
اگر بر اساس قیمت هر توکن تصمیم میگیرید، احتمالاً بودجهٔ استنتاج خود را اشتباه تخمین زدهاید. در حالی که تیترها فریاد میزنند GLM-5.2 نسبت به Claude Opus ارزانتر است، واقعیت این است که برای توسعهدهندگان، صرفهٔ اقتصادی واقعی در سطح ۳۰ تا ۳۵ درصد متوقف میشود.

این شکاف زمانی رخ میدهد که صنعت هوش مصنوعی به سمت جریانهای کاری عاملمحور (Agentic Workflows) حرکت میکند؛ جایی که حجم خروجی — و نه فقط قیمت واحد — تعیینکنندهٔ صورتحساب نهایی است. برای سازندگان فنی، جذابیت قیمت پایین هر توکن اغلب «مالیات توکن» را نادیده میگیرد که در فرآیند استدلال مدل پنهان شده است. طبق گزارشهای منتشر شده پس از عرضهٔ مدل در ۱۳ ژوئن ۲۰۲۶، برخی منابع ادعا کردند این مدل «یکششم هزینهٔ رقبا» است و گلدمن ساکس آن را «شوک جدید چینی به سیستم» نامید.
همانطور که در تحلیلهای پیشین ما دربارهٔ اقتصاد استنتاج مدلهای استدلالی اشاره کردیم، متریک «قیمت بهازای توکن» بهشدت گمراهکننده است. این عدد، پرگویی داخلی مدلهای استدلالی مدرن را میپوشاند. وقتی یک مدل برای رسیدن به نتیجه بیشتر «فکر» میکند، قیمت پایین هر واحد با افزایش تعداد توکنهای مورد نیاز برای تکمیل یک هدف واحد خنثی میشود.
به نقل از بنچمارک جامع ComputeLeap که در ۲۳ ژوئن ۲۰۲۶ منتشر شد، مدل GLM-5.2 بهطور متوسط ۴۳,۰۰۰ توکن خروجی برای هر تسک کدنویسی مصرف میکند. این رقم جهشی عظیم نسبت به ۲۶,۰۰۰ توکن در نسخهٔ پیشین (GLM-5.1) است. نکتهٔ کلیدی این است که حدود ۳۷,۰۰۰ توکن از این مقدار، توکنهای استدلالی داخلی هستند که مدل در آنها «بلند فکر میکند» و کاربر باید هزینه هر یک از آنها را بپردازد.
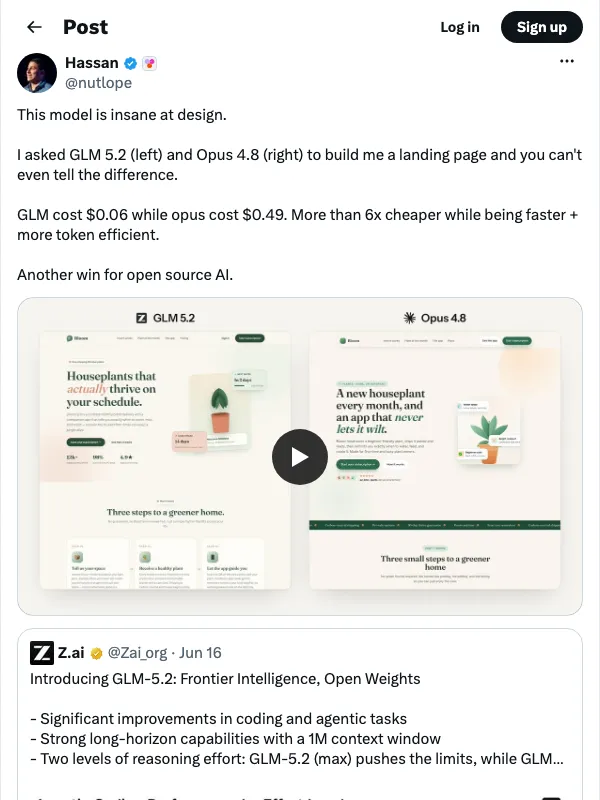
در رویارویی مستقیم، توانمندی مدل انکارناپذیر است. این مدل در بنچمارک FrontierSWE امتیاز ۷۴.۴ را کسب کرد که تقریباً با Claude Opus 4.8 (با امتیاز ۷۵.۱) برابر است و بهطور decisive از GPT-5.5 (با امتیاز ۷۲.۶) پیشی گرفت. اما در حالی که کیفیت واقعی است، روایت هزینهای مدل، دو-سوم ریاضیات را فراموش کرده است.
جزئیات قیمتگذاری ارائهدهندگان نشان میدهد که GLM-5.2 طی چند روز در بیش از ۱۱ ارائهدهنده استقرار یافت، اما قیمتها یکسان نیستند:
- GMI (FP8): ورودی ۱.۱۲ / خروجی ۳.۵۲ دلار (ترکیبی ۰.۷۲ دلار) با توان عملیاتی ۲۱۹ توکن در ثانیه.
- DeepInfra (FP8): ورودی ۱.۲۰ / خروجی ۴.۲۰ دلار (ترکیبی ۰.۸۰ دلار) با توان عملیاتی ۳۹ توکن در ثانیه.
- Wafer / OpenRouter: هر دو ۱.۲۰ دلار برای ورودی و ۴.۱۰ دلار برای خروجی (ترکیبی ۰.۷۹ دلار) ارائه میدهند.
- Z.ai (ارائهدهنده اصلی) / Fireworks AI: ورودی ۱.۴۰ / خروجی ۴.۴۰ دلار (ترکیبی ۰.۸۷ دلار).
برای مقایسه، غولهای آمریکایی قیمتهای بسیار بالاتری دارند: Claude Opus 4.8 در محدوده ۵/۲۵ دلار، GPT-5.5 در محدوده ۵/۳۰ دلار و Claude Fable 5 در محدوده ۵/۵۰ دلار عمل میکنند. با این حال، کاربران در Hacker News هشدار میدهند که ارائهدهندگان غیررسمی ممکن است مدلها را اشتباه پیکربندی کرده یا از کوانتش (Quantization) پنهانی برای کاهش هزینه استفاده کنند.
تحلیل هزینهٔ مؤثر برای ۱۰۰ تسک کدنویسی عاملمحور در روز نشان میدهد:
- GLM-5.2: ۰.۴۶ دلار بهازای هر تسک (۴۶ دلار روزانه). با قیمت ۴.۴۰ دلار بهازای هر میلیون توکن خروجی، یک تسک ۴۳ هزار توکنی بهتنهایی ۰.۱۹ دلار هزینه خروجی دارد.
- Claude Opus 4.8: ۰.۷۰ دلار بهازای هر تسک (۷۰ دلار روزانه).
- GPT-5.5: ۰.۷۳ دلار بهازای هر تسک (۷۳ دلار روزانه).

