
تصور کنید یک ربات انساننما یا دستیار صوتی هوشمند در یک پذیرایی شلوغ قرار دارد؛ در این لحظه، فاصله کاربر تا میکروفون و صدای پسزمینه، تفاوت میان یک پاسخ دقیق و یک کتیبه nonsensical است. اگر امروز بر اساس نتایج بنچمارکهای استاندارد تصمیم میگیرید، باید بدانید که دقت مدلهای شما در محیطهای واقعی احتمالاً چندین برابر پایینتر از تخمینهای فعلی است.
طبق گزارش Hugging Face، نرخ خطای کلمه (Word Error Rate یا WER) در مدلهای ارسالی برای میدانهای دور (Far-field)، بهطور مداوم چندین برابر بیشتر از نتایج میدانهای نزدیک است. این شکاف عمیق که توسط لیدربرد جدید FFASR آشکار شده است، ثابت میکند که نمرات بالا در بنچمارکهای «گفتار پاک»، عملاً قدرت پیشبینی عملکرد یک عامل صوتی در یک اتاق نشیمن واقعی را ندارند. تداخلات پیچیده میان بازگشت صدا (Reverberation)، نویز پسزمینه و فاصله میکروفون، افت عملکردی ایجاد میکند که معیارهای سنتی گفتار پاک قادر به ثبت آن نیستند. شکاف میان عملکرد در بنچمارکها و استقرار در دنیای واقعی، یکی از دیرپاترین و آزاردهندهترین چالشها در توسعه سیستمهای بازشناسی خودکار گفتار (ASR) بوده است.
امروزه رابطهای صوتی از هدفونها و گوشیهای هوشمند فراتر رفته و به رباتهای انساننما، عینکهای هوشمند و دستیارهای داخل خودرو منتقل شدهاند. ابزارهای تبدیل گفتار به متن برای اتاقهای کنفرانس و دستگاههای دست-آزاد (Hands-free) همگی با سرعت زیادی در حال پذیرش هستند. این دستگاهها در فضاهای پیچیده آکوستیکی عمل میکنند، جایی که میکروفون ممکن است در فاصلهای بین یک تا چندین متر از گوینده قرار داشته باشد. در حالی که استانداردهایی مثل LibriSpeech توانایی هستهای بازشناسی را میسنجند، اما اثر متقابل بازگشت صدا و نویز را که باعث شکست استقرار در دنیای واقعی میشود، کاملاً نادیده میگیرند. Modeli که در LibriSpeech یا سایر مجموعههای میدان نزدیک عملکرد خوبی دارد، ممکن است به محض ورود به محیطهای با آکوستیک واقعی، دچار افت شدید کیفیت شود.
در ۲۴ ژوئن ۲۰۲۶، بنچمارک FFASR (Far-Field ASR) توسط Treble Technologies و Hugging Face برای ایجاد یک روش استاندارد جهت سنجش این افت کیفیت عرضه شد. به نقل از مستندات huggingface.co، اگرچه پژوهشهای پیشینی مثل CHiME، URGENT و NOIZEUS به گفتارهای نویزی پرداخته بودند، اما جامعهی هوش مصنوعی به یک لیدربرد استاندارد، باز و بهروزرسانیشده نیاز داشت. اکنون جامعه ابزاری در اختیار دارد تا مدلها را در برابر اتاقهای شبیهسازیشدهای که بازتاب محیطی فیزیکی را تقلید میکنند، محک بزند. سازندگان این ابزار امیدوارند با نمایان کردن و قابل مقایسه کردن عملکرد در میدان دور، اولویت «استحکام آکوستیکی در دنیای واقعی» را در سراسر این حوزه افزایش دهند.
موتور شبیهسازی
این محک بر پایه موتور شبیهسازی ترکیبی اختصاصی Treble است. این سامانه یک حلکنندهی موجی (Wave-based solver) را برای فرکانسهای پایین تا متوسط با آکوستیک هندسی (Geometrical-acoustics) برای فرکانسهای بالا ترکیب میکند. این رویکرد پیچیده، پدیدههای فیزیکی نظیر پراکندگی (Diffraction)، پخش (Scattering)، تداخل (Interference) و رفتار مودی (Modal behavior) را که در شبیهسازهای سادهتر اغلب نادیده گرفته میشوند، بهدقت ثبت میکند. نتیجه، دادههای شبیهسازیشدهای است که با شرایط آکوستیک اندازهگیری شده در محیط واقعی تطابق نزدیکی دارند.
این خط لوله بر اساس مجموعهداده Treble10 توسعه یافته است که سال گذشته منتشر شد و زیربنای شبیهسازی را مستقر کرد و پاسخهای ضربهی اتاق (RIRs) میدان دور را برای پژوهشگران فراهم نمود. FFASR اکنون این زیربنا را به یک چارچوب رسمی با یک مجموعه آزمون محجوز (Held-out test set)، نرمالسازی سازگار و امتیازدهی خودکار تبدیل کرده است.
