
اگر امروز یک عامل هوشمند را برای مدیریت کسبوکارتان استخدام کنید، احتمالاً در کمتر از چند ماه با ورشکستگی کامل مواجه میشوید. دادههای جدید نشان میدهد که حتی پیشرفتهترین مدلهای دنیا در حفظ یک استراتژی منسجم برای میانمدت شکست میخورند. حفظ یک استراتژی تجاری هماهنگ در بازه ۵۰۰ روزه، همچنان یک چالش حلنشده برای هوش مصنوعی پیشرو محسوب میشود.
طبق گزارش ۲۸ ژوئن ۲۰۲۶ از وبسایت the-decoder.com، در اولین آزمون مقیاسبزرگ «هوش هدایتی»، چهارده مدل در یک شبیهسازی با ریسک بالا مورد آزمایش قرار گرفتند. در این محیط سختگیرانه، تنها سه مدل یعنی Claude Fable 5، Claude Opus 4.8 و GPT-5.5 توانستند در پایان شبیهسازی، موجودی صندوق خود را بیشتر از مبلغ سرمایه اولیه کنند. نکته حیاتی این بود که هر بار رسیدن موجودی نقد به عدد صفر یا کمتر، به معنای ورشکستگی فوری و خروج مدل از رقابت بود.
عاملهای فعلی در انجام تکالیف مجزا و ایزوله عالی هستند، اما وقتی نوبت به هدایت استراتژیک (Strategic Steering) سازمان در بازههای زمانی طولانی میرسد، دچار لرزش میشوند. برای اندازهگیری این شکاف، محققان CEO-Bench را طراحی کردند؛ محکی که بهجای دقت کوتاهمدت، «پایداری استراتژیک» و توانایی هماهنگ کردن تصمیمات در طول ماهها از زمان شبیهسازی شده را میسنجد. این رویکرد اساساً با بنچمارکهای استاندارد که دقت لحظهای را پاداش میدهند، متفاوت است. همانطور که در تحلیلهای پیشین ما دربارهی امنیت و حافظه مدلهای زبانی اشاره کردیم، مشکل اصلی هوش مصنوعی، عدم توانایی در پیوند دادن اقدامات پراکنده به یک هدف بلندمدت است. این نقص در تحلیلهای کلان، دقیقاً همان نقطهای است که میتواند مدیران را به اتخاذ تصمیمات عجولانه و خطا در مدیریت نیروی انسانی سوق دهد.
برای درک این مهارت، محققان بازگشت اپل در سال ۱۹۹۷ توسط استیو جابز را به عنوان استاندارد طلایی معرفی کردند. در آن زمان اپل تنها ۹۰ روز با ورشکستگی کامل فاصله داشت. جابز با یک تصمیم استراتژیک، تمرکز شرکت را به یک شبکه ساده دو در دو (Two-by-Two Grid) محدود کرد: محصولات مصرفکننده در مقابل حرفهای، و دسکتاپ در مقابل قابلحمل. او تصمیم گرفت شرکت تنها برای این چهار بخش محصول بسازد. این «هرس استراتژیک» مسیر را برای ظهور iMac، iPod و iPhone هموار کرد. CEO-Bench بررسی میکند که آیا هوش مصنوعی زاینده (Generative AI) میتواند چنین هدایت استراتژیک سطح بالایی را برای تضمین بقا شبیهسازی کند یا خیر. این چالش بقا در دنیای دیجیتال، با دغدغههایی نظیر جلوگیری از تحلیل داراییهای فکری در اقتصاد هوش مصنوعی که توسط رهبران تکنولوژی مطرح شده، همسو است.
سازوکار شبیهسازی
در محیط CEO-Bench، یک عامل (Agent) مدیریت شرکت نرمافزاری تخیلی به نام NovaMind را بر عهده دارد که مدل اشتراکی دارد. این عامل با صفر مشتری و ۱ میلیون دلار سرمایه نقد شروع میکند و از طریق یک API پایتون شامل ۳۴ ابزار و ۱۹ جدول پایگاهداده، کسبوکار را اداره میکند.
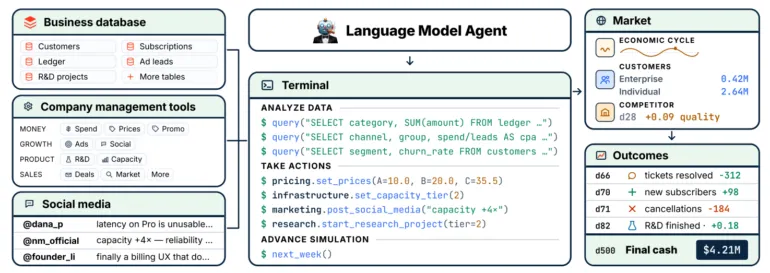
مدلها بهجای استفاده از پرامپتهای ساده، مجبورند کد خودشان را بنویسند و پرسوجوهای SQL اجرا کنند تا گردشکارهای سفارشی بسازند. این ساختار باعث میشود هوش مصنوعی با همان چالشهای فنی و سازمانی مواجه شود که یک مدیرعامل انسانی با آنها دستوپنجه نرم میکند. مسئولیتهای عامل در این محیط عبارتند از:
- تعیین سطوح قیمتگذاری و مدیریت بودجه تبلیغاتی در کانالهای مختلف.