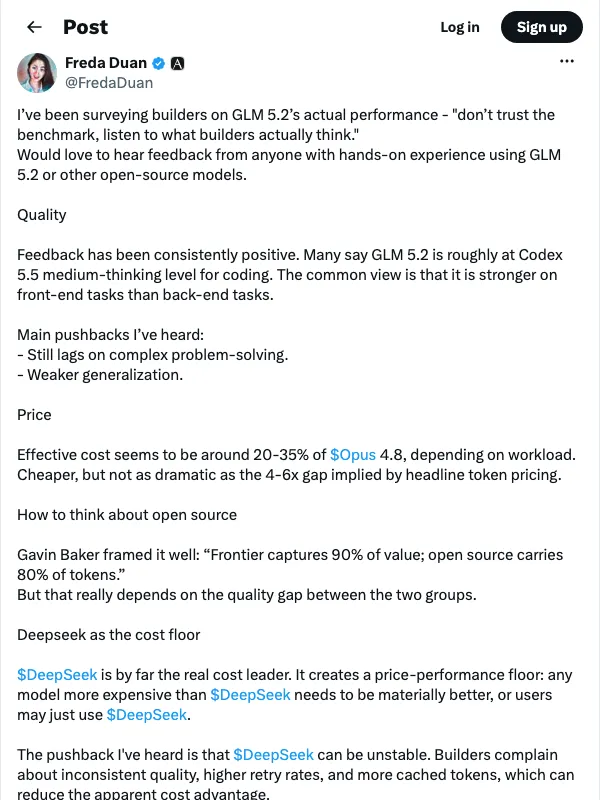
این دادهها تایید میکند که مزیت قیمتی ۶ برابری، یک توهم است. بر اساس یافتههای پژوهشگر Freda Duan، هزینههای واقعی برای کاربران تولیدی معمولاً بین ۲۰ تا ۳۵ درصد هزینهٔ Opus 4.8 است، زیرا نرخ ضربه به حافظه (Cache hit) و نرخ تکرار (Retry rate) بر صورتحساب نهایی تسلط دارد.
پایین بودن قیمت GLM-5.2 ناشی از بهرهوری معماری نیست، بلکه از سه مزیت ساختاری حاصل شده است: اول، حمایت دولتی؛ طبق گزارش RAND، مدلهای چینی بهدلیل زیرساختهای یارانهای، با یکششم تا یکچهارم هزینه سیستمهای آمریکایی اجرا میشوند. دوم، استراتژی جذب مشتری از طریق قیمتهای «پیشرو در ضرر»؛ برای مثال Hugging Face مدل را در هفتهٔ عرضه بهصورت رایگان میزبانی کرد. سوم، فشار صعودی قیمتها؛ شرکت Zhipu در فوریه ۲۰۲۶ قیمتها را ۳۰ درصد افزایش داد تا سرمایهگذاری در محاسبات را تامین کند.
برای متخصصان فنی، این موضوع معیار انتخاب مدل را تغییر میدهد. GLM-5.2 برای تسکهای حجیمِ محدود، حلقههای عاملمحور با حافظهٔ کش بالا و میزبانی شخصی با وزنهای باز (Open Weights) برنده است. همانطور که ناتان لمبرت اشاره کرد، این مدل یک «سرمایه بزرگ برای اقتصاد مدلهای باز» است، اما لزوماً برای هر صورتحساب، سود متناسبی ایجاد نمیکند.
Opus 4.8 همچنان برای بارهای کاری حساس به تأخیر و سختترین تسکهای بلندمدت که نرخ تکرار در آنها بالاست، ارزش خود را حفظ کرده است. معماری خود را بر اساس توانمندی مدل بسازید، اما بودجهتان را بر اساس ریاضیات تسک-محور تخمین بزنید.
گام بعدی شما
- اگر از مدلهای استدلالی استفاده میکنید، هزینه را بهجای توکن، بر اساس «میانگین توکن بهازای هر تسک» محاسبه کنید.
- برای کاهش هزینهها، روی بهینهسازی نرخ Cache hit در سیستمهای عاملمحور تمرکز کنید.
- در صورت نیاز به مدلهای باز، GLM-5.2 را برای تسکهای حجیم با محدوده مشخص تست کنید.
اما داستان سختافزاری این تحول حتی شگفتانگیزتر است — به تحلیل ما دربارهٔ تراشههای Blackwell مراجعه کنید.



گفتگو