برای تضمین دقت و متدولوژی قابل اعتماد، تیم توسعه از یک مسیر اعتبارسنجی «شبیهسازی به واقعیت» (Sim-to-real) استفاده کرد. این کار شامل مقایسه دادههای «اندازهگیری شده در آزمایشگاه» با دادههای «شبیهسازی شده در آزمایشگاه» است تا تأیید شود که صوت مصنوعی دقیقاً با اندازهگیریهای فیزیکی واقعی همخوانی دارد. این متدولوژی تضمین میکند که بنچمارک قابل اعتماد و نماینده واقعی آکوستیک دنیای واقعی باشد.
شرایط بنچمارک و دادهها
مدلها در ۹ وضعیت ارزیابی میشوند. طبق اعلام تیم توسعه، تا ۲۲ ژوئن ۲۰۲۶، چهار وضعیت زیر تعیینکنندهی رتبهی اصلی هستند:
- میدان نزدیک (خشک): گفتار پاک که در یک اتاق بدون پژواک (Anechoic chamber) اندازهگیری شده و مشابه LibriSpeech است اما با حداقل بازگشت صدا.
- میدان دور با SNR بالا: سطوح نویز بالای ۱۴ دسیبل.
- میدان دور با SNR متوسط: سطوح نویز بین ۸ تا ۱۲ دسیبل.
- میدان دور با SNR پایین: سطوح نویز زیر ۶ دسیبل.
برای بصریسازی مقیاس این مشکل، لیدربرد نمونههایی را ارائه میدهد که در آن یک عبارت واحد، ابتدا بهصورت صوت خشک بدون پژواک، سپس با اعمال پاسخ ضربهی اتاق (Convolution) و در نهایت با افزودن نویز در هر سطح از SNR شنیده میشود. تفاوت میان ضبط خشک و وضعیت SNR پایین، به عنوان معیاری برای میزان تخریبی عمل میکند که این لیدربرد اندازهگیری میکند.
مجموعه آزمون شامل ۲,۰۰۰ نمونه گفتار بدون پژواک در ۱۴ اتاق کاملاً مبله است. برای جلوگیری از آلودگی مجموعه آزمون (Test-set contamination)، این دادههای صوتی در اختیار ارسالکنندگان قرار نمیگیرد. ابعاد این اتاقها بین ۲۰ تا ۴۷۰ متر مکعب متغیر است و محیطهای متنوعی را پوشش میدهند، از جمله:
- حمامها
- اتاقهای نشیمن همراه با راهروها
- دفاتر اداری
- کلاسهای درس
- فضاهای رستوران
هر صحنه آکوستیکی شامل یک گوینده هدف است که برای جلوگیری از اثرات محیط ضبط، در یک اتاق بدون پژواک ضبط شده است. همچنین تا سه منبع نویز در هر صحنه وجود دارد. هر صحنه ترکیبی از یک منبع نویز گذرا (Transient) مانند سرفه و یک منبع نویز مداوم (Continuous) مانند صدای همهمه تهویه HVAC در سه سطح SNR را شامل میشود.
علاوه بر این، لیدربرد شامل بخشهای «منابع متحرک» (Moving-source) است که در حال حاضر در وضعیت بتا قرار دارند. این بخشها صداهایی را ارزیابی میکنند که در آن گوینده به جای ایستا بودن، در حال حرکت است. این امر بازتابدهنده تغییرات هندسه آکوستیکی در کاربردهایی مانند رباتهای انساننما، گفتار داخل خودرو و دستیارهای صوتی موبایل است.
موازنه سرعت و دقت
عملکرد تنها با نرخ خطای کلمه (WER) سنجیده نمیشود. لیدربرد مقدار RTFx (ثانیههای صوتی بهازای هر ثانیه استنتاج) را برای هر مدل ارسالی بر روی GPU مدل NVIDIA L4 تحت شرایط یکسان گزارش میکند. این دادهها به توسعهدهندگان اجازه میدهد تا «جبهه پارتو» (Pareto front) دقت در برابر تأخیر (Latency) را مشاهده کنند.