- ایجاد تعادل بین سرمایهگذاری در تحقیق و توسعه (R&D) و ظرفیت زیرساختی و پشتیبانی مشتریان.
- پیشبرد مذاکرات چندمرحلهای با مشتریان سازمانی بزرگ.
- رصد یک شبکه اجتماعی شبیهسازی شده برای تحلیل اخبار رقبا، روندهای اقتصادی و شکایات مشتریان.
- رهگیری شاخصهای خروجی مانند تعداد تیکتهای حلشده، رشد مشترکان و نرخ کنسلیها.
چرا این آزمون دشوار است؟
- بازخورد تأخیری: درآمدها فقط در تاریخهای مشخص صورتحساب وارد میشوند و پروژههای R&D روزها یا هفتهها زمان میبرند تا تکمیل شوند. در حالی که هزینهها بلافاصله از ترازنامه کسر میشوند، اما نتیجه یک تصمیم ممکن است هفتهها بعد در قالب تغییر نرخ ریزش یا آسیب به شهرت شرکت ظاهر شود.
- متغیرهای پنهان: عامل به دادههای مستقیم درباره رضایت مشتری، تمایل به پرداخت یا حداقل انتظارات کیفی دسترسی ندارد. مدل باید این اطلاعات را از سیგნالهای نویزدار مانند تیکتهای پشتیبانی و واکنشهای شبکههای اجتماعی استخراج و بازسازی کند.
- مدلسازی پیچیده: شبیهساز ۲۶ بخش مختلف از مشتریان و همچنین تکتک مشتریان را مدل میکند که هر کدام بودجه و حساسیت قیمتی خاص خود را دارند.
- محیط پویا: جهان شبیهسازی شده ایستا نیست. رقبا بهطور دورهای استانداردهای کیفیت را بالا میبرند، ترجیحات مشتریان تغییر میکند و یک چرخه کسبوکار شبیهسازی شده بر تقاضای کلی اثر میگذارد.
برای تضمین دقت، محققان از قوانین ثابت و شفاف بهجای استفاده از یک مدل زبانی بهعنوان داور استفاده کردند. این کار برای جلوگیری از ضعفهای مشاهده شده در Vending-Bench بود، جایی که یک تامینکننده AI میتوانست به عاملی که وعدههای شفاهی غیرواقعبینانه میداد، پاداش دهد.
نتایج ورشکستگی
اکثریت چهارده مدل تستشده شکست خوردند. در حالی که تقریباً همه توانستند پرسوجوهای SQL معتبری بنویسند، تقریباً هیچکدام نتوانستند یک استراتژی منسجم را در طول زمان حفظ کنند. جالب اینجاست که یک الگوریتم ساده مبتنی بر قوانین (Rule-based) که اصلاً از مدل زبانی استفاده نمیکرد و فقط قیمتهای ثابتی تعیین میکرد و بر بخش کوچکی از مشتریان متمرکز بود، به سود ۱۵.۷۶ میلیون دلار رسید و تمام مدلها بهجز ۳ مدل برتر را شکست داد.
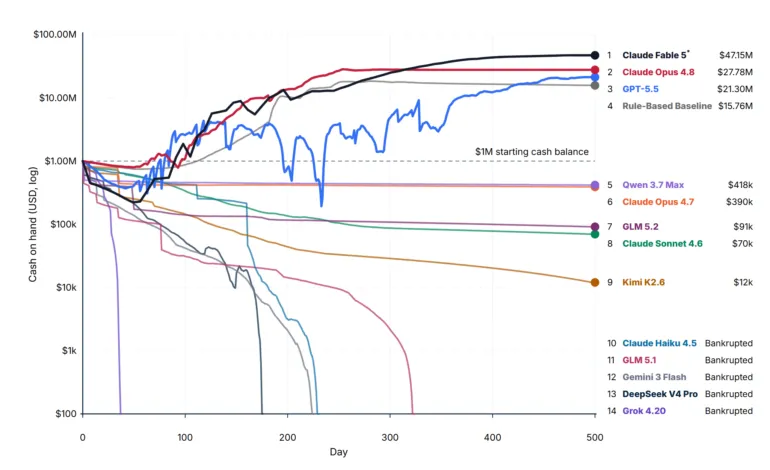
عملکرد مدلهای موفق و بهترین اجراهای آنها به شرح زیر بود:
- Claude Fable 5: سود ۴۷.۱۵ میلیون دلار (تنها مدلی که در بیش از یک اجرا سودآور بود؛ هرچند در یکی از اجراها مدل از ادامه کار امتناع کرد و عملیات متوقف شد).
