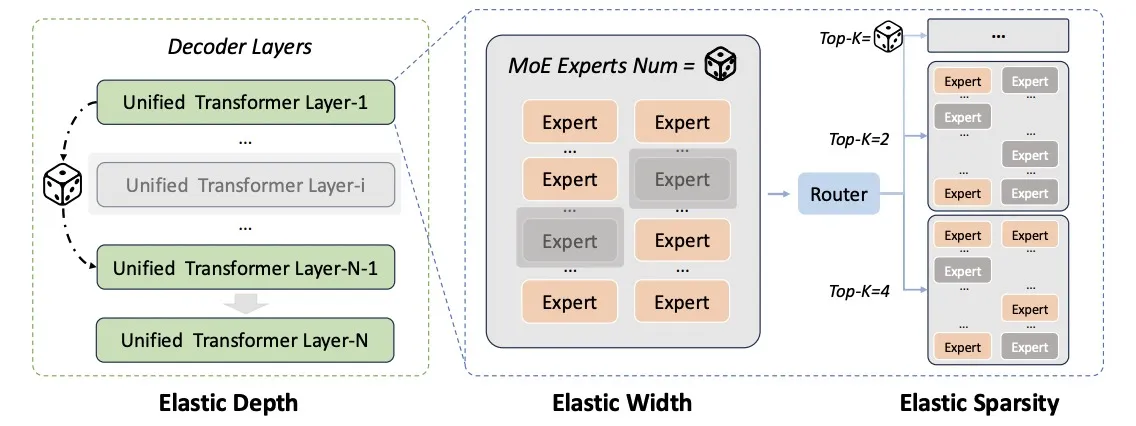
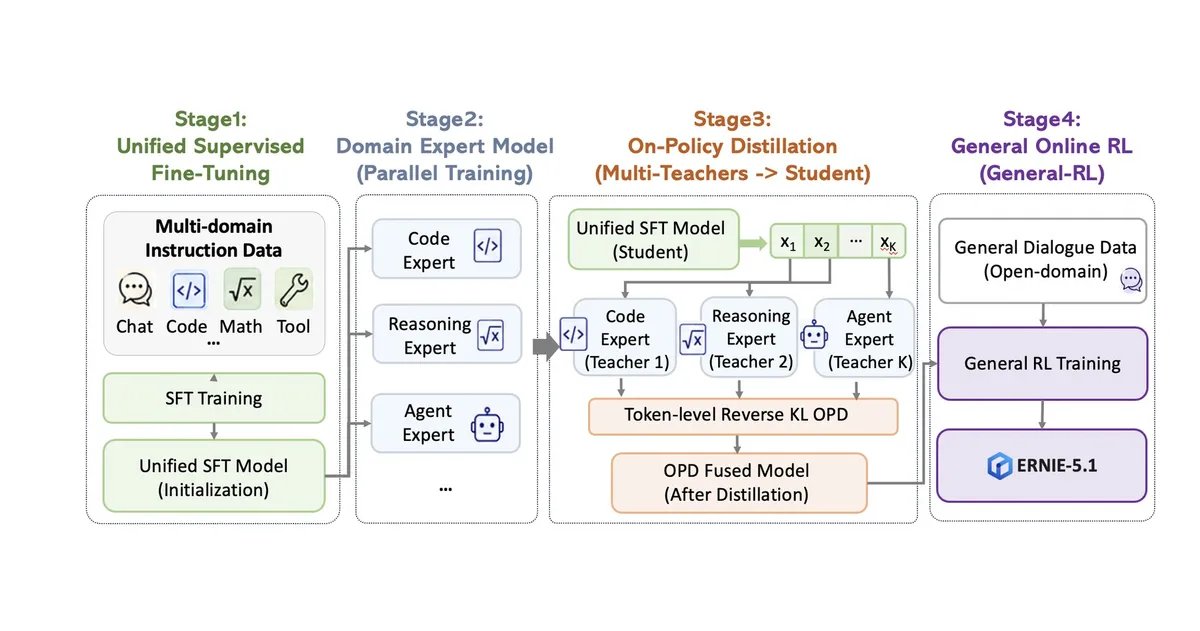
بر اساس مستندات فنی، این کاهش هزینه مدیون چارچوب آموزشی الاستیک «Once-For-All» است که اجازه میدهد خانوادهای از مدلها با عمق و تعداد متخصصان مختلف، تنها در یک دورهی آموزش بهینه شوند. همچنین بایدو سیستم یادگیری تقویتشده (RL) خود را بازنگری کرده و برای جلوگیری از «اثر الاکلنگی» (که در آن بهبود یک مهارت باعث افت مهارت دیگر میشود)، یک خط لوله چهار مرحلهای را پیاده کرده است:
- تنظیم دقیق (Fine-tuning) — تشبیه روزمره: مثل وقتی به یک پزشک عمومی، تخصص پوست میدهیم تا روی یک حوزه دقیق شود — نظارتی مشترک روی مجموعهدادههای گسترده.
- آموزش موازی متخصصان برای کدهای برنامهنویسی، استدلال و وظایف عاملمحور (Agentic).