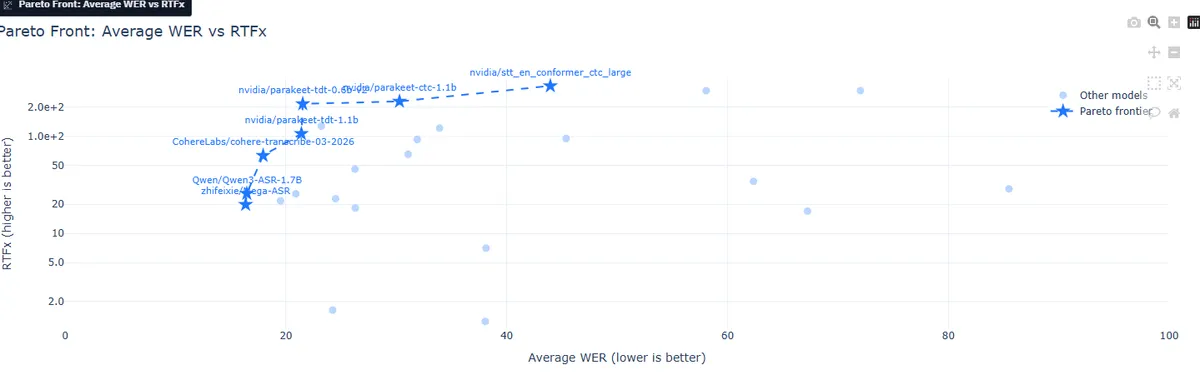
این بصریسازی به تیمها کمک میکند تا تصمیم بگیرند آیا باید یک مدل سریع اما کمی کمدقتتر را اولویت دهند یا مدلی کندتر اما بسیار استوار (Robust). بررسی این موازنه در برابر دقت میدان دور (به جای دقت گفتار پاک)، تصویر متفاوتی از تفاوتهای سیستمی ارائه میدهد. در حالی که ASR بر درک گفتار تمرکز دارد، در بخش تولید گفتار نیز بهینهسازی سرعت حیاتی است؛ برای نمونه رویکرد TLDR با فشردهسازی وصلهای توانست گلوگاههای حافظه و سرعت را در مدلهای TTS برطرف کند. دادهها طیف گستردهای از معماریهای فعلی ASR را آشکار میکند، از جمله نسخههای Whisper، IBM Granite Speech، Cohere Transcribe، سرهای CTC مدلهای Wav2Vec2 و HuBERT و همچنین SpeechBrain ASR.
ارسال مدل و انعطافپذیری
توسعهدهندگان میتوانند با مراجعه به تب Submit و وارد کردن شناسه مدل Hugging Face، مدل خود را ارسال کنند. ارزیابیها در سمت سرور و بر روی مجموعهدادههای محجوز انجام میشود. این مجموعه در هر وضعیت حدود ۸ ساعت صوت دارد و در سراسر فرآیند، نرمالسازی متنی سبک Whisper اعمال میشود.
برای پشتههای (Stacks) پیچیدهای که بهبود گفتار (Speech Enhancement) را با ASR ترکیب میکنند، گزینه «ارزیاب سفارشی» فراهم شده است. این امکان به تیمها اجازه میدهد تا پس از بازبینی توسط ناظر، تابع ارزیابی (evaluate()) خاص خود را از طریق Hub Jobs تعریف کنند. فیلد یادداشتهای ارسال (Submission notes) به توسعهدهندگان اجازه میدهد تا مراحل پیشپردازش خود را مستند کنند تا سایر پژوهشگران بتوانند نتایج را بهطور دقیق تفسیر کنند.
نقشه راه آینده
این چارچوب برای تکامل بر اساس نیازها و شکافهای جامعه طراحی شده است. مسیرهای آینده عبارتند از:
- سناریوهای چند-گوینده (Multi-talker): مدیریت محیطهایی که بیش از یک نفر همزمان فعال هستند و صحبت میکنند.
- پشتیبانی از آرایهی میکروفونی: ارزیابی رویکردهای تشکیل پرتو (Beamforming) و فیلترینگ فضایی.
- حذف اکو (Echo cancellation): تست دستگاههایی که همزمان با پخش صدا، به آن گوش میدهند.
برای توسعهدهندگان، گزارش تطبیقی WER خشک و میدان دور در تب Analysis حیاتیترین ویژگی است. این ابزار اجازه میدهد تشخیص دهند مدل واقعاً دقیق است یا صرفاً در برابر شرایط آکوستیک شکننده (Brittle) است. این تمایز تعیین میکند که تیم باید روی تنظیم دقیق (Fine-tuning) میدان دور، پیشپردازشهای تخصصی بهبود گفتار یا یک معماری سیستمی کاملاً متفاوت سرمایهگذاری کند. مسیر رشد لیدربرد FFASR بازتابدهنده نیازهای واقعی و پیشنهادات جامعه در انجمن FFASR خواهد بود.
گام بعدی شما
- اگر از مدلهای Whisper برای کاربردهای محیطی استفاده میکنید، نرخ خطای خود را در سطوح SNR زیر ۱۰ دسیبل مجدداً ارزیابی کنید.
- برای کاهش نرخ خطا در میدان دور، ترکیب لایههای بهبود گفتار (Speech Enhancement) را پیش از ورود داده به ASR تست کنید.
- در صورت توسعه سختافزارهای صوتی، دادههای پاسخ ضربه اتاق (RIR) از Treble10 را برای شبیهسازی محیطی به کار ببرید.
اما چالش اصلی، مدیریت همزمان چندین گوینده در محیطهای شلوغ است — در گزارشهای آتی، راهکارهای تفکیک منبع صوتی را بررسی خواهیم کرد.



گفتگو