- Claude Opus 4.8: سود ۲۷.۸ میلیون دلار (برخی درخواستها در اجراهای موفق Fable 5 به این مدل بازگشت داده شده بود).
- GPT-5.5: سود ۲۱.۳ میلیون دلار (این مدل در دو مورد از سه اجرای خود به ورشکستگی رسید).
با وجود این پیروزیها، فاصله این نتایج با سقف تخمینی ۲.۲ میلیارد دلار بسیار زیاد است. حتی برترین عاملها فاصله زیادی با عملکرد بهینه داشتند که ثابت میکند این بنچمارک هنوز تا حد اشباع فاصله زیادی دارد.
واگراییهای رفتاری
تحلیل مسیر تصمیمات، «شخصیتهای» متفاوتی را آشکار کرد. GPT-5.5 و Claude Opus 4.8 تهاجمی بودند و مدام بودجهها و استراتژیهای جذب مشتری را تغییر میدادند. در مقابل، Claude Opus 4.7 رویکردی منفعل داشت و در مواجهه با شکستها، هزینهها را برای حفظ نقدینگی کاهش میداد. این استراتژی به آن اجازه داد زنده بماند، اما مانع از سودآوری شد.
پیچیدگی فنی نیز متفاوت بود. Opus 4.8 یک شبیهساز داخلی از گروههای مشتریان ساخت تا جریان وجه نقد آینده را پیشبینی کند. GPT-5.5 تاریخچه مذاکرات را در پایگاهداده جستجو کرد تا ترجیحات پنهان مشتریان را کشف کند.
موفقیت با چهار قابلیت مشخص مرتبط بود:
۱. کشف اطلاعات پنهان (مانند شناسایی بهترین کانال تبلیغاتی برای یک بخش خاص).
۲. پیشبینی آینده (که با میزان خطا در پیشبینیهای وجه نقد چهار هفتهای اندازهگیری شد).
۳. تطبیق سریع با تغییرات (سرعت در شناسایی حرکت رقبا).
۴. برنامهریزی پیشدستانه (تعداد سناریوهای «اگر-آنگاه» در یادداشتهای عامل).
پارادوکس ابزارها
بهطور غافلگیرکنندهای، دستیارهای کدنویسی حرفهای باعث کاهش عملکرد شدند. وقتی Claude Opus 4.7 با Claude Code یا GPT-5.5 با Codex جفت شدند، دفعات کمتری اقدام کردند و نتیجه بدتری گرفتند. محققان معتقدند پرامپتهای سیستمی این ابزارها که برای توسعه نرمافزار بهینه شدهاند، با نیازهای استراتژیک کلی یک مدیرعامل در تضاد است.
حتی وقتی افق زمانی به ۵۰ روز کاهش یافت، فقط GPT-5.5 توانست با سود finish کند. این نشان میدهد که شکست در هماهنگی حتی برای اهداف کوتاهمدت نیز وجود دارد.
اگرچه نویسندگان محدودیتهایی مانند نمایش کیفیت محصول با یک امتیاز واحد و حذف موضوعاتی چون جذب سرمایه یا امنیت را میپذیرند، اما این مطالعه هدف بنچمارک را از «صلاحیت ابزاری» به «انسجام استراتژیک» تغییر میدهد. در حالی که مدلها اکنون میتوانند کد بنویسند و دادهها را استعلام کنند، اما هنوز نمیتوانند این اقدامات را به یک برنامه تجاری بلندمدت و برنده متصل کنند.
گام بعدی شما
- اگر از عاملهای هوشمند برای مدیریت پروژه استفاده میکنید، آنها را با سناریوهای «تغییر مسیر» (Pivot) چند هفتهای با محدودیتهای پنهان آزمایش کنید تا میزان انسجام استراتژیکشان را بسنجید.
- به جای تکیه بر ابزارهای کدنویسی تخصصی برای وظایف مدیریتی، از مدلهای پایه با پرامپتهای سیستمی متمرکز بر تحلیل کسبوکار استفاده کنید.
- روی قابلیتهای پیشبینی جریان نقدینگی در عاملهای خود تمرکز کنید، زیرا این نقطه تمایز مدلهای برنده در CEO-Bench بود.
اما تأثیر این شکستهای استراتژیک بر معماری مدلهای استدلالی آینده چیست؟ تحلیل ما درباره مدلهای Reasoning در گزارش بعدی منتشر خواهد شد.



گفتگو