- تقطیر (Distillation) — تشبیه روزمره: مثل خلاصهسازی یک کتاب قطور در یک برگه تقلب برای انتقال دانش به مدل کوچکتر — مدل دانشآموز برای تثبیت اطلاعات.
- یادگیری تقویتشده عمومی برای گفتگوهای آزاد و کارهای خلاقانه.
به نقل از گزارش the-decoder.com، در آزمونهای رودررو، Ernie 5.1 در وظایف مربوط به عامل (Agent) های خودمختار، مدل DeepSeek-V4-Pro را شکست داد و در بنچمارکهای GPQA و MMLU-Pro تقریباً با Gemini 3.1 Pro گوگل برابر شد.
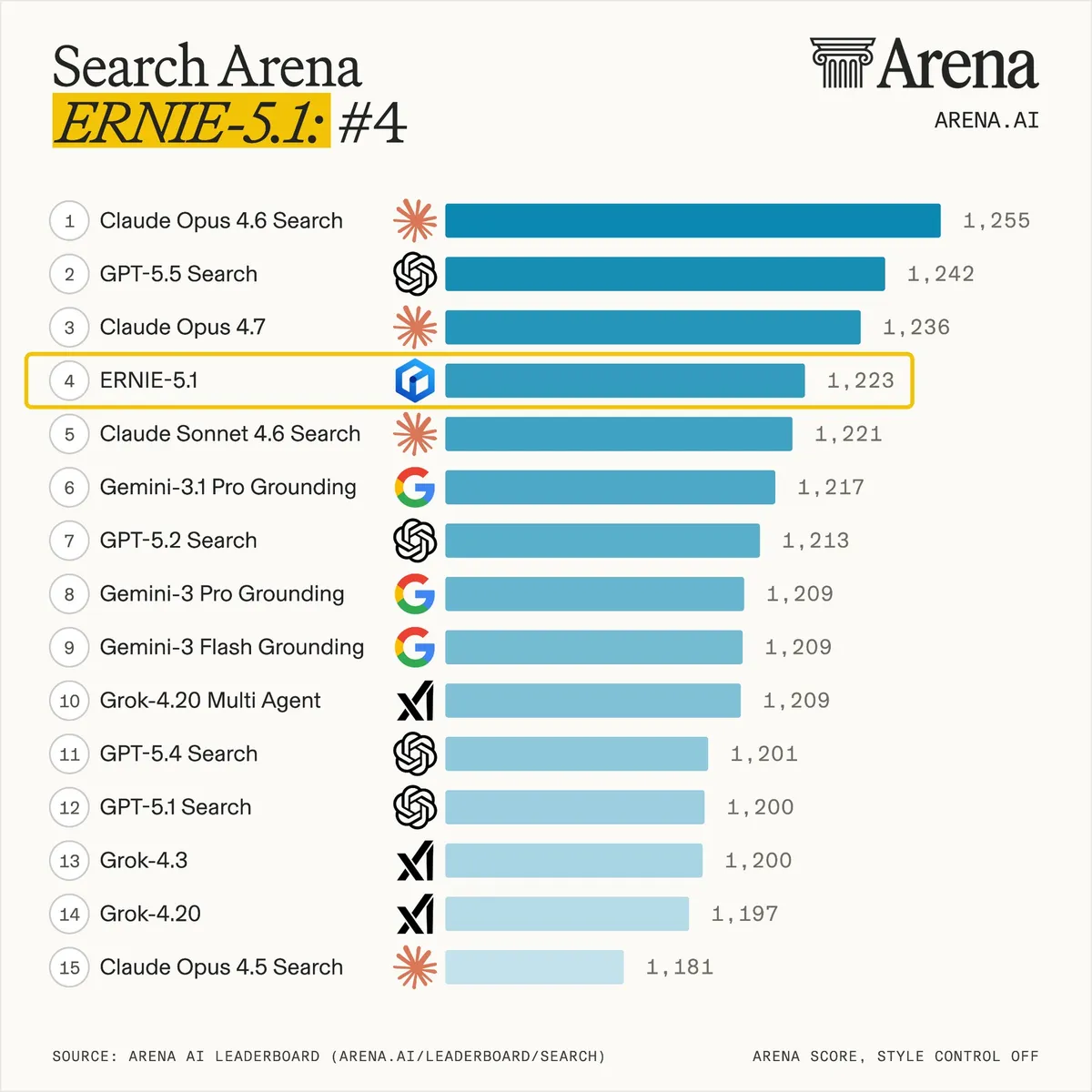
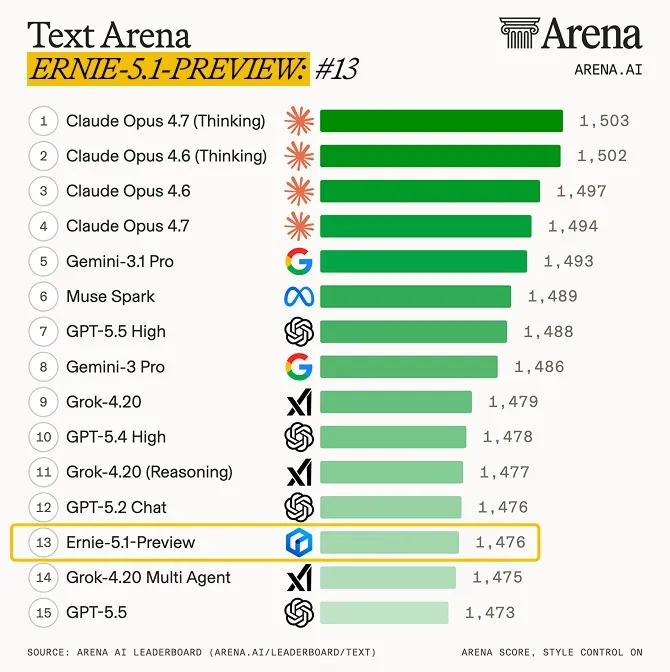
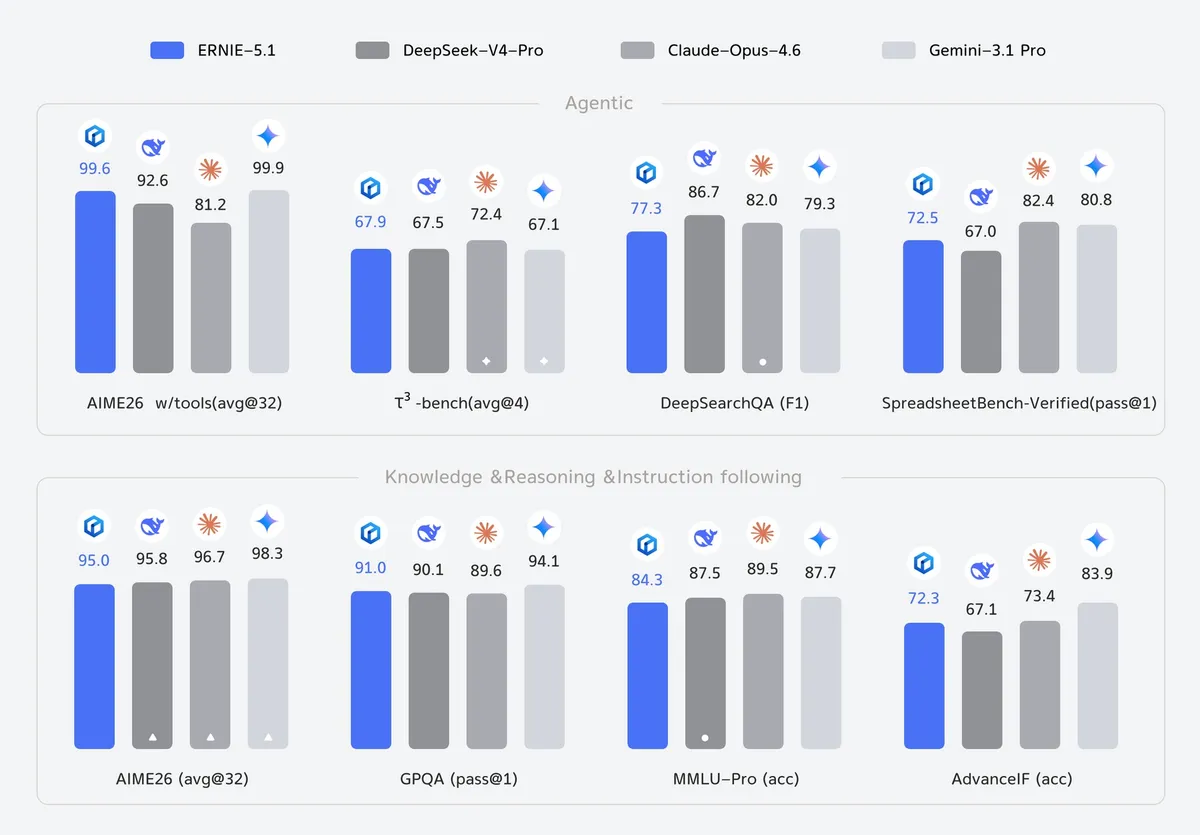
این تحول برای رهبران کسبوکار یک پیام روشن دارد: برنده میدان نبرد هوش مصنوعی دیگر کسی نیست که GPU بیشتری دارد، بلکه کسی است که معماری آموزشی بهینهتری طراحی میکند. بایدو با جدا کردن «قابلیتهای پیشرو» از «هزینههای محاسباتی سرسامآور»، بازی را تغییر داده است.
گام بعدی شما
- اگر توسعهدهنده هستید، بررسی کنید که آیا مدلهای کوچکتر با تقطیر دانش میتوانند جایگزین مدلهای گرانقیمت شما شوند یا خیر.
- استقرار این مدل در پلتفرمهای خلاقانه مانند Isekai Zero را دنبال کنید تا میزان واقعگرایی ادعاهای بایدو در دنیای واقعی مشخص شود.
- تحلیلهای مربوط به بهینهسازی حافظه در مدلهای زبانی را مطالعه کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهی تراشههای Blackwell و اثر آنها بر هزینه استنتاج (Inference) مراجعه کنید.



گفتگو